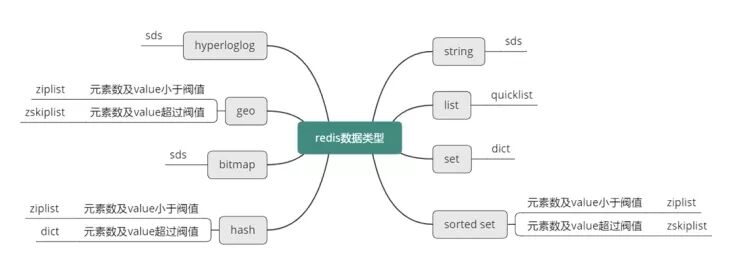
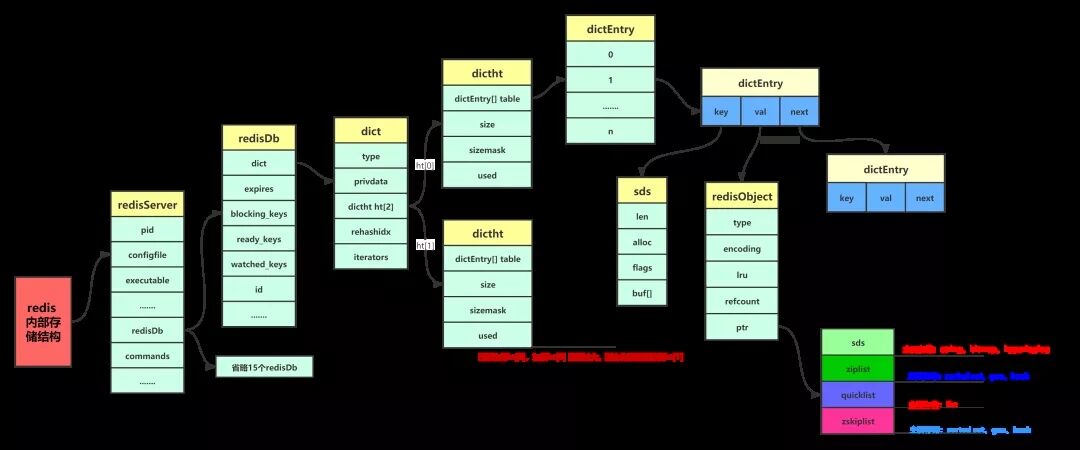
Redis 数据库虽然一直都在使用,但是对其内部存储结构之类的,都没有研究过,哪怕是面试的时候都没有准备过这方面的东西。最近在看一门网课,里面有讲到过这一块的内容,结合了《Redis 设计与实现》这本书,粗略的整理了 Redis 的内部存储结构。就是下面这张图。
对于 Redis 数据库,绝大多数人都知道有每个 Redis 实例有 16 个数据库,但是对于内部是怎么扭转的大部分人可能不太清楚,反正我是不清楚。整体流程差不多就是上图表示的那样吧,知识面有限,难免存在缺漏,凑合着看吧。
其实前面的这些都不是太重要,重要的是后面那四种数据结构和 redisObject。不管重不重要了,都来过一遍吧。
redisDb
redisDb 就是数据库实例,存储了真实的数据,每个 Redis 实例都会有 16 个 redisDb。redisDb 的结构定义如下:
- typedef struct redisDb {
- dict *dict; /* The keyspace for this DB */
- dict *expires; /* Timeout of keys with a timeout set */
- dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
- dict *ready_keys; /* Blocked keys that received a PUSH */
- dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
- int id; /* Database ID */
- long long avg_ttl; /* Average TTL, just for stats */
- list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
- } redisDb;
redisDb 结构体中有 8 个参数:
- dict:dict 是用来存储数据的,当前 DB 下的所有数据都存放在这里。
- expires:存储 key 与过期时间的映射。
- blocking_keys:存储处于阻塞状态的 key 及 client 列表。比如在执行 Redis 中 list 的阻塞命令 blpop、brpop 或者 brpoplpush 时,如果对应的 list 列表为空,Redis 就会将对应的 client 设为阻塞状态,同时将该 client 添加到 DB 中 blocking_keys 这个阻塞 dict。
- ready_keys:存储解除阻塞的 Key。当有其他调用方在向某个 key 对应的 list 中增加元素时,Redis 会检测是否有 client 阻塞在这个 key 上,即检查 blocking_keys 中是否包含这个 key,如果有则会将这个 key 加入 read_keys 这个 dict 中。同时也会将这个 key 保存到 server 中的一个名叫 read_keys 的列表中。
- watched_keys:当 client 使用 watch 指令来监控 key 时,这个 key 和 client 就会被保存到 watched_keys 这个 dict 中。
- id:数据库编号。
Dict
Dict 数据结构在 Redis 中非常的重要,你可以看到在 redisDb 中,8 个字段中有 5 个是 dict,并且在其他地方也有大量的应用。dict 结构体定义如下:
