数据准备最常见的方法是研究一个数据集,审查机器学习算法的期望,然后仔细选择最合适的数据准备技术来转换原始数据,以最好地满足算法的期望。这是缓慢的,昂贵的,并且需要大量的专业知识。
数据准备的另一种方法是并行地对原始数据应用一套通用和常用的数据准备技术,并将所有转换的结果合并到一个大数据集中,从中可以拟合和评估模型。
这是数据准备的另一种哲学,它将数据转换视为一种从原始数据中提取显著特征的方法,从而将问题的结构暴露给学习算法。它需要学习加权输入特征可伸缩的算法,并使用那些与被预测目标最相关的输入特征。
这种方法需要较少的专业知识,与数据准备方法的全网格搜索相比,在计算上是有效的,并且可以帮助发现非直观的数据准备解决方案,为给定的预测建模问题取得良好或最好的性能。
在本文中,我们将介绍如何使用特征提取对表格数据进行数据准备。
特征提取为表格数据的数据准备提供了另一种方法,其中所有数据转换都并行应用于原始输入数据,并组合在一起以创建一个大型数据集。
如何使用特征提取方法进行数据准备,以提高标准分类数据集的基准性能。。
如何将特征选择添加到特征提取建模管道中,以进一步提升标准数据集上的建模性能。
本文分为三个部分:
一、特征提取技术的数据准备
二、数据集和性能基准
- 葡萄酒分类数据集
- 基准模型性能
三、特征提取方法进行数据准备
特征提取技术的数据准备
数据准备可能具有挑战性。
最常用和遵循的方法是分析数据集,检查算法的要求,并转换原始数据以最好地满足算法的期望。
这可能是有效的,但也很慢,并且可能需要数据分析和机器学习算法方面的专业知识。
另一种方法是将输入变量的准备视为建模管道的超参数,并在选择算法和算法配置时对其进行调优。
尽管它在计算上可能会很昂贵,但它也可能是暴露不直观的解决方案并且只需要很少的专业知识的有效方法。
在这两种数据准备方法之间寻求合适的方法是将输入数据的转换视为特征工程或特征提取过程。这涉及对原始数据应用一套通用或常用的数据准备技术,然后将所有特征聚合在一起以创建一个大型数据集,然后根据该数据拟合并评估模型。
该方法的原理将每种数据准备技术都视为一种转换,可以从原始数据中提取显著特征,以呈现给学习算法。理想情况下,此类转换可解开复杂的关系和复合输入变量,进而允许使用更简单的建模算法,例如线性机器学习技术。
由于缺乏更好的名称,我们将其称为“ 特征工程方法 ”或“ 特征提取方法 ”,用于为预测建模项目配置数据准备。
它允许在选择数据准备方法时使用数据分析和算法专业知识,并可以找到不直观的解决方案,但计算成本却低得多。
输入特征数量的排除也可以通过使用特征选择技术来明确解决,这些特征选择技术尝试对所提取的大量特征的重要性或价值进行排序,并仅选择与预测目标最相关的一小部分变量。
我们可以通过一个可行的示例探索这种数据准备方法。
在深入研究示例之前,让我们首先选择一个标准数据集并制定性能基准。
数据集和性能基准
我们将首先选择一个标准的机器学习数据集,并为此数据集建立性能基准。这将为探索数据准备的特征提取方法提供背景。
葡萄酒分类数据集
我们将使用葡萄酒分类数据集。
该数据集具有13个输入变量,这些变量描述了葡萄酒样品的化学成分,并要求将葡萄酒分类为三种类型之一。
该示例加载数据集并将其拆分为输入和输出列,然后汇总数据数组。
- # example of loading and summarizing the wine dataset
- from pandas import read_csv
- # define the location of the dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv'
- # load the dataset as a data frame
- df = read_csv(url, header=None)
- # retrieve the numpy array
- data = df.values
- # split the columns into input and output variables
- X, y = data[:, :-1], data[:, -1]
- # summarize the shape of the loaded data
- print(X.shape, y.shape)
- #(178, 13) (178,)
通过运行示例,我们可以看到数据集已正确加载,并且有179行数据,其中包含13个输入变量和一个目标变量。
接下来,让我们在该数据集上评估一个模型,并建立性能基准。
基准模型性能
通过评估原始输入数据的模型,我们可以为葡萄酒分类任务建立性能基准。
在这种情况下,我们将评估逻辑回归模型。
首先,如scikit-learn库所期望的,我们可以通过确保输入变量是数字并且目标变量是标签编码来执行最少的数据准备。
- # minimally prepare dataset
- X = X.astype('float')
- y = LabelEncoder().fit_transform(y.astype('str'))
接下来,我们可以定义我们的预测模型。
- # define the model
- model = LogisticRegression(solver='liblinear')
我们将使用重复分层k-fold交叉验证的标准(10次重复和3次重复)来评估模型。
模型性能将用分类精度来评估。
- model = LogisticRegression(solver='liblinear')
- # define the cross-validation procedure
- cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
- # evaluate model
- scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
在运行结束时,我们将报告所有重复和评估倍数中收集的准确性得分的平均值和标准偏差。
- # report performance
