












周一早上,软件开发平台GitHub出现了严重宕机,众多开发人员为之抓狂。

GitHub故障是从04:06 UTC(03:06 BST)开始的,在09:31 BST已得到了解决。
这次事件让人们对单单在2020年4月发生三起单独故障后GitHub的可靠性提出了新的疑问。
GitHub将4月的那三次故障分别归咎于:
- 软件负载均衡系统的错误配置破坏了在服务于GitHub.com的应用程序与其依赖的内部服务之间的流量内部路由;
- 数据库连接配置错误,与当时进行中的数据分区工作有关,“导致意外地进入到生产环境”;
- 网络配置“无意中应用于我们的生产网络”。
GitHub在4月曾承认,其模拟实验室环境存在问题。
该公司称:“该模拟环境构建数据库和数据库连接的方式与生产环境不一样。这可能导致生产环境所特有的连接变更的可测试性受限制。我们会在未来几个月内解决这个问题。”
GitHub的大部分平台都在其自己的裸机基础架构上运行,网络基础架构则“围绕Clos网络拓扑结构而建,每个网络设备都通过边界网关协议(BGP)共享路由。”
GitHub在2018年被微软以75亿美元的价格收购,被5000多万开发人员所使用。考虑到它支持的工作负载以及外界广泛依赖它以确保高可用性,像这样的大规模故障可能会带来严重影响。
与其他许多大型基础架构提供商一样,GitHub的所有者微软也面临这个挑战:新冠疫情后远程工作人员数量激增,从而导致工作负载激增,因此需要迅速扩大数据中心基础架构的规模。微软在4月份承认,疫情过后,它面临供应链方面的一些问题。
众多网友在twitter、微博议论:
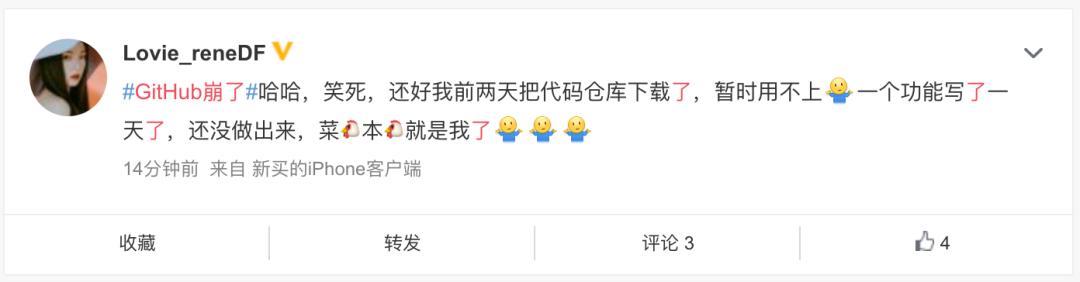
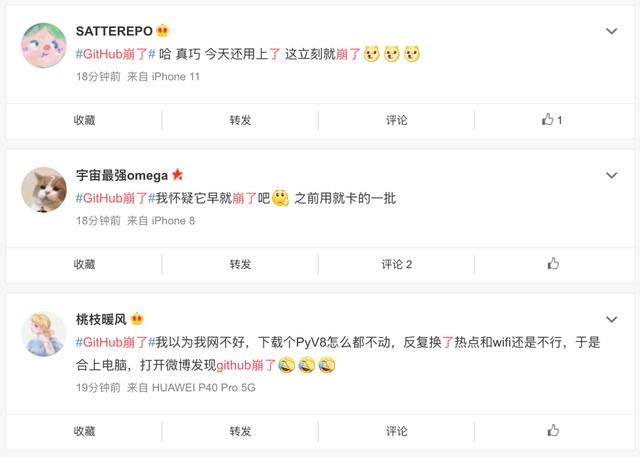
由于全球各地的工厂纷纷关闭,大企业和超大规模公司需要检修数据中心,新冠疫情严重影响了全球服务器硬件供应链。(Dropbox的首席技术官表示,他公司的数据中心团队“在8周内主动更换掉了30000个部件”,以安全地减少现场工作人员)。
与此同时,芯片制造商AMD在第一季度财报电话会议上表示,新冠疫情危机期间的短短10天内,一家未透露名称的云提供商为数据中心增加了10000台服务器,由于工作负载猛增,该云提供商拼命扩大其基础架构的规模。
然而,GitHub的问题似乎主要还是跟模拟环境与生产环境之间的缺口方面的问题有关。
