- typedef struct dict {
- dictType *type;
- void *privdata;
- dictht ht[2];
- long rehashidx; /* rehashing not in progress if rehashidx == -1 */
- unsigned long iterators; /* number of iterators currently running */
- } dict;
dict 本身是比较简单的,字段也不多,其中有三个字段比较重要,有必要了解一下:
- type:用于保存 hash 函数及 key/value 赋值、比较函数。
- ht[2]:用来存储数据的数组。默认使用的是 0 号数组,如果 0 号哈希表元素过多,则分配一个 2 倍 0 号哈希表大小的空间给 1 号哈希表,然后进行逐步迁移。
- rehashidx:用来做标志迁移位置。
Dictht & DictEntry
- typedef struct dictht {
- # 哈希表数组
- dictEntry **table;
- # 哈希表大小
- unsigned long size;
- #哈希表大小掩码,用于计算索引值
- unsigned long sizemask;
- # 该哈希表已有节点的数量
- unsigned long used;
- } dictht;
- typedef struct dictEntry {
- # 键
- void *key;
- union {
- # 值
- void *val;
- uint64_t u64;
- int64_t s64;
- double d;
- } v;
- # 指向下个哈希表节点,形成链表
- struct dictEntry *next;
- } dictEntry;
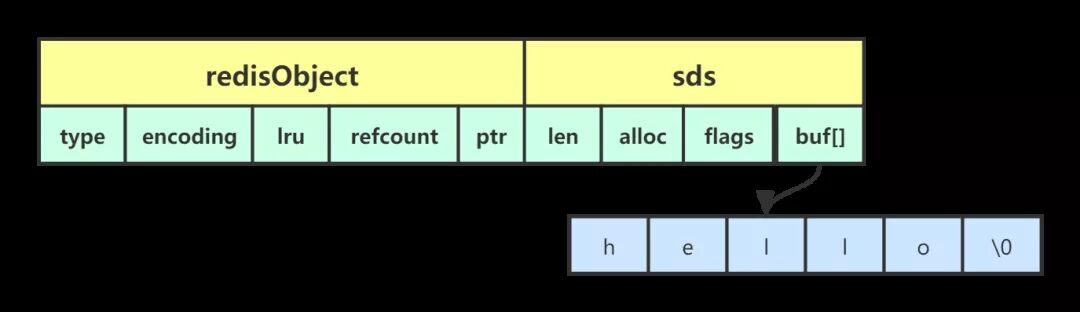
dictht 数据结构没啥说的,dictEntry 是真正挂载数据的节点,跟 Java 中的 Map 有一点像,采用 key-value 的映射方式。key 采用的是 sds 结构的字符串,value 为存储各种数据类型的 redisObject 结构。
redisObject、sds还有其他几种数据结构才是重点,面试的时候有可能会出现,作为使用者,其实了解这几个就够了。
redisObject
redisObject 可以理解成 Redis 数据的数据头,里面定义了一些数据的信息。redisObject 结构体定义如下:
- typedef struct redisObject {
- unsigned type:4;
- unsigned encoding:4;
- unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
- * LFU data (least significant 8 bits frequency
- * and most significant 16 bits access time). */
- int refcount;
- void *ptr;
- } robj;
redisObject 结构体字段不多,就 5 个字段,但是这几个字段都挺重要的,过一下这 5 个字段的含义:
type
type 表示的是 Redis 对象的数据类型,代表这条数据是什么类型,目前 Redis 有 7 种类型。分别为:
- OBJ_STRING:字符串对象。
- OBJ_LIST:列表对象。
