本文转自雷锋网,如需转载请至雷锋网官网申请授权。
近日,麻省理工学院研究团队发表了一篇论文指控知名数据集ImageNet存在系统性Bug,该论文还被国际机器学习大会ICML2020接收。
同时,这篇论文名为《From ImageNet to Image Classification: Contextualizing Progress on Benchmarks》,也发表在了在预印论库arXiv上。
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
麻省理工研究团队之所以在ICML大会上介绍这项研究,是因为近期陷入的“Tiny Images”争议事件。
就在本月初,麻省理工学院(MIT)宣布永久删除了包含8000万张图像的Tiny Images数据集,并公开表示歉意。其原因是,有关研究人员发表了一篇论文指控Tiny ImageNet数据集存在多项危险标签,包括种族歧视、性别歧视、色情内容等,而且指控有理有据。
论文中表明,ImageNet在语义结构分析上,使用的WordNet名词,它包含了种族歧视等危险内容,同时,由于图像过小,数据量过大,并未手动对图像标签进行逐一核对,由此导致了问题的出现。
众所周知,知名数据集ImageNet也使用了WordNet用于语义结构分析,那么,ImageNet数据集是否也存在同样的问题?对此,麻省理工研究团队给出了答案。
ImageNet基准测试与实际不符
大规模ImageNet数据集的出现,可以说意味着机器学习深度变革的一个新起点。2009年,李飞飞领衔的研究团队在计算机视觉与识别模式大会(CVPR)上首次推出ImageNet,ImageNet数据集包含10000个分类,超过一百万个图像,数据量之大是此从未有过的。
正是因数据量大、质量高,ImageNet数据集被广泛用于预训练和基准测试。但是,麻省理工研究团队在最近的研究中却指出:
ImageNet存在明显的“系统标注问题”,导致其用作基准数据集时与实际情况并不一致。
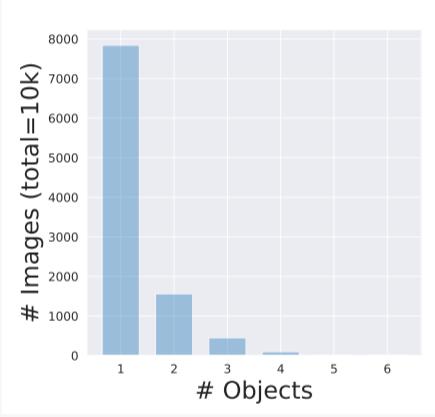
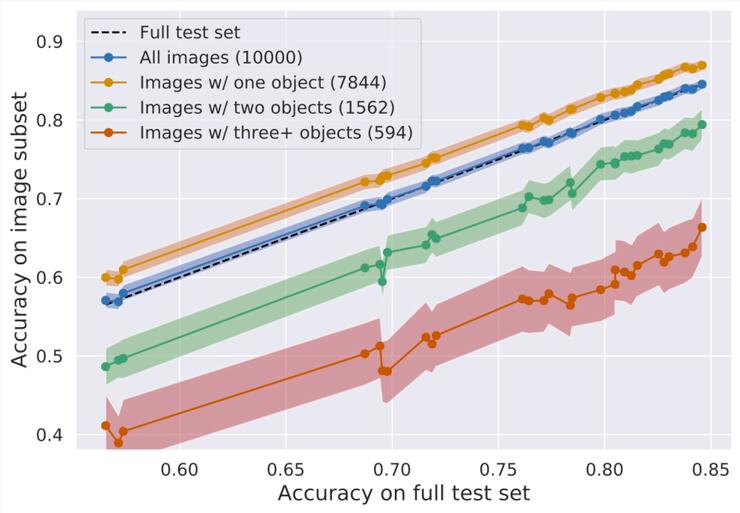
他们发现,ImageNet数据集中大约有20%的图像包含两个或更多的对象目标。
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
在通过对多个目标识别模型进行分析后,数据表明包含多个对象目标的照片会导致总体基准的准确性下降10%。
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
简单举个栗子:假如此图是ImageNet数据集中的一张高清图像,我们可以看到图片中不止包含了一个对象目标,有女孩、吉他和唱麦,而且图片的主目标应该是女孩。
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
但ImageNet的数据标签可能不是女孩,也可能是唱麦或者吉他,重要的是ImageNet只会标注一个标签,而这样就可能会导致ImageNet在目标识别中出现失误。