- print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
结合在一起,下面列出了在原酒分类数据集上评估逻辑回归模型的完整示例。
- # baseline model performance on the wine dataset
- from numpy import mean
- from numpy import std
- from pandas import read_csv
- from sklearn.preprocessing import LabelEncoder
- from sklearn.model_selection import RepeatedStratifiedKFold
- from sklearn.model_selection import cross_val_score
- from sklearn.linear_model import LogisticRegression
- # load the dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv'
- df = read_csv(url, header=None)
- data = df.values
- X, y = data[:, :-1], data[:, -1]
- # minimally prepare dataset
- X = X.astype('float')
- y = LabelEncoder().fit_transform(y.astype('str'))
- # define the model
- model = LogisticRegression(solver='liblinear')
- # define the cross-validation procedure
- cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
- # evaluate model
- scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
- # report performance
- print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
- #Accuracy: 0.953 (0.048)
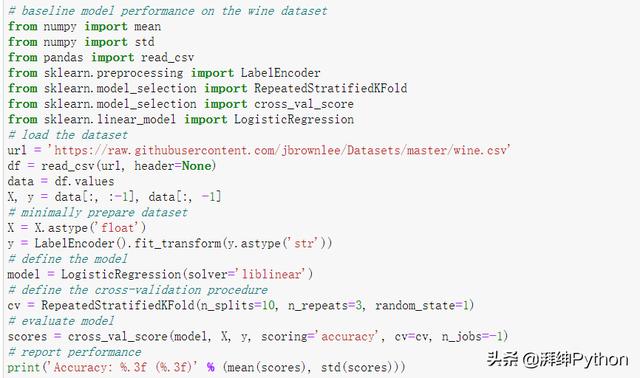
通过运行示例评估模型性能,并报告均值和标准差分类准确性。
考虑到学习算法的随机性,评估程序以及机器之间的精度差异,您的结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到,对原始输入数据进行的逻辑回归模型拟合获得了约95.3%的平均分类精度,为性能提供了基准。
接下来,让我们探讨使用基于特征提取的数据准备方法是否可以提高性能。
特征提取方法进行数据准备
第一步是选择一套通用且常用的数据准备技术。
在这种情况下,假设输入变量是数字,我们将使用一系列转换来更改输入变量的比例,例如MinMaxScaler,StandardScaler和RobustScaler,以及使用转换来链接输入变量的分布,例如QuantileTransformer和KBinsDiscretizer。最后,我们还将使用转换来消除输入变量(例如PCA和TruncatedSVD)之间的线性相关性。
FeatureUnion类可用于定义要执行的转换列表,这些转换的结果将被聚合在一起。这将创建一个具有大量列的新数据集。
列数的估计将是13个输入变量乘以五次转换或65次再加上PCA和SVD维数降低方法的14列输出,从而得出总共约79个特征。
- # transforms for the feature union
- transforms = list()
- transforms.append(('mms', MinMaxScaler()))
- transforms.append(('ss', StandardScaler()))
- transforms.append(('rs', RobustScaler()))
- transforms.append(('qt', QuantileTransformer(n_quantiles=100, output_distribution='normal')))
- transforms.append(('kbd', KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform')))
- transforms.append(('pca', PCA(n_components=7)))
- transforms.append(('svd', TruncatedSVD(n_components=7)))
- # create the feature union
- fu = FeatureUnion(transforms)

然后,我们可以使用FeatureUnion作为第一步,并使用Logistic回归模型作为最后一步来创建建模管道。
- # define the model
- model = LogisticRegression(solver='liblinear')
- # define the pipeline
- steps = list()
- steps.append(('fu', fu))
- steps.append(('m', model))
- pipeline = Pipeline(steps=steps)
然后可以像前面一样使用重复的分层k-fold交叉验证来评估管道。
下面列出了完整的示例。
- # data preparation as feature engineering for wine dataset
- from numpy import mean
- from numpy import std