- OBJ_SET:集合对象。
- OBJ_ZSET:有序集合对象。
- OBJ_HASH:哈希对象。
- OBJ_MODULE:模块对象。
- OBJ_STREAM:消息队列/流对象。
encoding
encoding 是 Redis 对象的内部编码方式,即这条数据最终在内部是以哪种数据结构存放的。这个字段的作用还是相当大的,我看了一下源码,目前 Redis 中有 10 种编码方式,如下:
- OBJ_ENCODING_RAW
- OBJ_ENCODING_INT
- OBJ_ENCODING_HT
- OBJ_ENCODING_ZIPLIST
- OBJ_ENCODING_ZIPMAP
- OBJ_ENCODING_SKIPLIST
- OBJ_ENCODING_EMBSTR
- OBJ_ENCODING_QUICKLIST
- OBJ_ENCODING_STREAM
- OBJ_ENCODING_INTSET
LRU
LRU 存储的是淘汰数据用的 LRU 时间或 LFU 频率及时间的数据。
refcount
refcount 记录 Redis 对象的引用计数,用来表示对象被共享的次数,共享使用时加 1,不再使用时减 1,当计数为 0 时表明该对象没有被使用,就会被释放,回收内存。
ptr
ptr 是真实数据存储的引用,它指向对象的内部数据结构。比如一个 string 的对象,内部可能是 sds 数据结构,那么 ptr 指向的就是 sds,除此之外,ptr 还可能指向 ziplist、quicklist、skiplist。
redisObject 大概就这些,下面在聊一聊 Redis 中内存常用的四种数据结构。
1.sds(简单动态字符串)
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串),而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 用作 Redis 的默认字符串表示。
实现者为了较少开销,就 sds 定义了 5 种结构体,分别为:sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64。这样最终存储的时候 sds 会根据字符串实际的长度,选择不同的数据结构,以更好的提升内存效率。5 种结构体的源代码如下:
- struct __attribute__ ((__packed__)) sdshdr5 {
- unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr8 {
- uint8_t len; /* used */
- uint8_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr16 {
- uint16_t len; /* used */
- uint16_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr32 {
- uint32_t len; /* used */
- uint32_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr64 {
- uint64_t len; /* used */
- uint64_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
除了 sdshdr5 之外,其他的几个数据结构都包含 4 个字段:
- len:字符串的长度。
- alloc:给字符串分配的内存大小。
