












在进行数据分析时,我们所用到的数据往往都不是一维的,而这些数据在分析时难度就增加了不少,因为我们需要考虑维度之间的关系。而这些维度关系的分析就需要用一些方法来进行衡量,相关性分析就是其中一种。本文就用python来解释一下数据的相关性分析。
在进行相关性分析之前需要介绍几个概念,一是维度,二是协方差,三是相关系数。首先来看维度,以图1为例,这是一个员工信息统计表,这里有n个员工,分别是员工1、员工2、......、员工n,每个员工有5个属性,分别是身高、体重、年龄、工龄和学历。每个员工的信息都是一个观测,也叫一个样品,本文就统称观测,每个员工的一个属性叫一个指标,也叫变量、维度或者属性,本文统称维度。所以这个图中就有n个观测和5个维度。
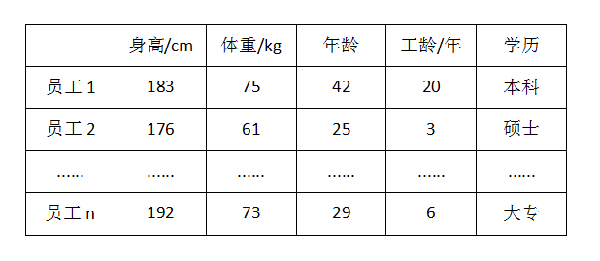
图1. 员工信息表
而协方差的定义就是E{ [ X - E(X) ] [ Y - E(Y) ] },记作Cov(X, Y),也就是两个维度与各自期望之差的乘积的期望,期望在离散型数据中通常是均值,比如图1中身高代表X,体重代表Y,E(X)就是身高的均值,E(Y)就是体重的均值,在利用二者分别和E(X)与E(Y)的差求协方差。而相关系数就是Cov(X, Y)/[σ(X)σ(Y)],记作ρXY,其中σ(X)和σ(Y)分别表示X和Y的标准差,所以相关系数就是两个变量的协方差除以其标准差之积。类似的,假如某个观测有p个维度,计算每个维度同所有维度之间的协方差,则会形成一个pxp的矩阵,矩阵的每个数是其相应维度之间的协方差,这个矩阵就称为协方差矩阵,协方差矩阵按照上面的方法再进一步计算就可得到相关关系矩阵。
下面就以python代码来解释一下相关性分析。
首先是数据集,本文用的数据来自绘图库seaborn自带的数据,是非常著名的鸢尾花的数据,获取方式非常简单,执行下面代码即可。这里有一个问题要提示一下,部分人在load_dataset时会出错,无法读取数据,是因为iris这个数据集不存在,这可能是因为seaborn版本的问题,如果遇到这种情况,可以去seaborn的GitHub数据网站自行下载数据,网址是https://github.com/mwaskom/seaborn-data,把下载的数据解压到seaborn-data文件夹即可,这个文件夹一般在seaborn安装目录下或者是当前工作目录下。
import seaborn as sns
data = sns.load_dataset('iris')
df = data.iloc[:, :4] #取前四列数据
- 1.
- 2.
- 3.
这次用到的数据集共有150行、5列,我们只用到前4列数据。数据集样例如图2所示。
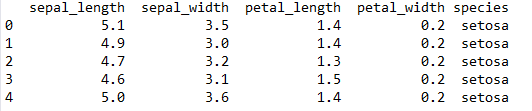
图2. 数据集样例
接下来我们来进行相关性分析。
首先来做一个比较简单的分析,即分析这个数据集中第1列和第3列的相关性,也就是sepal_length和petal_length这两列之间的关系。这里我们可以用numpy、scipy和pandas三种方法。首先是numpy。
import numpy as np
X = df['sepal_length']
Y = df['petal_length']
result1 = np.corrcoef(X, Y)
- 1.
- 2.
- 3.
- 4.
得到的result1结果就是一个二维矩阵,如图3所示。
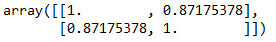
图3. result1计算结果
其中矩阵主对角线上的数值都为1(主对角线就是从左上角到右下角的那条斜线),这是因为主对角线的数值都是每个观测与自己的相关性,所以都是1,毕竟X=1X,Y=1Y,每个观测都等于1乘以自身。而图3中其他不为1的数字就是相关关系数值,一共有两个,这两个值相等,因为这两个值分别表示ρXY和ρYX,其值相等。同理我们可以求df中4个维度的相关关系,代码如下,这里rowvar代表以列为维度。
result2 = np.corrcoef(df, rowvar=False)
- 1.
其结果如图4所示。
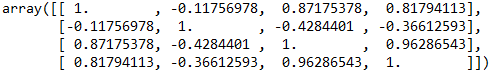
图4. result2计算结果
图4是一个4x4的矩阵,共16个数据,代表每个维度同其他维度的相关关系(也包括每个维度与其自身),主对角线为1,其他数字关于主对角线对称,是一个对称矩阵。
接下来我们用scipy进行分析。代码如下。
import scipy.stats as ss
result3 = ss.pearsonr(X, Y)
- 1.
- 2.
这个结果是(0.8717537758865831, 1.0386674194498099e-47),其返回的是两个数,第一个数是X和Y的相关关系数值,其值和前面numpy的计算结果相同,第二个是两者不相关的概率,也就是我们统计学中常说的p值,但这个值是指不相关的概率,也就是值越小,代表越相关,我们这里的数值非常小,代表二者的线性相关程度比较大。当然如果相关关系数值为1,则p值为0。scipy中没有计算相关矩阵的方法。
最后是pandas方法。
因为前面的df本身就是pandas的DataFrame格式,所以我们可以直接拿来用。代码如下。
result4 = X.corr(Y)
result5 = df.corr()
- 1.
