Matplotlib 通常被认为是在 Python 中创建可视化的最简单方法,它构成了许多其他绘图库(如 Seaborn)的基础。今天我们来讲一下创建可视化的另一个方法,Pands。直接从Pandas绘制有许多优点:
- 它的速度更快 — 代码行更少,需要编写的代码更少,需要重新加载的库更少。可视化对于数据分析至关重要,因此没有理由拒绝尝试加快生成良好可视化的过程。此外,Pandas在我们想要它绘制的图中做很多推论,因此它可以在很多情况下可视化我们想要的,而无需显式声明它们。
- 直接整合许多涉及系列和数据帧的方便数据操作功能(如不同的分机和滚动方式)更容易。
- 实际上,直接从Pandas那里创建地块更容易在条形图、堆叠条形图和水平条形图之间转换只是更改参数值的问题。创建子图并操作子图也只是几个字符。Pandas在可视化方面承担着许多艰苦的工作。
而对于技术:Pandas的绘图运行在matplotlib基础设施,并加载其他matplotlib项目或参数在Pandas创建的图形的顶部可以改善它。相反,Pandas只是提供了一个方便和更直接的界面,将数据连接到可视化。例如,以下数据帧随机生成,包含四列和十行。

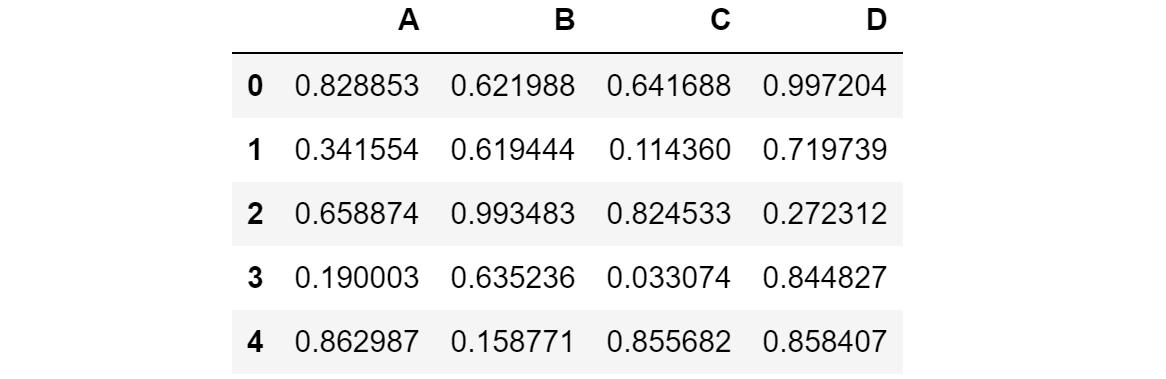
