机器学习项目中含有众多因素,包括数据处理、模型优化等。开发者经常会陷入混乱,或者遗漏一些重要的东西。这里有一份备忘清单,请查收。
任何科研项目都是系统性的,机器学习项目也不例外,它包含一系列大大小小、或繁或简的要素和组件,如讨论、准备工作、提出问题、模型构建和优化调整等。在这种情况下,开发者很容易漏掉一些重要的东西。
这时就需要对项目中经涉及到的任务做一份详尽的清单。有时开发者绞尽脑汁也无法找到一个好的起始点,那么任务清单则有助于他们在正确的信息源中提取有用的数据并建立联系,从而发掘出深刻见解。
此外,还需要对项目中的每项任务进行规划的检查,确保任务的完成度。
正如 Atul Gawande 在其著作《清单宣言:如何把事情做对》(Checklist Manifesto)中说到的:
我们所了解事物的数量和复杂度已经超出了自身从它们中正确、安全或可靠地获益的能力。
在本文中,网页和数据科学讲师 Harshit Tyagi 以端到端机器学习项目为例,对经常涉及的任务做了一份清单。
本文作者 Harshit Tyagi。
接下来,我们就来看 Harshit Tyagi 是如何一步步创建属于自己的机器学习项目任务清单的。
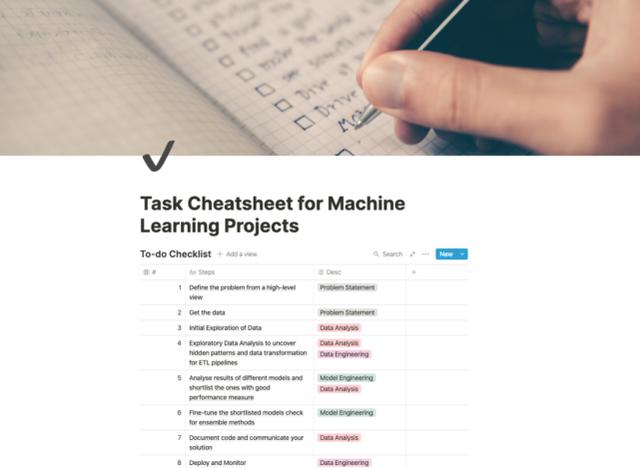
八步完成 ML 项目检查清单
几乎每个机器学习项目中都至少要执行 8-10 个步骤,其中一些步骤的执行顺序也可以互换。
步骤 1:从一个高水平的视角定义问题
执行此步骤是为了弄清楚问题的业务逻辑。你应该了解到:
问题的本质(有监督的 / 无监督的,分类问题 / 回归问题)。
你可以开发的方案类型。
应该用什么指标来度量性能?
机器学习是解决这个问题的正确方法吗?
解决该问题的手动方法。
该问题固有的假设。
步骤 2:确定数据源并获取数据
在大多数情况下,如果你已经准备一些数据并想要定义关于这些数据的问题以更好地利用输入的数据,那么你可以先于步骤 1 执行这个步骤。
基于问题的定义,你需要确定数据源中哪些可以作为数据库或传感器等。对于生产中某个应用的部署,这一步应该通过开发数据 pipeline 来实现自动化,以保证输入的数据能够进入系统。
具体步骤如下:
列出你需要的数据源及数据量;
检查存储空间是否会成为问题;
检查你是否有权限应用这些数据来达到你的目的;
获取数据并将其转换为可利用的格式;
检查数据类型,通常包括文本、分类、数值、时序、图像数据;
保留样本以进行最终的测试。
步骤 3:初步探索数据
在这一步中,你需要对所有影响项目结果 / 预测 / 目标的特征进行研究。如果数据量很大,请对数据进行采样使得分析更易管理。具体步骤如下:
使用 jupyter notebook,因为它为研究数据提供了简单直观的界面;
确定目标变量;
确定特征的类型(分类、数值、文本等);
分析特征之间的关系;
添加一些可视化数据,使每个特征对目标变量的影响更易于解释;
记录你的发现。
步骤 4:探索性数据分析以准备数据
在这一步中,通过定义数据转换、数据清理、特征选择 / 工程和扩展的函数来处理之前步骤中的发现。具体如下:
编写数据转换函数,并自动处理将输入的下一批数据;
编写数据清理函数(估算缺失值并处理异常值);
编写函数以选择和工程化特征,包括删除冗余特征、特征格式化以及其他数学变换;
特征扩展——标准化特征。
步骤 5:开发一个基线模型,然后探索其他模型以选出最佳模型
创建一个能够为所有其他复杂机器学习模型提供基线的基础模型。具体步骤如下:
使用默认参数训练一些常用的机器学习模型,如朴素贝叶斯、线性回归、支持向量机(SVM)等;
度量并比较每种模型的性能;
对每个模型采用 N 倍交叉验证并在 N 倍的基础上计算性能指标的均值和标准差;
研究对目标影响最大的特征;
分析模型在预测过程中存在的错误类型;
用不同的方式工程化特征;
重复上述步骤几次,以确保使用正确的特征,且其形式也无误;
选出基于性能指标的最佳模型。
步骤 6:优化你选出的模型并检查相关方法
这是你更加接近最终解决方案的关键步骤之一,具体步骤如下:
用交叉验证优化超参数;
用随机搜索或网格搜索等自动调整方法来找出最佳模型的最佳配置;
测试相关方法,比如集成学习等;
用尽可能多的数据测试模型;
最终确定后,使用在开始保留的未见过测试样例来检查模型是否存在过拟合或欠拟合。
步骤 7:保存代码并交流你的方案
交流的过程也是性能加倍的过程。你需要记得所有已有或潜在的利益相关者。主要步骤包括如下:
保存代码并记录整个项目的过程及用到的方法;
创建仪表板,如 voila 或带有接近自我解释可视化的有效 presentation;
撰写一篇描述你如何进行特征分析、测试数据转换等的文章 / 报告。记录你的学习过程,包括失败的经验和有效的技术方法;
总结主要结果并规划未来设想(如果有的话)。
步骤 8:将模型投入生产并监测模型
如果你的项目需要在实时数据上进行测试,你应该创建一个可以在所有平台(web、android、iOS)上使用的网页版应用或 REST API。主要步骤包括:
在 h5 或 pickle 文件中保存你最终的训练模型;
提供网页版模型应用,你可以使用 Flask 来开发这些网页服务;
关联输入数据源并设置 ETL 路径;
基于扩展需求,用 pipenv、docker/Kubernetes 管理依赖关系;
你可以使用亚马逊、Azure 或者谷歌云平台来部署你的服务;
在实时数据上监测性能或让人们在你的模型上方便地使用他们的数据。
最后,创建任务清单时需要注意的一点是:你可以根据项目的难易程度来对清单进行实时调整。