我整理了数据分析师岗的Python笔试题,主要涉及到用Python完成数据处理和分析的内容。自己做了一遍,供大家学习思考。
一、数据处理题
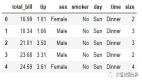
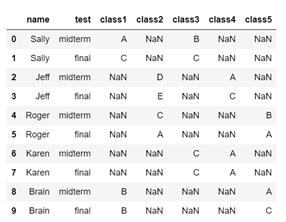
1.将Excel工作簿 “Test.xlsx” 作为dataframe导入 Jupyter Notebook,并将dataframe命名为a. 导入后dataframe x应为如下: 输出结果
- import pandas as pd
- import numpy as np
- a = pd.read_excel('Test.xlsx')
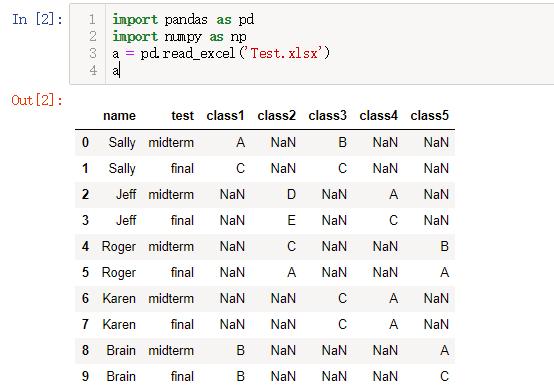
第1题
2.dataframe a 中, class1-class5 指总共5门课,每个学生选两门,列出期中(midterm)、期末(final)成绩(A/B/C)。请用Python语言处理表格,将class1-class5列去除,并增加 class 和 grade 两列,使新dataframe的值与原dataframe对应,并将新dataframe命名为b. 输出结果应为如下: 输出结果
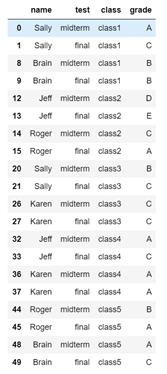
- #1.先设置索引列——复合索引,用列表
- #2.stack()旋转列为行,默认是旋转最内层,并且删除空值
- #3.重置索引
- #4.更改列名
- b = a.set_index(["name","test"]).stack().reset_index()
- b.columns=['name','test','class','grade']
- b
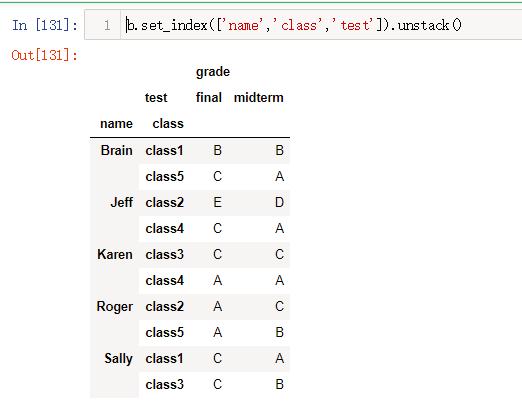
用Python语言将dataframe b 的test列分成midterm和final两列,这两列的值是选的两门课的成绩。将新dataframe命名为c。输出结果应为如下: 输出结果
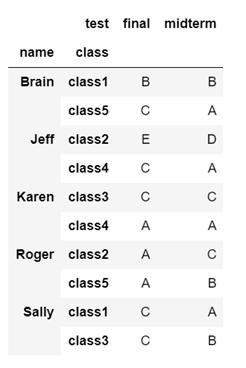
- c = b.set_index(['name','class','test']).unstack()
第2题
4.如下为dataframe d 和 dataframe e DataFrame d and e
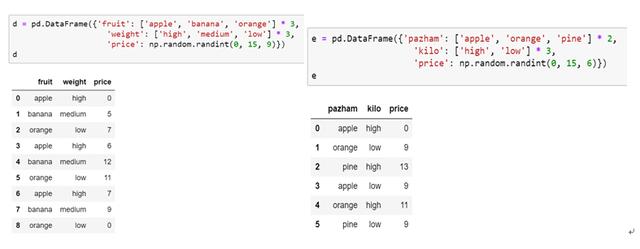
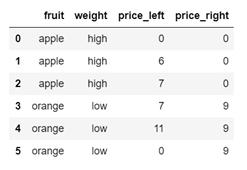
请用Python语言将dataframe d 和 dataframe e 匹配, 输出结果应为如下: 输出结果
- #水果价格信息表
- d = pd.DataFrame({'水果':['apple','apple','banana','banana','orange','orange'],
- '个头':['high','low']*3,
- '单价':[5,3,4,2,7,5]})
- #水果订单
- e = pd.DataFrame({'水果':['apple','banana','orange']*2,