只需用data.plot.bar()来绘制每行每列的值,就可以用data来替换数据帧的名称。请注意,在语句之后添加分号 () 会从输出其他打印(例如 , )中删除单元格。
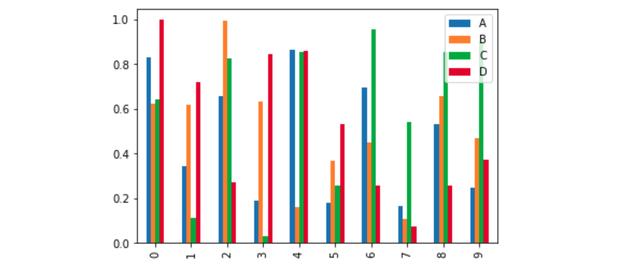
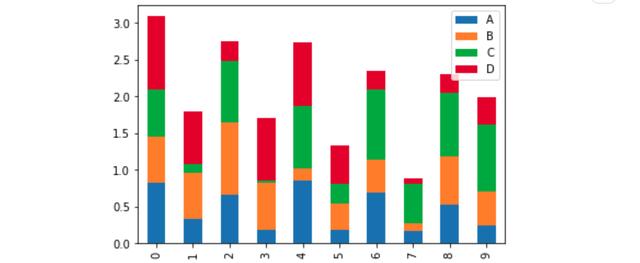
或者,尝试添加一个参数stacked=True,这是直接从数据源创建堆叠条形图的非常简单的方法。
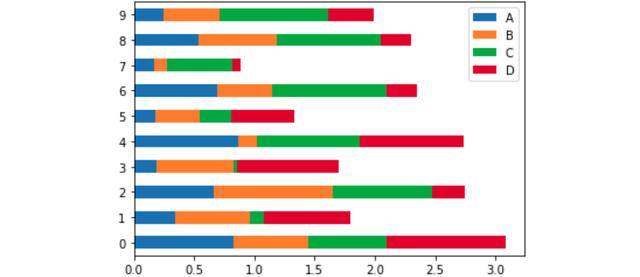
或者,尝试使用barhdata.plot.barh(stacked=True)绘制水平条,所有这些变体只需一行代码就可以轻松创建,因为它们与数据建立了直接流。
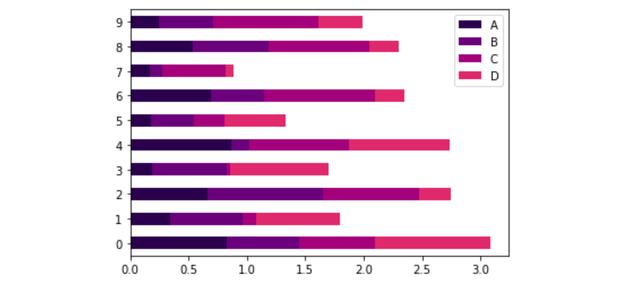
可以通过在绘图的代码(sns.set_palette(‘magma’))之前添加来更改绘图的常规调色板。或者,也可以将颜色贴图参数传递到绘图中。
显示此类数据的另一种方法是使用data.plot.area()的区域图。
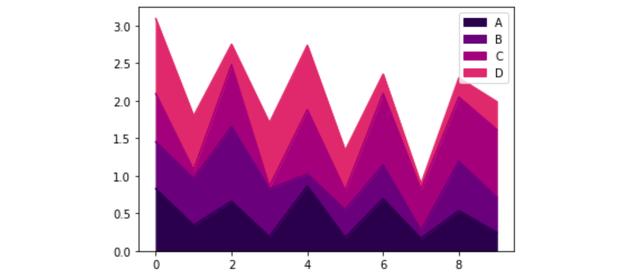
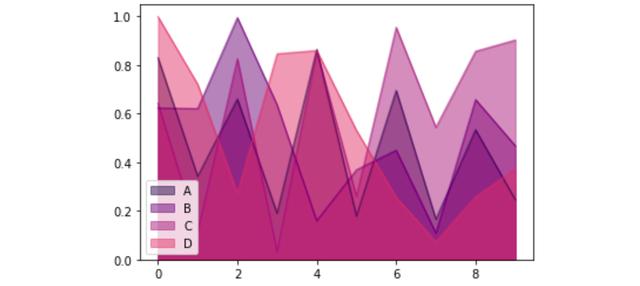
代码中的参数可以像通常使用 matplotlib 或海生模型那样进行调整。在data.plot.area(stacked=False)的情况下,参数(透明度)默认设置为 0.5,但可以手动调整。