- flags:当前字节数组的属性。
- buf:存储字符串真正的值和一个结束符 \0。
在 redisObject 中有一个编码方式的字段,sds 数据结构有三种编码方式,分别为 INT、RAW 、EMBSTR。INT 就相对比较简单,ptr 直接指向了具体的数据。在这里就简单的说一说 RAW 和 EMBSTR 的区别。
在 Redis 源码中,有这么一段代码,来判断采用哪种编码方式。当保存的字符串长度小于等于 44 ,采用的是 embstr 编码格式,否则采用 RAW 编码方式。(具体的长度可能每个版本定义不一样)
- #define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
- robj *createStringObject(const char *ptr, size_t len) {
- if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
- return createEmbeddedStringObject(ptr,len);
- else
- return createRawStringObject(ptr,len);
- }
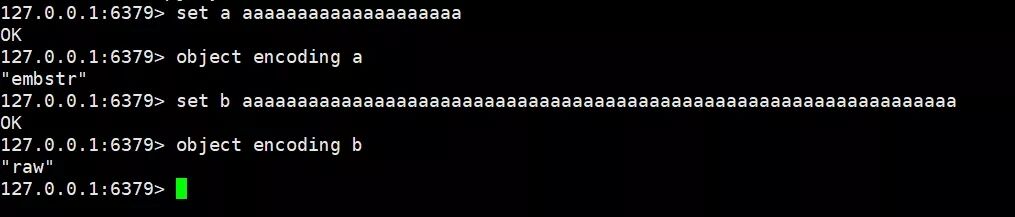
embstr 和 raw 编码方式最主要的区别是在内存分配的时候。embstr 编码是专门用于保存短字符串的一种优化编码方式,raw 编码会调用两次内存分配函数来分别创建 redisObject 结构和 sdshdr 结构,而 embstr 编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含redisObject和sdshdr两个结构。
embstr 编码
raw 编码
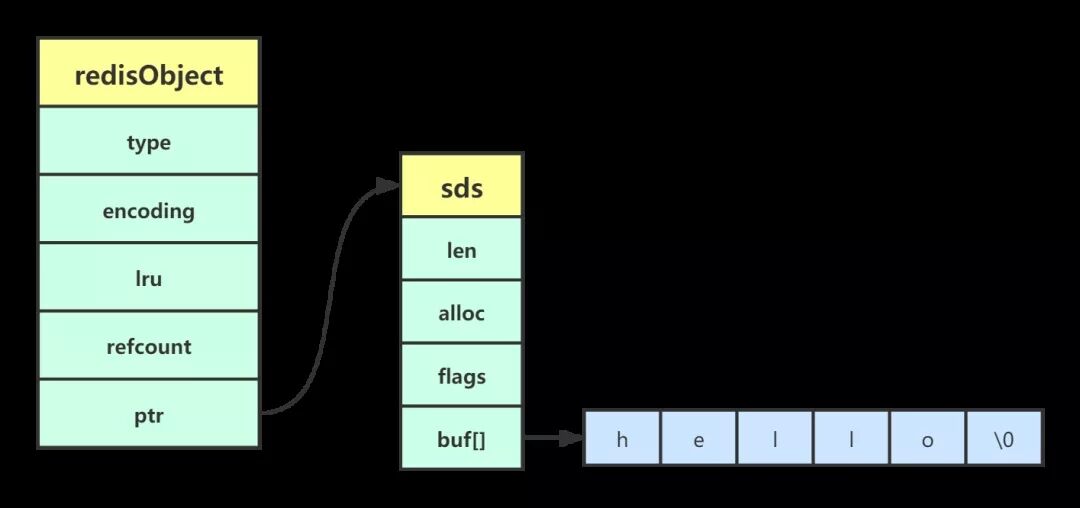
raw 编码
sds 主要是作为字符串的内部数据结构,同时 sds 也是 hyperloglog、bitmap 类型的内部数据结构。
2.ziplist(压缩列表)
ziplist 是专门为了节约内存,并减少内存碎片而设计的数据结构,ziplist是一块连续的内存空间,可以连续存储多个元素,没有冗余空间,是一种连续内存数据块组成的顺序型内存结构。

ziplist 主要包含 5 个部分:
- zlbytes:ziplist所占用的总内存字节数。
- Zltail:尾节点到起始位置的字节数。
- Zllen:总共包含的节点/内存块数。
- Entry:ziplist 保存的各个数据节点,这些数据点长度随意。
- Zlend:一个魔数 255,用来标记压缩列表的结束。
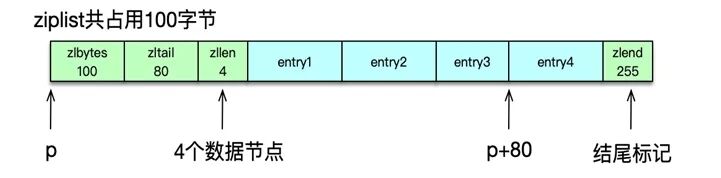
如图所示,一个包含 4 个元素的 ziplist,总占用字节是 100bytes,该 ziplist 的起始元素的指针是 p,zltail 是 80,则第 4 个元素的指针是 P+80。
ziplist 的存储节点是 zlentry, zlentry 结构体定义如下:
- typedef struct zlentry {
- unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
- unsigned int prevrawlen; /* Previous entry len. */
- unsigned int lensize; /* Bytes used to encode this entry type/len.