- from pandas import read_csv
- from sklearn.model_selection import RepeatedStratifiedKFold
- from sklearn.model_selection import cross_val_score
- from sklearn.linear_model import LogisticRegression
- from sklearn.pipeline import Pipeline
- from sklearn.pipeline import FeatureUnion
- from sklearn.preprocessing import LabelEncoder
- from sklearn.preprocessing import MinMaxScaler
- from sklearn.preprocessing import StandardScaler
- from sklearn.preprocessing import RobustScaler
- from sklearn.preprocessing import QuantileTransformer
- from sklearn.preprocessing import KBinsDiscretizer
- from sklearn.decomposition import PCA
- from sklearn.decomposition import TruncatedSVD
- # load the dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv'
- df = read_csv(url, header=None)
- data = df.values
- X, y = data[:, :-1], data[:, -1]
- # minimally prepare dataset
- X = X.astype('float')
- y = LabelEncoder().fit_transform(y.astype('str'))
- # transforms for the feature union
- transforms = list()
- transforms.append(('mms', MinMaxScaler()))
- transforms.append(('ss', StandardScaler()))
- transforms.append(('rs', RobustScaler()))
- transforms.append(('qt', QuantileTransformer(n_quantiles=100, output_distribution='normal')))
- transforms.append(('kbd', KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform')))
- transforms.append(('pca', PCA(n_components=7)))
- transforms.append(('svd', TruncatedSVD(n_components=7)))
- # create the feature union
- fu = FeatureUnion(transforms)
- # define the model
- model = LogisticRegression(solver='liblinear')
- # define the pipeline
- steps = list()
- steps.append(('fu', fu))
- steps.append(('m', model))
- pipeline = Pipeline(steps=steps)
- # define the cross-validation procedure
- cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
- # evaluate model
- scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
- # report performance
- print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
- #Accuracy: 0.968 (0.037)
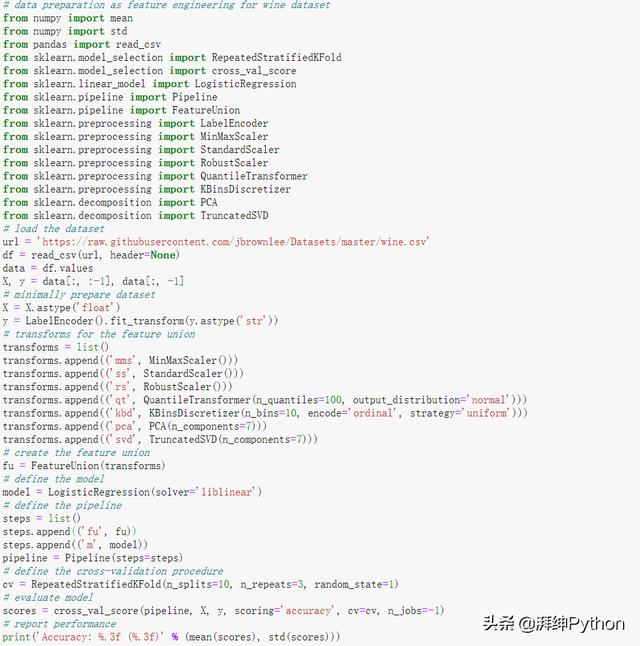
通过运行示例评估模型性能,并报告均值和标准差分类准确性。
考虑到学习算法的随机性,评估程序以及机器之间的精度差异,您的结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到性能相对于基准性能有所提升,实现了平均分类精度约96.8%。
尝试向FeatureUnion添加更多数据准备方法,以查看是否可以提高性能。
我们还可以使用特征选择将大约80个提取的特征缩减为与模型最相关的特征的子集。除了减少模型的复杂性之外,它还可以通过删除不相关和冗余的输入特征来提高性能。
在这种情况下,我们将使用递归特征消除(RFE)技术进行特征选择,并将其配置为选择15个最相关的特征。
- # define the feature selection
- rfe = RFE(estimator=LogisticRegression(solver='liblinear'), n_features_to_select=15)
然后我们可以将RFE特征选择添加到FeatureUnion算法之后和LogisticRegression算法之前的建模管道中。
- # define the pipeline
- steps = list()
- steps.append(('fu', fu))