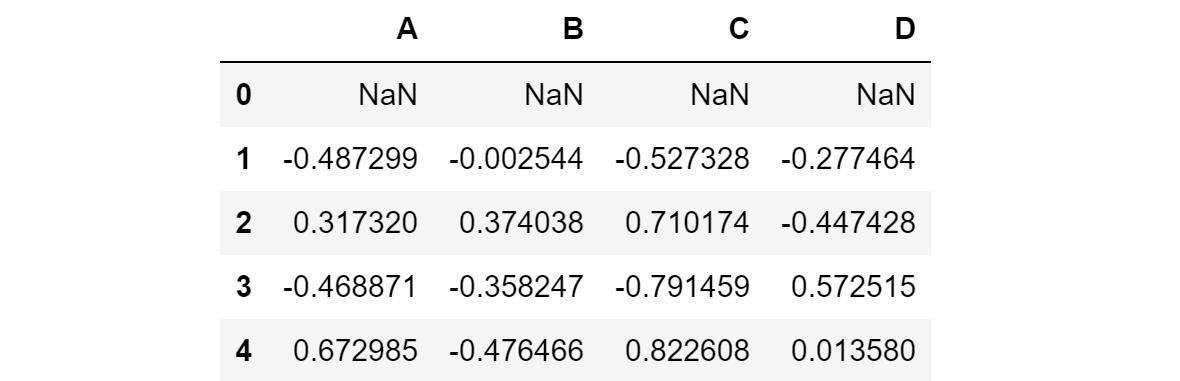
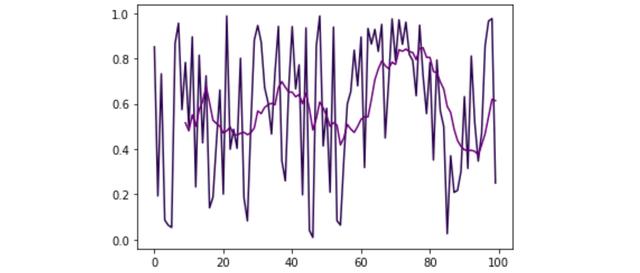
直接使用Pandas的主要好处之一是,许多Pandas的有用数据帧操作可以直接使用。例如,data.diff()的结果,它只需将一行与它之前的行之间的差值(因此,第一行中存在 NaN)。这在许多时间序列应用中都很有帮助。
例如,以下代码,该代码绘制出差异的数据,并演示各种参数在Pandas绘图中的用法,本例中为颜色:

Pandas数据处理功能的另一个应用是,它采用平均滚动均值,这是一种常见的统计方法,用于减少数据平均移动窗口的数据的不可信度。
可直接从数据创建各种其他类型的绘图:
- kde或用于密度图density;
- scatter用于散点图;
- hexbin对于六边形箱图;
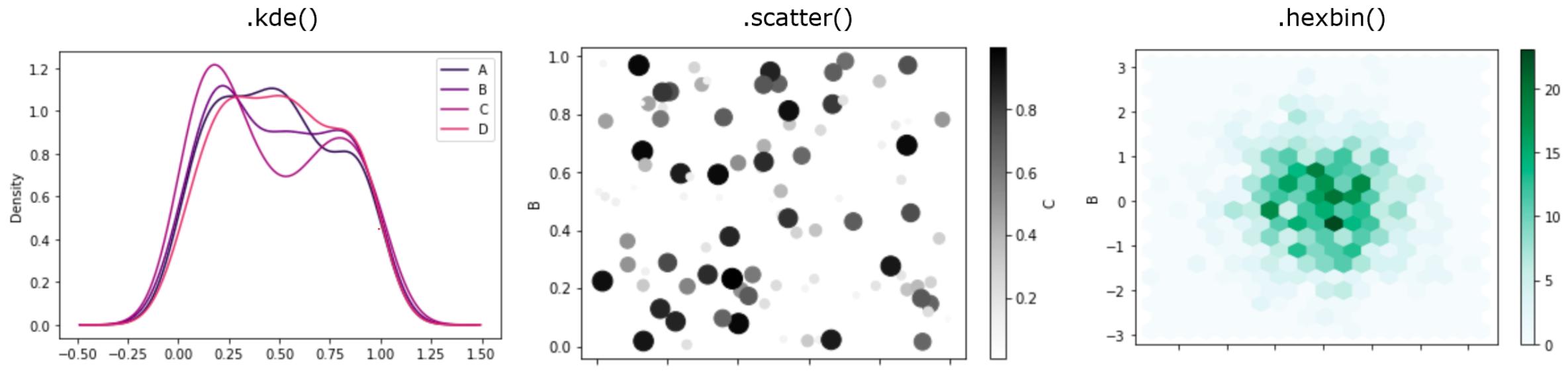
注:尽管在默认情况下 ,如果.plot.scatter()figsize=(x,y)的颜色是灰度,但可以在颜色映射参数中传递。所有绘图都有一个参数,以便控制输出图形的大小。在每个绘图线之后输入分号 (), 允许在 Jupyter 笔记本中具有多个输出。
