












话说在上周的世界人工智能大会上
素有硅谷钢铁侠之称的埃隆·马斯克
可在大会上爆了个猛料
“特斯拉将在今年完成L5的基本功能”
不过他也表示
还有很多细节问题待解决
再来说说国内,2020年3月,中国工信部官网公示了《汽车驾驶自动化分级》推荐性国家标准报批稿,并拟于2021年1月1日开始实施,未来将成为“中国版自动驾驶分级标准”。
这也标志着L3级自动驾驶正式进入了量产的“前夜”。
一边是L5级别自动驾驶基本完成,另一边是L3级别自动驾驶即将落地,两者的巨大差异说明了,从实验室到真正的落地仍有很长的距离,这是因为需要突破的不仅仅是技术,也有法律法规的逐步完善。
但是不管怎么样,马斯克的这番话无疑给整个汽车行业传递了明确的信号:
完全自动驾驶汽车的上市
会比我们预计的提前很多
什么是自动驾驶级别?
美国汽车工程师协会(SAE)对汽车自动驾驶技术划分为Level 0-Level 5共六个级别,其中L1-L2是指智能驾驶辅助系统。在这个阶段,人类驾驶员仍然要负责所有驾驶任务;L3则标志着进入自动驾驶范畴,因此也被业内普遍认为是自动驾驶领域的一个重要“分水岭”。
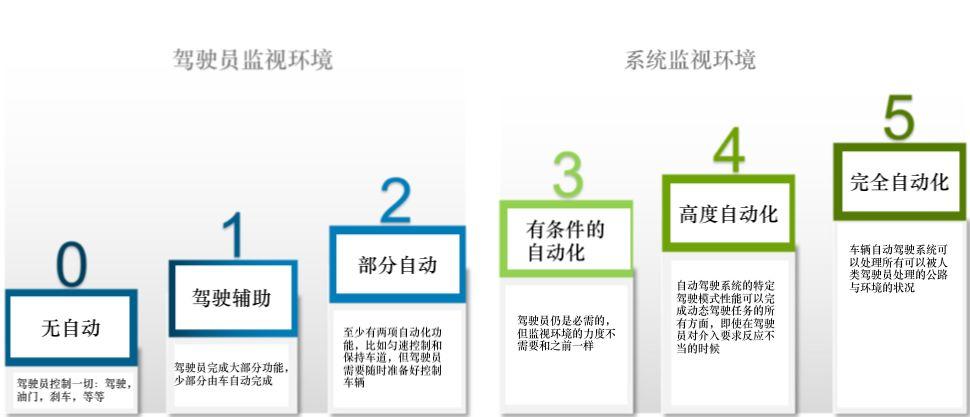
如今,随着“新基建”上升为国家战略,自动驾驶这个新兴的领域也正处在5G、AI,以及云计算、大数据中心几大领域的交汇处,未来有望乘着“新基建”的东风,进一步加速商业化的落地进程。
从这个角度来说,中国汽车产业在大踏步走向自动驾驶后,行业内的竞争激烈程度将急速加剧,而未来谁能最早进入L3级自动驾驶阶段,谁就将最大限度获得新技术带来的自动驾驶这一全新市场的巨大红利。那么,汽车行业在自动驾驶新时代即将来临时,将会遭遇哪些重大的挑战,并应该采取何种应对的战略呢?