研究人员在论文中表明,
“总体而言,单个ImageNet标签可能不能总是捕获到ImageNet图像的主要表物体目标。但是,当我们进行培训和评估时,却将标签视为图像的根本事实,因此,这可能会导致ImageNet基准测试与现实世界中的对象识别任务之间出现不一致,而且这在模型执行和评估性能方面都是如此。”
看到这里你可能会疑惑,为什么不能准确对图像进行标记?其实问题的关键在于ImageNet所使用的标记工具WorldNet。
WordNet名词标记是关键
WordNet在1980年代由George Armitage Miller创立,被广泛用于数据集的收集和标记过程。简单的理解,ImageNet会根据WorldNet提供的名词和它的语义层次结构,在搜索引擎或者Flickr之类的网站进行图像搜索,作为数据集的初始来源。
当WordNet提供一个名词后,根据它设定的语音层次结构,ImageNet需要对该名词的父类节点同义词进行扩充,并以此作为搜索的关键词。比如“ whippet”分类名词(父类节点为:“dog”)的搜索还会包括“ whippet dog” 。
这类似于我们经常看到的“相关搜索”。为了进一步扩展图像池,数据集创建者还会使用多种语言进行了搜索。
但这里的重点是,对于每个检索到的图像已经确定了标签,如果该标签包含在数据集中,则将分配给该图像。也就是说,标签仅由用于相应搜索查询的WordNet节点给出。
而在这一过程中,WordNet的语义结构会将非主要目标的图像纳入数据集中,进而出现上文提到标记偏差。如论文中的数据显示,同一分类标签却出现了不同的物体目标。(如图)
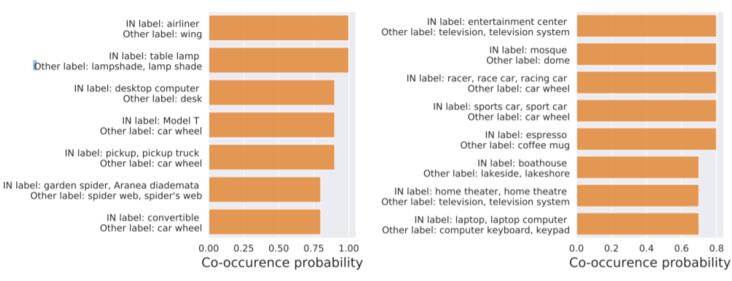
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
既然如此,那为什么WordNet名词还能够广泛应用于数据集创建过程中呢?
一方面是因为WorldNet可以完成大量数据的自动标记工作。我们知道,所有数据集在使用前都要先完成标记任务,而一个优秀的数据集规模又是很大的,如果全部手动标记,难度非常高,而WorldNet却可以很好的解决这一问题。
另一方面对于ImageNet而言,WordNet获取的只是初始数据标签,其准确性还需要通过相关模型进行再次验证。总体来讲,ImageNet数据集的创建过程,分为自动图像收集(automated data collection)和众包过滤(crowd-sourced filtering)两个阶段,而众包过滤就是所谓的审核阶段,它分为以下5个步骤:
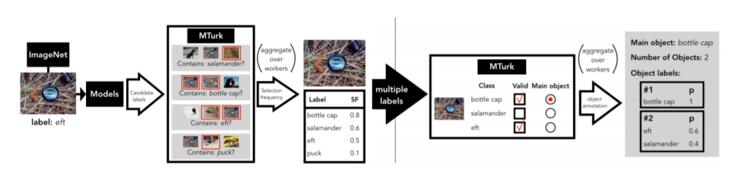
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
- 潜在标签(Candidate Labels):通过现有ImageNet图像标签与模型预测的前5个标签进行组合,获得每张图像的潜在标签。
- 选择高频率标签(Selection Frequency):通过Mechanical Turk(MTurk)平台,将潜在标签与注释内容对比,经过反复过滤循环后,出现频率最高的为最佳标签(一般少于5个)。