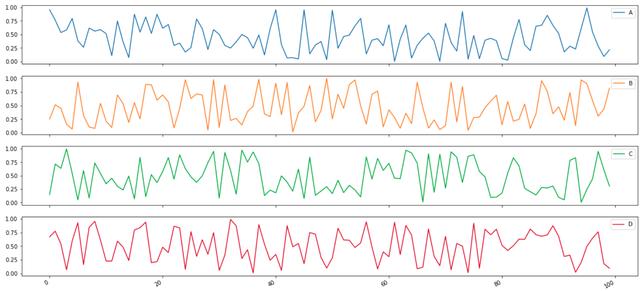
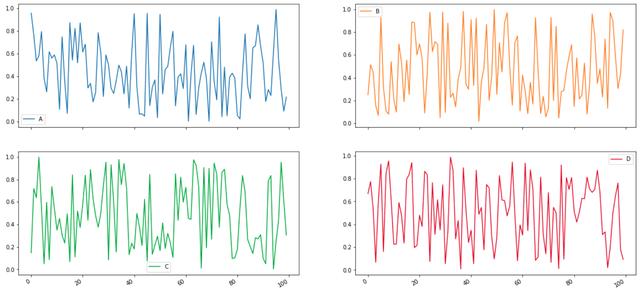
Pandas在为你绘图时做重担的一个例子是子图。通过启用 ,Pandas根据列自动创建子图。例如,考虑以下生成的 DataFrame,它有两列 (和) 以及五行

通常,你需要手动创建两个子图。特别是在想要生成多个子图的情况下,可以想象直接使用Pandas绘图方法会很有帮助。
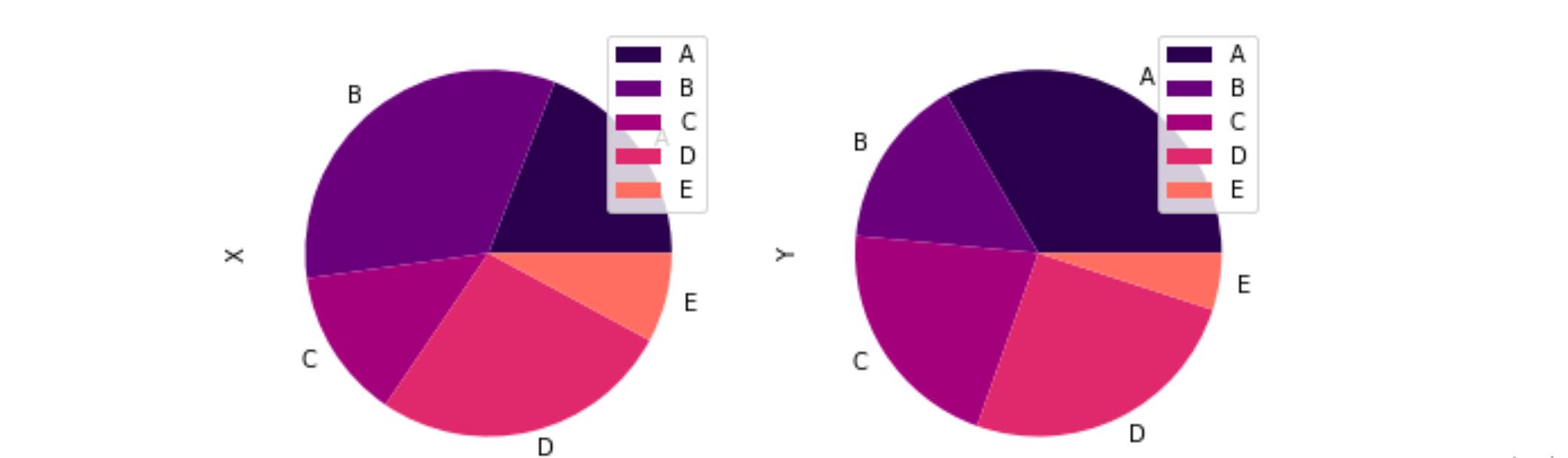
饼图的其他参数包括 ,它将自定义标签添加到切片中;,指定每个切片的颜色;,确定十进制标签的百分比和截断程度;和 ,用于确定标签的大小。作为直接Pandas绘图中子图的便利性的另一个示例,请考虑绘制行数据(使用 时为默认值):

在绘制可视化效果的代码行中添加参数时(在 ): 后)中考虑结果,Pandas根据布局自动以格式格式化子图。每个子图的尺寸由参数确定,该参数指定包含所有子图的"主图"的大小。
鉴于 Pandas 在直接绘图中提供的参数量非常多 — 从错误栏到提供表显示,在可以创建的可视化效果方面几乎没有自由度损失。从提供简单的绘图变体到简单的子图管理,Pandas有太多提供绘图。下次制作简单的数据分析图,试试Pandas!你可能会感到震惊的是,你能够更高效地进行可视化。