本文转载自公众号“读芯术”(ID:AI_Discovery)。
很多人都曾经至少有一次利用数据库为应用程序生成ID的经历。但事实上,这种做法在开发应用程序过程中是大错特错,使用自动递增的整数ID会则错得更加离谱。
是时候彻底摆脱这个不良行为了。
可以肯定的是,这会与你在101 college平台关系数据课上学到的知识,以及你在youtube平台上观看的无数个如何用TerribleIds ()创建表格的视频形成鲜明对比。
用数据库生成应用ID会造成什么问题?
首先,最大的问题是你把应用程序中一个极其重要的部分授权给第三方软件,在授权第三方责任时,你已经失去了对这个应用程序的掌控权。
其次,在设计实体类时,你可能会使用不恰当的方法,因为你想让它与一个永久框架更兼容,比如说C# .NET中的实体框架。初级程序员犯的最严重的一个错误就是使用public Id setter方法来设置ID。
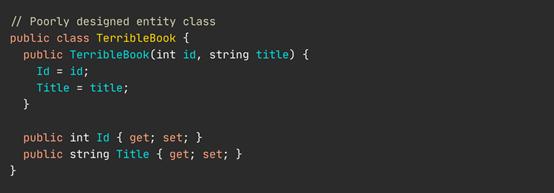
第三,你突然要依靠第三方来给实体提供ID,这会把原本不复杂的单元测试变得复杂。假设你已经发现使用public ID setter本质上是一个严重的错误,而你又不想通过调用代码来设置ID。创建的类看起来会如下所示:
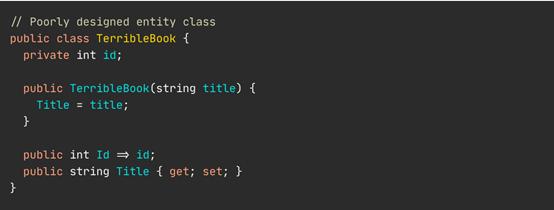
你选择的ORM仍然可以通过反射来设置id字段。要知道,有反射存在就没有什么是真正安全的。
但该如何对此进行单元测试?实例化时将id字段设置为0。实例化多个TerribleBook会出现身份冲突情况,因为现在不止一个TerribleBook具有相同的ID,即便他们代表两个不同的实体。
如何生成更合适的ID并追回授权?
方法其实非常简单,看下面的代码:
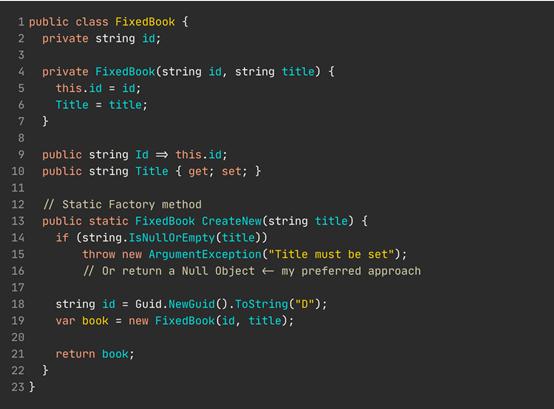
不是人人都能注意到TerribleBook到FixedBook之间的转变,所以请认真阅读这段代码。
首先,ID由整数变成字符串,这样可以更好地实现伸缩性,但一定要限制数据库中字段的长度。永远不要对已知长度的字段使用 VARCHAR(MAX)——它会占用内存。
然后将构造函数设为私有,并使用静态工厂方法实例化新对象。这样可以从调用者中抽象出实例化逻辑,甚至为我们提供了使用多态的机会——我们可能想返回某个Null对象而不是抛出。
注意,虽仍然把id当作构造函数参数,但是ID的生成和提供是由我们来决定的(在第18行),而不是数据库。
Guid.NewGuid()。ToString("D")只能确保获得连字符格式的GUID。笔者喜欢用GUID,但是你可以自由构建自己的ID,无论哪种ID都可以满足你的业务和应用程序需求。
现在,我们拿回了控制权。
图源:unsplash
或许你会说:“但是实体将不再按顺序存储!”这完全正确,但没什么好担心的。初级开发人员喜欢有序存储实体,即便这通常对业务不会产生任何影响。如果确实需要按顺序存储内容,只需创建一个日期时间列即可。