L3量产前夜新挑战
事实上,就在今年6月21日,国内首个量产的L3级自动驾驶汽车长安汽车UNI-T就已宣布正式上市,随着明年年初“中国版自动驾驶分级标准”的实施,越来越多的整车厂都会“标配”L3级自动驾驶,中国汽车行业也有望率先进入自动驾驶的新时代。
可以说,这既是一个充满挑战和巨变的新时代,更是一个汽车行业同时间和智慧“赛跑”的新时代,核心的原因就在于,对于整车厂来说,原有的经验不再有效,汽车最核心的价值不再是曾经熟悉的“三大件”(发动机、变速箱和底盘)系统,而是软件定义汽车的时代。
数据显示,目前汽车的车内代码行数已从上世纪80年代的5万行,发展到2010年代的约1200万行,再到2018年的约1.5亿行,而2025年则可能会跃升到15亿行,如此庞大的代码量,对整个行业开发人员的能力将形成巨大挑战,更会带来前所未有的数据量的激增。
对此,戴尔科技集团售前系统工程部解决方案架构师林小引形容的比喻说:“一般开采出来一吨矿石,才能提炼出几克黄金。那么要训练出满足L3级别的自动驾驶算法,所需要的裸数据则在50-100PB量级,而这个过程始终围绕着数据展开,并由数据来驱动的。”
更关键的是,由自动驾驶所带来的这种海量非结构化数据如何“存储、管理、利用和归档备份管理”,同样也是非常具有挑战的,可以从几个维度来做观察:
一是,从高性能看
自动驾驶研发中有大量并行的工作负载,包括:数据上传、数据预处理、深度学习、模拟仿真、大数据分析、归档备份等。这些并行的工作负载需要底层存储提供极高的吞吐性能,以便让服务器中的算力快速读到所需的数据,这样才能够大量节约研发人员的工作时间,使得整个自动驾驶的研发周期缩短,加快产品上市时间。
二是,从高可用看
自动驾驶的一些典型的工作场景是需要持续运行数天甚至数周的时间,如深度学习中对模型算法的训练,软件在环(SiL)的仿真模拟中对感知决策算法的反复回归优化等。因此,这也需要底层数据存储能够提供企业级的高可用,保障自动研发长周期工作任务的持续运行而不中断。
三是,从扩展性看
自动驾驶的研发过程中,还需要采集海量的真实数据并配合虚拟仿真引擎来测试和验证在罕见场景中算法的可靠性。同时,这些数据的积累也是一个线性的过程,甚至有明确的爬坡计划表。所以,这就需要底层数据存储能够以横向扩展的模式由小到大线性地扩展数据存储规模,同时做到在扩容过程中对现有研发应用的无影响。
四是,从安全性看
自动驾驶始终是依靠数据来驱动的,保障数据的安全性变得首当其冲。根据《中华人民共和国测绘法》的规定,自动驾驶在公开道路上所采集的数据需要在具有甲级测绘资质的图商的监管下使用,所有对数据的访问都需要接受图商的审计,这也就意味着自动驾驶过程中需要对数据有足够的、强大的保护机制。
五是,从运维角度
由于数据量巨大,支撑自动驾驶的存储基础架构的规模同样也比较庞大。在这样的背景下,如何能够简单、方便地搭建和管理大规模的存储设备集群,降低运维成本,把更多的资源投入到自动驾驶的研发上,是整车厂在投入自动驾驶研发之初,就必须重点考量的。
由此可见,自动驾驶的新时代是美好的,但也是挑战巨大的,采用何种技术战略和产品方案来化解自动驾驶带来的海量非结构化数据压力,并打造出整车厂的新竞争力不仅是大势所趋,更是迫在眉睫。
加速自动驾驶落地
那么,在L3级自动驾驶即将量产的前夜,汽车整车厂又该如何在自动驾驶领域实现突围呢?