- '个头':['high','low']*3,
- '重量':np.random.randint(1,15,6)})
- pd.merge(d,e,how='inner')
如下是dataframe f DataFrame f
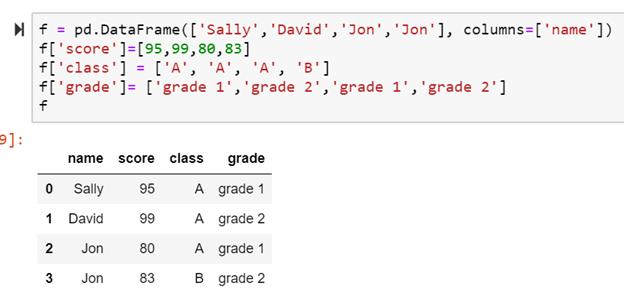
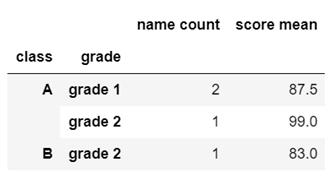
请用python语言得出每节课(class)和每个年级 (grade) 下, 学生的数量和平均成绩。输出结果应为如下: 输出结果
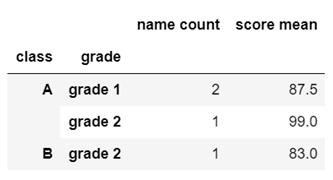
- f = pd.DataFrame(['Sally','David',"Jon",'Jon'],columns=['name'])
- f['score']=[95,99,80,83]
- f['class']=['A','A','A','B']
- f['grade']=['grade 1','grade 2','grade 1','grade 2']
- f
- #方法一:使用groupby
- f.groupby(['class','grade']).agg({'name':'count','score':'mean'})
- #方二:使用pivot_table
- f.pivot_table(index=['class','grade'],values=['name','score'],aggfunc={'name':'count','score':'mean'})
6.如下是dataframe h DataFrame h
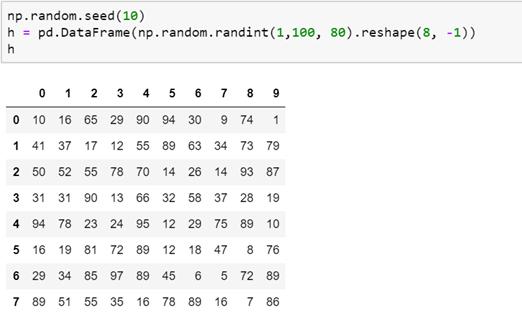
请用Python语言得出每行最小值除以每行最大值的商。输出结果应为如下: 输出结果
- np.random.seed(10)
- h=pd.DataFrame(np.random.randint(1,100,80).reshape(8,-1))
- min_by_max=h.min(axis=1)/h.max(axis=1)
- min_by_max
7.如下是dataframe i DataFrame i
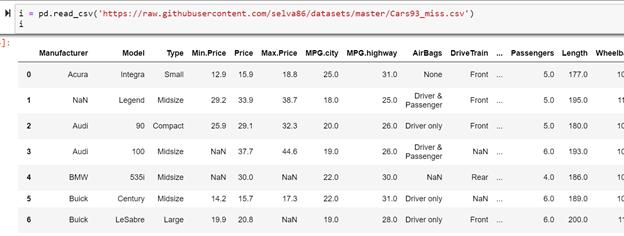
请用Python语言将dataframe i 里Min. Price 列中的NaN值替换成Min. Price 列的平均值, 并将 Max.Price 列中的NaN值替换成Max.Price列的中位数。输出结果应为如下(未截全): 输出结果
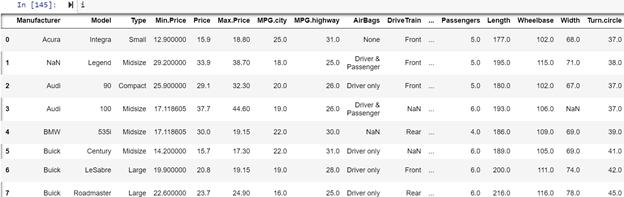
- i=pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv')
- i.head()
- i['Min.Price'].fillna(i['Min.Price'].mean(),inplace=True)
- i['Max.Price'].fillna(i['Max.Price'].median(),inplace=True)
- i.isnull().sum()