













本文转载自微信公众号「新钛云服」,作者舒祝 。转载本文请联系新钛云服公众号。
最近手动搭建了一个openstack环境,创建硬盘时失败,查看日志,提示无法进行调度,怀疑是cinder节点出现问题,去cinder节点查看服务 ,状态显示正常。
systemctl status openstack-cinder-volume.service
- 1.
然后在控制节点查看cinder服务,openstack volume service list
正常情况下显示:
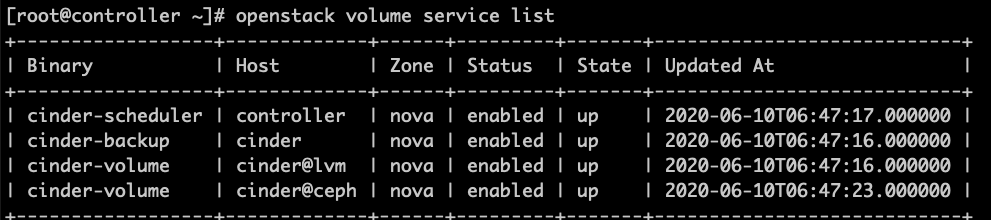
结果显示cinder-volume的state为down,查看日志发现没有任何错误信息,重启cinder的各种服务仍然没有效果,最后决定跟踪源码(说明:文中代码对应的是OpenStack Train版)。
找到openstack volume service list对应的实现代码。
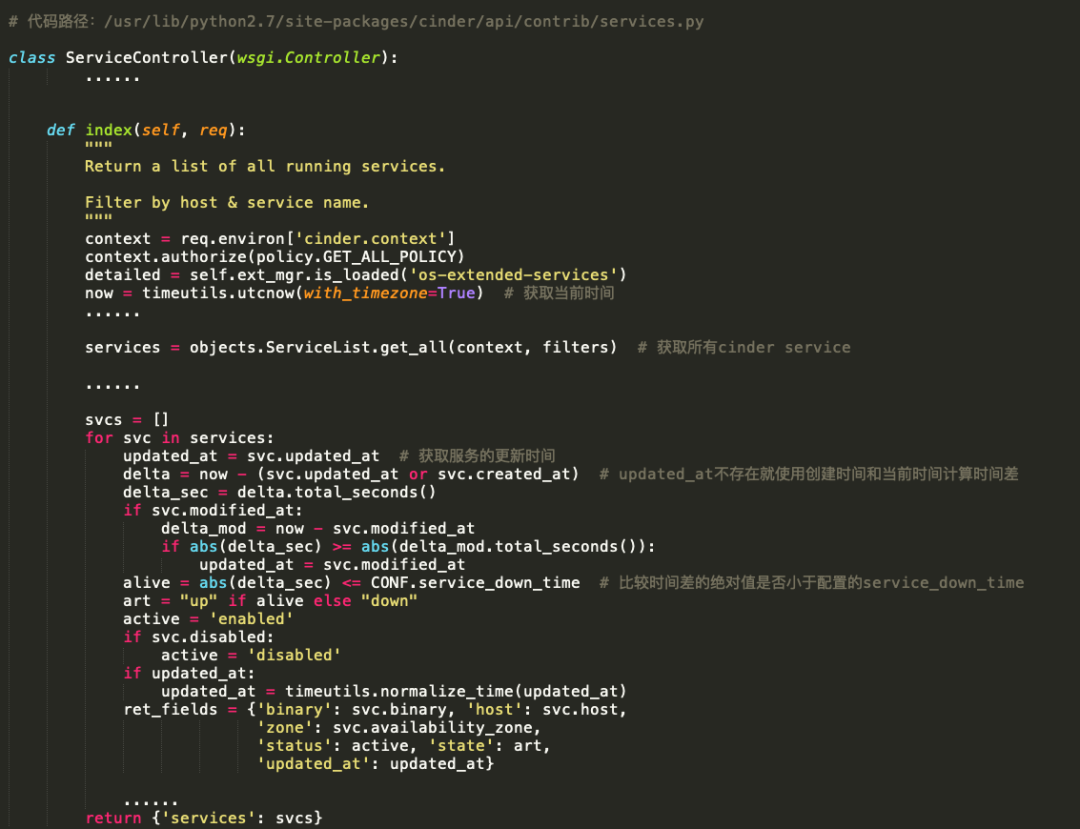
now = timeutils.utcnow(with_timezone=True)
- 1.