戴尔科技集团近期正式发布了Dell EMC PowerScale无疑给出了一个新的答案,它通过把戴尔科技强大的横向扩展文件系统OneFS和卓越的服务器平台PowerEdge有机结合起来,在延续了Isilon高效地存储、管理、保护和分析非结构化数据的同时,又通过一系列的技术创新,为自动驾驶提供了更为强大的支持能力,为加速自动驾驶的落地真正打牢了基础。

首先,在大规模存储的高性能方面
与传统的存储系统只能纵向扩展相比,PowerScale能够使系统横向扩展,无缝地将现有文件系统或容量增加到PB级,就能以线性方式提高性能和容量。同时,PowerScale还可以根据文件、目录级别或者工作负载的不同优化访问模式,让单个主机可以快速导入或者读取数据。
其次,在容量和可伸缩性方面
PowerScale也充分满足自动就是对于存储基础架构的要求,单个文件系统就能够提供从最小7TB到多PB规模的存储能力,并支持对数百万个文件进行操作。
不仅如此,用户需要的新增容量也可以在几分钟内添加到现有的Isilon卷中,没有停机时间,也不会中断数据可用性,而且不会降低性能。此外,当面对高度并发的自动计时工作负载时,PowerScale的横向扩展体系结构和“独一无二”的OneFS操作系统,还能够进一步消除传统存储解决方案所共有的性能瓶颈。

第三,在存储可用性和数据归档方面
PowerScale具有的CloudPools功能也能够支持数据分层策略,这个策略决定的自动分层解决方案允许根据自动驾驶项目的不同阶段,将数据与极佳价格/性能的存储层做自动的匹配。
由此带来的好处体现在:自动分层策略可以让关键的“热数据”(如正在使用的自动驾驶传感器数据)保存在更高性能的存储层上,而“温数据”或“冷数据”(如已经发布的车辆数据)可以放在更经济高效和更高密度的归档层中。
同时,PowerScale也可以满足自动驾驶的相关测试数据长期存储归档和安全性的要求,同时也能快速地进行数据恢复和再次进行仿真测试的需求,而无需对现有的策略和流程进行更改。
最后,在数据的流通性方面
PowerScale也具备广泛的适应性,它不仅支持NAS协议(如NFS3、NFS4、SMB2、SMB3和FTP)来访问数据,而且还可以通过HDFS协议(Hadoop分布式文件系统)来访问,通过将高效的存储平台与Hadoop集成起来,PowerScale可以让自动驾驶开发人员能够加快分析海量数据,并在几分钟内获得结果。内置HDFS支持消除了移动数据文件和Hadoop存储的时间和开销。

另外,PowerScale搭载的OneFS 9.0还支持对象存储访问协议S3,因此用户可以把数据更轻松的迁移到云端环境之中,满足更多的数据流通性的需求。换句话说,这种支持多协议访问同一数据的特性,既解决了不同用户的不同访问方式的需求,也解决了数据在存储和使用中的一致性和完整性问题,如源数据的存储访问,和大数据分析之间数据的差异性问题等。
值得一提的是,全新推出的PowerScale F系列还增加了全闪存和NVMe节点的能力,更加高效和灵活的满足自动驾驶行业用户最新的发展需求。例如,在图商监管领域,目前国内所有的路采数据需要先由图商进行审查和脱敏处理后才能交由自动驾驶研发商进行后续处理,那么PowerScale F系列就非常适合构建一个高性能的存储集群,由图商审查和脱敏处理后使用。
同样,在自动驾驶的深度学习领域,越来越多的研发团队都在借助TensorFlow或PyTorch等新的深度学习和机器学习解决方案展开研发工作,而PowerScale F系列也可以为深度学习算法提供高性能的底层存储,由此加快深度学习训练的速度并提高GPU的利用率。
不难看出,PowerScale之于自动驾驶研发中面临的数据和存储的挑战,真正做到了“硬件更灵活,成本更节约,生产效率也更高”。其中在数据建模阶段,PowerScale可以为一个集群中的每个节点添加容量、性能和弹性,这使得自动驾驶开发团队能够利用整个群集的性能,解决大规模数据存储的高性能难题。