- For example strings have a 1, 2 or 5 bytes
- header. Integers always use a single byte.*/
- unsigned int len; /* Bytes used to represent the actual entry.
- For strings this is just the string length
- while for integers it is 1, 2, 3, 4, 8 or
- 0 (for 4 bit immediate) depending on the
- number range. */
- unsigned int headersize; /* prevrawlensize + lensize. */
- unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
- the entry encoding. However for 4 bits
- immediate integers this can assume a range
- of values and must be range-checked. */
- unsigned char *p; /* Pointer to the very start of the entry, that
- is, this points to prev-entry-len field. */
- } zlentry;
zlentry 结构体中有 6 个字段:
- prevRawLen:前置节点的长度;
- preRawLenSize:编码 preRawLen 需要的字节数;
- len:当前节点的长度;
- lensize:编码 len 所需要的字节数;
- encoding: 当前节点所用的编码类型;
- entryData:当前节点数据;
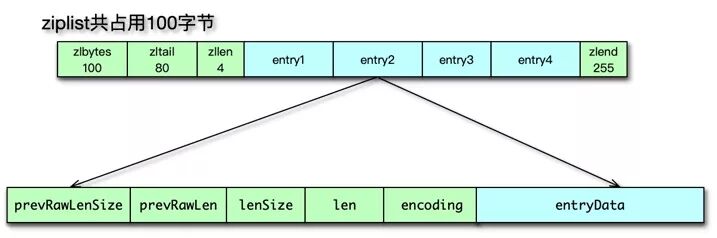
由于 ziplist 是连续紧凑存储,没有冗余空间,所以插入新的元素需要 realloc 扩展内存,所以如果 ziplist 占用空间太大,realloc 重新分配内存和拷贝的开销就会很大,所以 ziplist 不适合存储过多元素,也不适合存储过大的字符串。
ziplist 是 hash、sorted set 数据类型的内部存储结构之一,对于 hash 来说,当元素不超过 512 个 并且值不超过 64个字节,会使用 ziplist 作为内存存储结构,我们可以通过修改 hash-max-ziplist-entries、hash-max-ziplist-value 参数来控制。对于 sorted set 来说,当元素个数不超过 128个并且值不超过 64 字节,使用 ziplist 来存储,可以通过调整 zset-max-ziplist-entries、zset-max-ziplist-value 来控制。
3.quicklist(快速列表)
quicklist 数据结构是 Redis 在 3.2 之后引入的,用来替换 linkedlist。因为 linkedlist 每个节点有前后指针,要占用 16 字节,而且每个节点独立分配内存,很容易加剧内存的碎片化。
而 ziplist 由于紧凑型存储,增加元素需要 realloc,删除元素需要内存拷贝,天然不适合元素太多、value 太大的存储,quicklist 也就诞生了。
quicklist 相关结构体定义如下:
- typedef struct quicklist {
- quicklistNode *head;
- quicklistNode *tail;
- unsigned long count; /* total count of all entries in all ziplists */
- unsigned long len; /* number of quicklistNodes */
- int fill : 16; /* fill factor for individual nodes */
- unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
- } quicklist;
- typedef struct quicklistNode {
- struct quicklistNode *prev;
- struct quicklistNode *next;
- unsigned char *zl;
- unsigned int sz; /* ziplist size in bytes */
- unsigned int count : 16; /* count of items in ziplist */