由于openstack-cinder-api.servic服务在controller节点启动,所以获取的是controller节点的当前时间。
services = objects.ServiceList.get_all(context, filters)最终会从cinder数据库的services表中获取所有服务数据。

alive = abs(delta_sec) <= CONF.service_down_time,比较时间差的绝对值是否小于配置的service_down_time,其中service_down_time默认时间是60s。
cfg.IntOpt('service_down_time',
default=60,
help='Maximum time since last check-in for a service to be '
'considered up'),
- 1.
- 2.
- 3.
- 4.
art = "up" if alive else "down" 差值小于60,则service 状态为 up,否则为down。由此可见cinder service的state值取决于cinder数据库中 service 表每行数据的 updated_at 列的值和当前 controller 节点的时间差是否在配置的范围之内。
解决问题
上面cinder-volume出现down的原因就是因为运行openstack-cinder-volume.service服务的存储节点时间与controller节点时间差值过大。为了保证状态为up,必须保证两节点的时间差在service_down_time - report_interval之内,默认情况下,差值为50秒。所以同步两台服务器时间之后,再次查看,发现cinder-volume的state变为up。
cinder服务更新机制
下面说下 Cinder Service 的更新机制。
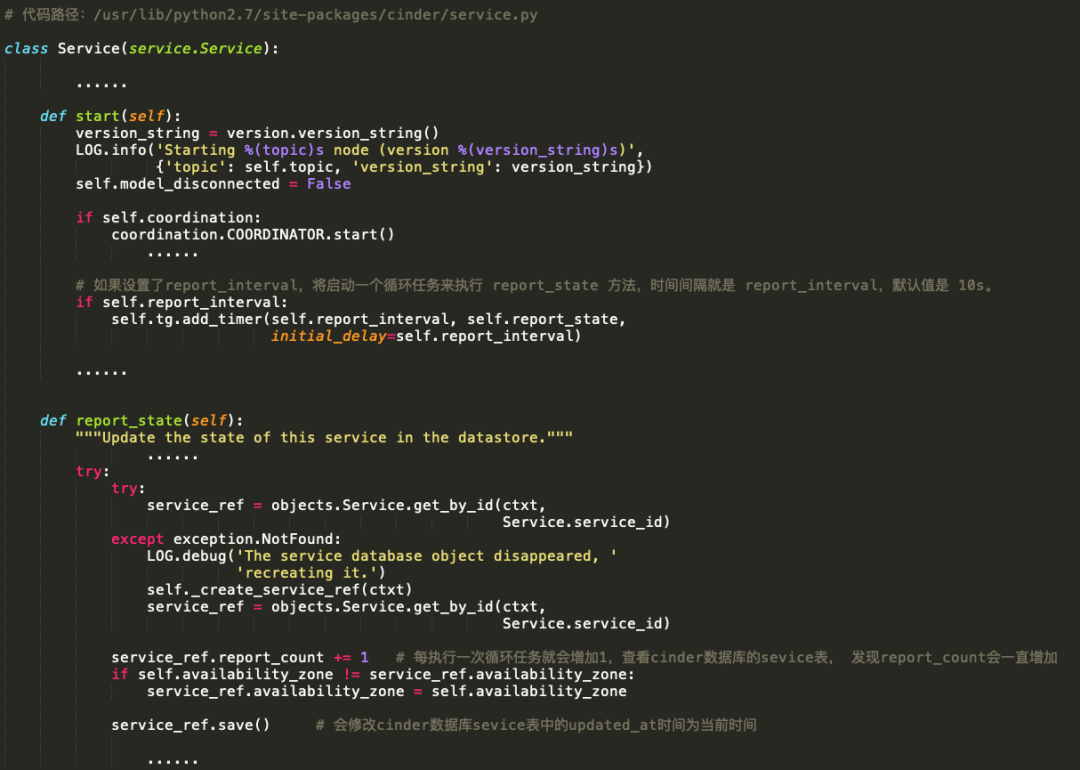
report_interval默认时间是10s,
cfg.IntOpt('report_interval',
default=10,
help='Interval, in seconds, between nodes reporting state '
'to datastore'),
- 1.
- 2.
- 3.
- 4.