更关键的是,在训练阶段,通过将高效的PowerScale存储平台与Hadoop集成起来,自动驾驶开发人员还能够更快的分析海量数据,并在几分钟内获得结果,可以说真正为自动驾驶的研发提供了一个最佳选择。
背后的底蕴与底气
毫无疑问,作为中国汽车产业转型升级的重要新方向,自动驾驶是汽车产业新一轮科技创新的重要载体,也将为更多的整车厂提供巨大的发展空间,而戴尔科技通过不断的技术创新,可以说为整车厂的自动驾驶研发提供了更加高效和灵活的产品和解决方案,而在这背后正是其构筑的三重优势,让它具备了赋能的底蕴和底气。
投产检证
戴尔科技在自动驾驶领域的优势不是“纸上谈兵”,而是经过大量整车厂和一级供应商自动驾驶研发/验证系统的实际投产验证,证明了其解决方案是稳定、可靠和高效的。
数据显示,全球超过70%的领先高级驾驶员辅助系统/自动驾驶一级供应商使用OneFS进行ADAS开发;排名前20位的汽车供应商中有70%以上使用由OneFS提供支持的PowerScale存储系统;同时,戴尔科技高级驾驶员辅助系统/自动驾驶(ADAS/AD)客户已部署了超过1EB由OneFS支持的PowerScale存储,用于支持汽车工作流程。
除此之外,目前戴尔科技在全球落地的自动驾驶研发基础架构案例高达40多个,包括了欧洲著名的Tier-1供应商、国内领先的自主品牌整车厂、日系头部的整车厂等,还有更多的项目正在“有条不紊”的落地之中。
端到端
戴尔科技为自动驾驶提供的研发/验证基础架构,还是端到端的解决方案,包括计算、存储、网络、云计算、HPC、AI和大数据等,这种端到端的优势在于,可以最大化地解决了各个产品模块之间的兼容性集成问题,缩短自动驾驶项目的集成时间,不仅可以大大降低项目风险,同时也可以提供最佳实践和成功经验输出为项目“保驾护航”。
确实如此,大型集成项目如果分别采用不同的解决方案,那么每一个不同产品的的兼容性验证将会花费大量的时间。更关键的是,自动驾驶的升级速度比每一个产品的兼容性列表升级的速度更快,因此对客户来说这中间的风险就非常巨大了,而戴尔科技提供的端到端解决方案,最大的优势就在于可以降低项目的风险和节约项目的时间。
持续创新
戴尔科技在产品和解决方案上的不断创新,又为自动驾驶项目的加速研发和验证提供了坚实的基础。以最新推出的PowerScale为例,它就可以凭借产品的独特功能特性,大幅节省海量自动驾驶研发数据在研发各个环节中的“数据搬迁”时间,同时配合戴尔科技提供的增值元数据管理平台DMS,由此可以帮助客户加速自动驾驶的研发和验证的过程。
展望未来,林小引表示,自动驾驶的研发是一个投入非常大的项目,而且对大多数国内汽车行业的客户来说都是新课题,此前并没有经验可循。为此,他也向有意加大自动驾驶研发投入的整车厂提出了两个方面的建议:
❒ 一方面,在自动驾驶领域的基础架构建设方面,整车厂尽量不要自己从头搞一遍,因为自动驾驶的试错成本非常高,因此可以借助该领域具备丰富经验和产品方案的合作伙伴的助助力;
❒ 另一方面,汽车行业客户的核心目标是去整合资源把自动驾驶的黄金算法挖掘出来,并不是把自身训练成一个基础架构的专家,专业的事情要交给专业的厂商去做,而戴尔科技无论是解决方案还是落地经验,都可以让客户的自动驾驶项目更快、更好地完成。
总 结
受“新基建”、5G以及L3级自动驾驶标准等因素的影响,今年大量的自动驾驶势必会加速进入到产品落地的新阶段,整个自动驾驶领域也会迎来新一轮的爆发期,而戴尔科技借助PowerScale的不断技术创新和突破,无疑会帮助汽车行业客户寻找到更多的新模式、新业态和新未来,这是戴尔科技在中国自动驾驶领域能够不断赋能的关键所在,更是之于整个汽车行业今后转型升级的新价值所在。
相关内容推荐:「助力新基建发展」戴尔科技集团打出组合拳
相关产品:PowerEdge XR2 工业机架式服务器















