一年前,我和几个小伙伴一起开始在构建机器学习API的开源平台Cortex上工作。起初,我们假设所有用户,包括所有把机器学习(ML)运用于生产的公司,都是拥有成熟数据科学团队的大公司。
但我们大错特错了。
一年中,我们看见学生、独立工程师以及小型团队纷纷把模型投入生产。出乎意料,他们提供的通常都是最先进的大型深度学习模型,可用于日常应用程序。一个两人组成的团队最近建立了一个500个GPU推理集群,以支持其应用程序的1万个并发用户。
仅仅在不久之前,只有预算高、数据量大的公司才能做到这样的事情。现在,任何团队都可以做到。这种转变是多种因素共同作用的结果,但其中一个重要因素是迁移学习。
什么是迁移学习
广义上讲,迁移学习是指将经过一项任务训练的深度神经网络的知识“迁移”到训练相关任务的另一个网络的技术。例如,可以使用迁移学习来获取用于对象检测模型,然后使用少量数据对其进行“微调”来检测更具体的事物。
这些技术之所以能起作用是因为深度神经网络的体系结构。网络的低层负责更多的基础知识,而特定任务知识则通常在顶层:
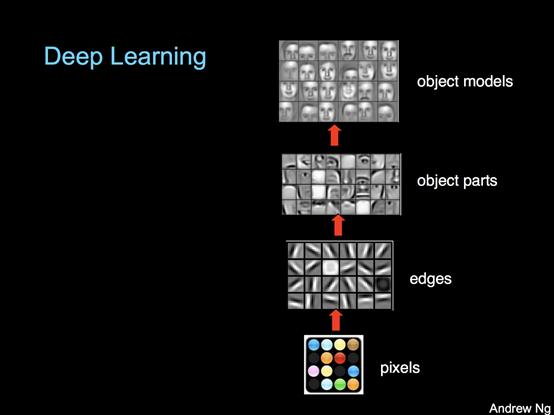
图源:Stanford
较低层训练完后,可以用少量数据微调较高的层。例如,对象检测模型(比如说YOLOv4)进行微调后可以识别具有很小数据集的特定事物(例如车牌)。
在网络之间迁移知识的技术各不相同,但不约而同的是,最近有许多新项目旨在简化这个过程。例如,gpt-2-simple库允许任何人微调GPT-2,还可以使用Python函数生成预测:https://gist.github.com/caleb-kaiser/dd40d16647b1e4cda7545837ea961272。
迁移学习是如何打通机器学习的
大部分团队不会因为缺乏某类知识而无法使用机器学习。如果要构建图像分类器,有许多知名的模型可以使用,使用现代化框架会让训练变得非常简单。对于大多数团队来说,机器学习因其成本因素所以从未被视为一个现实的选择。
让我们用OpenAI的(到目前为止)最佳语言模型GPT-2为例来说明。
如果使用公有云,单就估算GPT-2训练成本就已超过4万美元,除了这一费用,GPT-2还需要训练40GB的文本内容(保守估计超过2000万页),抓取和整理大量文本本身就是一个巨大的项目。这让大多数团队无法训练自己的GPT-2。
但如果只是对其进行微调呢?来看一个相关项目。
AI Dungeon是一款可自行选择的冒险游戏,其风格延续之前的命令游戏地牢爬行者。玩家通过输入指令进行游戏,游戏通过推进冒险作为回应。这款冒险游戏是由训练后的GPT-2模型编写的,你可以编写自己选择的冒险文本:

AI Dungeon是由独立工程师尼克·沃顿开发的,他利用gpt-2-simple和从chooseyourstory.com网站上提取的文本微调GPT。沃尔顿表示微调GPT-2需要30MB的文本和12小时左右的时间来训练DGX-1——大约花费了374.62美元,但做出来的产品效果和AWS的p3dn.24xlarge差不多。
也许大部分团队只能对着4万美元的云服务费和40GB的文本提取量望洋兴叹,但是375美元和30MB即便对小团队来说也不成问题。
迁移学习的应用领域超越了语言模型。在药物发现中,通常没有足够的特定疾病数据来从零开始训练模型。DeepScreening是一个解决此类问题的免费平台,它允许用户上传自己的数据库和微调模型,然后利用该平台来筛选可能会发生反应的化合物库。
图源:unsplash
从零开始训练一个这样的模型超出大多数研究人员的能力范围,但是由于有了迁移学习,突然间人人都可以做到。
新一代深度学习模型取决于迁移学习
必须强调的一点是,尽管笔者目前给出的例子都偏重经济效益,但迁移学习并不是小型团队用来凑数的一个工具,所有团队无论大小都在使用迁移学习来训练深度学习模型。事实上,一些新发布的模型都是专门针对迁移学习的。
还记得GPT-2首次发布时,因其原始内存而霸占各大头版头条,我们以前从未听说过有15亿参数的模型。然而和GPT-3相比则是小巫见大巫了,后者参数量达到1750亿。
除了OpenAI之外,几乎没有哪家公司能训练拥有1750亿个参数的语言模型。即便是部署这么大的模型也存在诸多问题。OpenAI打破了他们发布开源的传统,预训练新模型版本,将GPT-3作为API发行—用户可以使用自己的数据微调GPT-3。
换句话说,GPT-3的庞大让迁移学习不再是训练新任务的一个经济实惠的方法,而是唯一可行的方法。
迁移学习优先方法已经变得越来越普遍。Google刚刚发布的Big Transfer是一个先进计算机视觉模型开源存储库。尽管计算机视觉模型通常要比语言模型小,但它们已经开始追赶了——预训练过的ResNet-152x4接受了1400万张图像的训练,容量为4.1 GB。
顾名思义,Big Transfer旨在鼓励利用这些模型来使用转移学习。作为存储库的一部分,Google还提供了可以轻松微调每个模型的代码。正如下图所示,模型容量会随着时间不断增大(GPT-3会将图表的大小增加10倍):
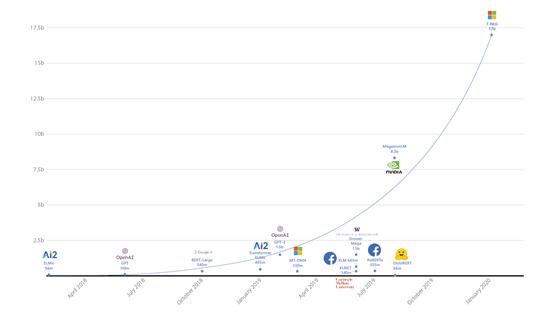
图源:Microsoft
如果这种趋势持续下去(没有迹象表明这种趋势不会持续),那么迁移学习将成为团队使用前沿深度学习的主要方式。
随着模型变得越来越大,迁移学习使得每个团队都能使用这些模型,投入生产的大型深度学习模型的数量猛增。训练这些模型是一个挑战——它们需要大量空间和内存来进行推理,而且通常无法一次处理多个请求。
图源:unsplash
因为这些模型(GPU / ASIC推断,基于请求的弹性伸缩,spot实例支持),我们已经给Cortex引入了几个主要功能,并且随着模型的扩大,我们将不断添加新的功能。
然而,与让世界上每个工程师都可以使用最先进的深度学习解决问题的潜力相比,基础架构挑战性的难度微不足道。人人可使用的深度学习,已经触手可及。