- unsigned int encoding : 2; /* RAW==1 or LZF==2 */
- unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
- unsigned int recompress : 1; /* was this node previous compressed? */
- unsigned int attempted_compress : 1; /* node can't compress; too small */
- unsigned int extra : 10; /* more bits to steal for future usage */
- } quicklistNode;
quicklist 整体结构图:
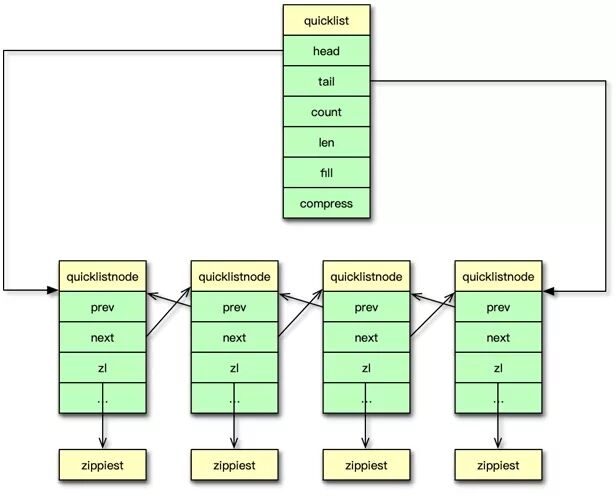
quicklist 整体结构还是比较简单的,它是一个基于 ziplist 的双向链表。将数据分段存储到 ziplist,然后将这些 ziplist 用双向指针连接。
quicklist 结构体说明:
- head、tail 是两个指向第一个和最后一个 ziplist 节点的指针。
- count 是 quicklist 中所有的元素个数。
- len 是 ziplist 节点的个数。
- compress 是 LZF 算法的压缩深度。
quicklistNode 结构体就更简单的了,quicklistNode 主要包含一个 prev/next 双向指针,以及一个 ziplist 节点。单个 ziplist 节点可以存放多个元素。

quicklist 是 list 列表的内部数据结构,quicklist 从头尾读写数据很快,时间复杂度为 O(1)。也支持从中间任意位置插入或读写元素,但速度较慢,时间复杂度为 O(n)。
4.zskiplist(跳跃表)
在 Java 中也有跳跃表,跳跃表 zskiplist 是一种有序数据结构,它通过在每个节点维持多个指向其他节点的指针,从而可以加速访问,在大部分场景,跳跃表的效率和平衡树接近,跳跃表支持平均 O(logN) 和最差 O(n) 复杂度的节点查找,并且跳跃表的实现比平衡树要简单。
但是在 Redis 中zskiplist 应用的并不多,只有在以下两种情况下会使用到跳跃表:
- 在 sorted set 数据类型中,如果元素数较多或元素长度较大,则使用跳跃表作为内部数据结构。默认元素数超过 128 或者最大元素的长度超过 64,此时有序集合就采用 zskiplist 进行存储。
- 在集群结点中用作内部数据结构。
在 Redis 中,跳跃表主要有 zskiplistNode 和 zskiplist 组合,定义如下:
- typedef struct zskiplistNode {
- sds ele;
- double score;
- struct zskiplistNode *backward;
- struct zskiplistLevel {
- struct zskiplistNode *forward;
- unsigned long span;
- } level[];
- } zskiplistNode;
- typedef struct zskiplist {
- struct zskiplistNode *header, *tail;
- unsigned long length;
- int level;
- } zskiplist;
- typedef struct zset {
- dict *dict;
- zskiplist *zsl;
- } zset;
跳跃表 zskiplist 结构比较简单,有四个字段:
- header 指向跳跃表的表头节点。
- tail 指向跳跃表的表尾节点。
- length 表示跳跃表的长度,它是跳跃表中不包含表头节点的节点数量。
- level 是目前跳跃表内,除表头节点外的所有节点中,层数最大的那个节点的层数。跳跃表的节点 zskiplistNode 要相对复杂一些。不过也只有 4 个字段:
- ele 是节点对应的 sds 值,在 zset 有序集合中就是集合中的 field 元素。
- score 是节点的分数,通过 score,跳跃表中的节点自小到大依次排列。
- backward 是指向当前节点的前一个节点的指针。
- level 是节点中的层,每个节点一般有多个层。每个 level 层都带有两个属性,一个是 forwad 前进指针,它用于指向表尾方向的节点;另外一个是 span 跨度,它是指 forward 指向的节点到当前节点的距离。
跳跃表的思想比较简单,以空间换时间,可以实现快速查找。比如我们要找 S3 这个节点,从先从表头节点的 L32 层开始查找,一层一层的下沉,最后找到想要的元素。
最后总结一下 Redis 的 8 大类型使用的内部存储结构。