- steps.append(('rfe', rfe))
- steps.append(('m', model))
- pipeline = Pipeline(steps=steps)
将这些结合起来,下面列出了特征选择的特征选择数据准备方法的完整示例。
- # data preparation as feature engineering with feature selection for wine dataset
- from numpy import mean
- from numpy import std
- from pandas import read_csv
- from sklearn.model_selection import RepeatedStratifiedKFold
- from sklearn.model_selection import cross_val_score
- from sklearn.linear_model import LogisticRegression
- from sklearn.pipeline import Pipeline
- from sklearn.pipeline import FeatureUnion
- from sklearn.preprocessing import LabelEncoder
- from sklearn.preprocessing import MinMaxScaler
- from sklearn.preprocessing import StandardScaler
- from sklearn.preprocessing import RobustScaler
- from sklearn.preprocessing import QuantileTransformer
- from sklearn.preprocessing import KBinsDiscretizer
- from sklearn.feature_selection import RFE
- from sklearn.decomposition import PCA
- from sklearn.decomposition import TruncatedSVD
- # load the dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv'
- df = read_csv(url, header=None)
- data = df.values
- X, y = data[:, :-1], data[:, -1]
- # minimally prepare dataset
- X = X.astype('float')
- y = LabelEncoder().fit_transform(y.astype('str'))
- # transforms for the feature union
- transforms = list()
- transforms.append(('mms', MinMaxScaler()))
- transforms.append(('ss', StandardScaler()))
- transforms.append(('rs', RobustScaler()))
- transforms.append(('qt', QuantileTransformer(n_quantiles=100, output_distribution='normal')))
- transforms.append(('kbd', KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform')))
- transforms.append(('pca', PCA(n_components=7)))
- transforms.append(('svd', TruncatedSVD(n_components=7)))
- # create the feature union
- fu = FeatureUnion(transforms)
- # define the feature selection
- rfe = RFE(estimator=LogisticRegression(solver='liblinear'), n_features_to_select=15)
- # define the model
- model = LogisticRegression(solver='liblinear')
- # define the pipeline
- steps = list()
- steps.append(('fu', fu))
- steps.append(('rfe', rfe))
- steps.append(('m', model))
- pipeline = Pipeline(steps=steps)
- # define the cross-validation procedure
- cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
- # evaluate model
- scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
- # report performance
- print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
- #Accuracy: 0.989 (0.022)
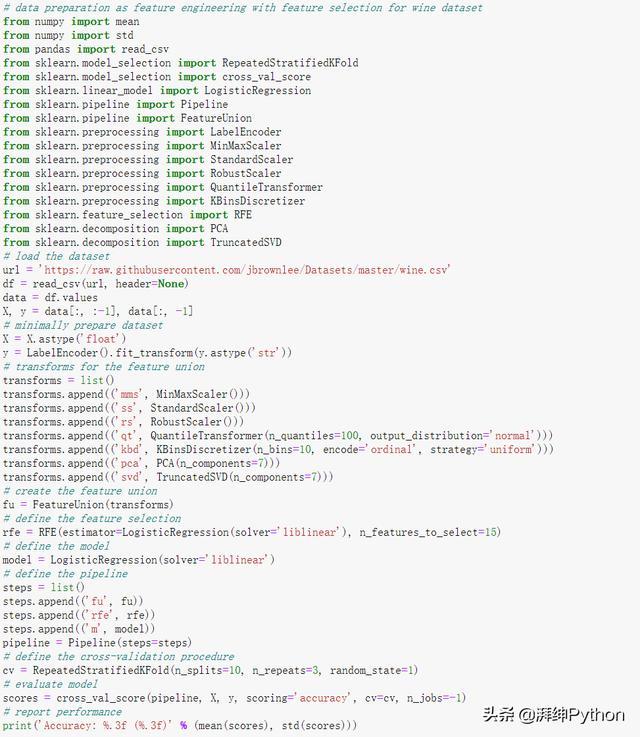
运行实例评估模型的性能,并报告均值和标准差分类精度。
由于学习算法的随机性、评估过程以及不同机器之间的精度差异,您的结果可能会有所不同。试着运行这个例子几次。
再一次,我们可以看到性能的进一步提升,从所有提取特征的96.8%提高到建模前使用特征选择的98.9。