- CLASSIFY任务:给获得的少量多标签(Multiple labels)重新定义一组新的注释内容,根据注释信息为不同对象赋予标签,并确定一个主要对象的标签,这个过程称为CLASSIFY。
- 对象注释(Object Annotation):汇总以上训练后,获得更为细粒度的图像注释;
与原始ImageNet标签相比,经过众包过滤后生成的注释能够以更细粒度的方式表征图像的内容,但研究者发现,这些注释内容可能并没有达到期待的效果,如下图,CONTAINS任务会选择多个标签对图像有效,而对于70%的图像而言,注释选择的标签频率至少是ImageNet的原始标签的一半。
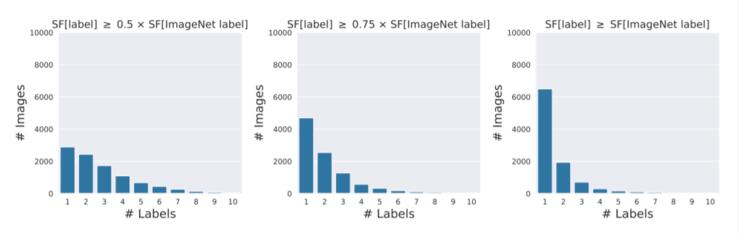
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet而且下图表明,尽管只感知到单个对象,它们也经常会选择多达10个类别标签。因此,对于单一目标的图像,ImageNet验证过程也无法得到准确的标签。
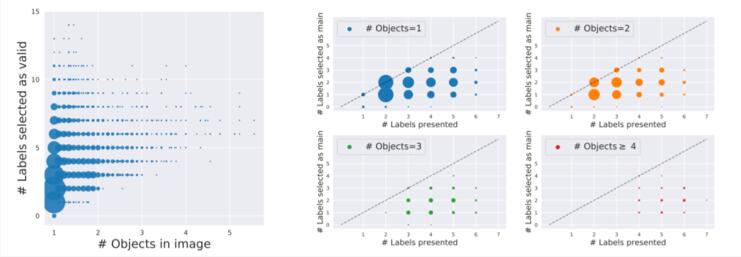
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug,祸端还是WordNet
因此,可以说图像标签在很大程度上依然取决于自动检索(WorldNet)过程,同时众包过滤的审查过程还有很大的提升空间。
对于未来如何优化数据集的创建任务,研究人员在论文中表明,我们认为开发注释流程,尤其是审查阶段以更好地捕获基本事实,同时保持可扩展性是未来研究的重要途径。”
涉嫌种族歧视,大规模数据集争议不断
作为人工智能技术的基础,数据集在诸多研究领域都有着广泛的使用场景,尤其是在计算机视觉领域。近些年,因数据集的使用引发的隐私泄露、种族歧视等问题接连不断,导致人工智能技术的发展备受争议。
除了近期麻省理工学院因涉嫌种族歧视而删除了包含8000张图像的Tiny Image数据外,此前,一款图像修复算法PULSE,在学术圈同样引起轩然大波。有网友发现,PULSE在修复马赛克图像时,将奥巴马的人脸图像变成了高分辨率的白人,这一事件引起了黑人网友的不满。
对此,图灵奖之父Lecun发表twitter称,训练结果存在种族偏见,是因为数据集本身带有偏见,工程师在使用过程中应该注意这一点。
今年因数据集而引发种族歧视事件颇多,而解决这些数据集争议,无非是从数据收集和标记阶段进行改进。研究人员称,对于大型数据集,理想的方法是按指定目标在全世界范围内收集图像,并让专家按确切类别进行手动筛选和标记。这里需要注意的是,非专家的人工标记也可能出现错误。
但从当前来看,这种方法非常不切实际。事实上,诸如ImageNet此类数据集均是从互联网搜索引擎抓取的图像,质量参差不齐,而图像审查不够严谨。同时大量数据的专家手动标记也很难实现。不过,如本次研究所称,可以通过技术进一步改善图像自动审查的过程来提高数据集的质量。
此外,目前学术界已经越来越关注数据集相关缺陷问题,在本月初计算机语言协会(ACL)还重点讨论了这一问题。