- 2.
result4结果是0.8717537758865833,result5结果如图5所示。这两个结果和前面所得的结果相同。

图5. result5计算结果
接下来是作图。对于分析相关关系,一般有两种常见的图形,一种是散点图,一种是热力图。散点图中可以清晰看到各个坐标点的分布及趋势,对于数据分析者而言,其可以更直观地了解各个维度数据之间的关系,但这种方法也有缺点,即不适合大数据量,因为数据量太大,生成图片速度会很慢,同时图片太多不利于观察;而热力图则更多从数值或颜色方面,来准确描述各个维度的关系,其传递的信息较少,但比较适合大数据量。我们首先介绍一下散点图。
生成散点图可以用seaborn或者pandas。seaborn的代码如下。
sns.pairplot(df)
sns.pairplot(df , hue ='sepal_width');
- 1.
- 2.
第一行代码结果如图6所示,是一张大图,其中包含16个子图,每个子图都是每个维度和其他某个维度的相关关系图,这其中主对角线上的图,则是每个维度的数据分布直方图。而第二行代码是画出同样的图形,但却以sepal_width这个维度的数据为标准,来对各个数据点进行着色,其结果如图7所示。从图中可以看出,sepal_width这列数据共23个不同的数值,每个数值一种颜色,所以生成的图是彩色的。
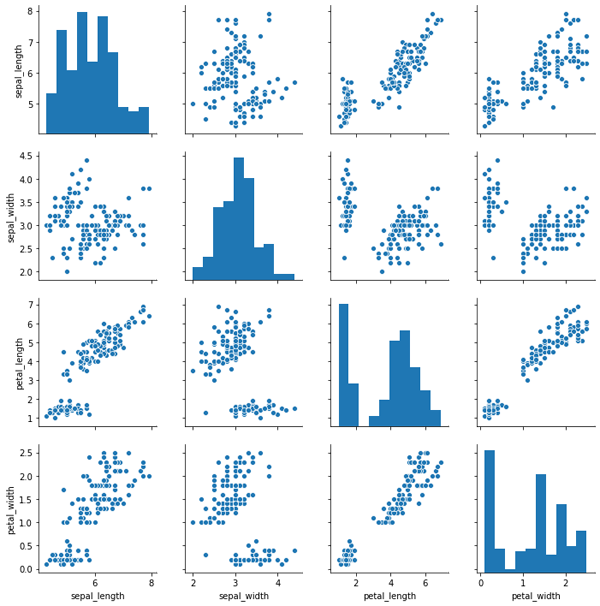
图6. seaborn绘制的普通相关关系图
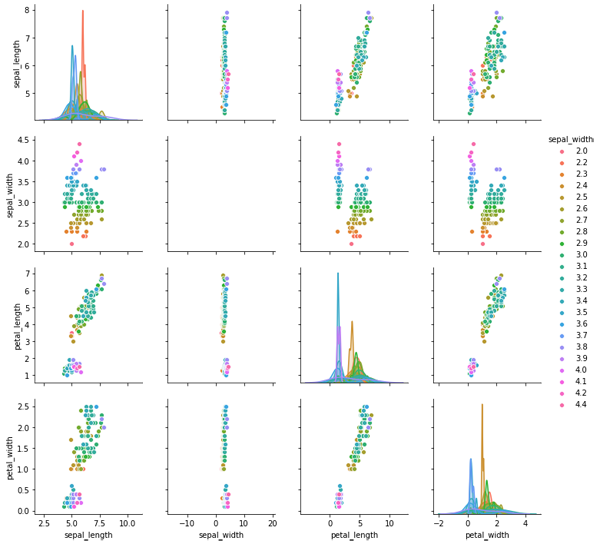
图7. seaborn绘制的以某列数据为基准的相关关系图
而另外一种绘图方法是用pandas,其代码如下。
import pandas as pd
pd.plotting.scatter_matrix(df, figsize=(12,12),range_padding=0.5);
- 1.
- 2.
结果如图8所示,可以看到用pandas绘制的图和seaborn的大体结果一样,但图片的可定制程度和精细度还是略差一些,所以一般情况下建议用seaborn。
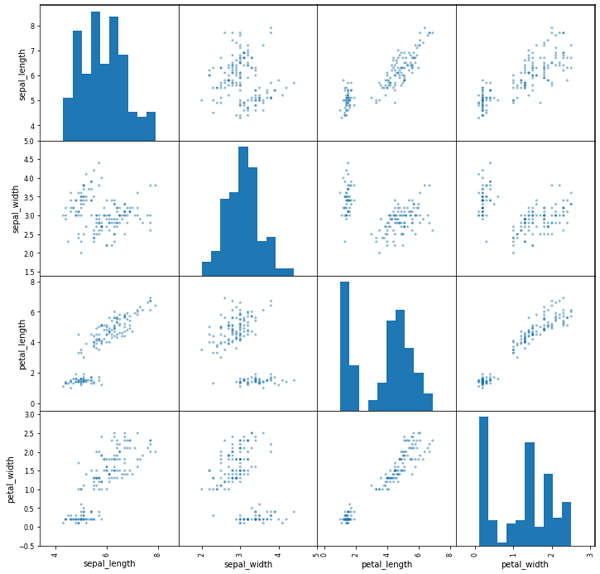
图8. pandas生成的相关关系图
最后就是热力图。其代码如下。
import matplotlib.pyplot as plt
figure, ax = plt.subplots(figsize=(12, 12))
sns.heatmap(df.corr(), square=True, annot=True, axax=ax)
- 1.
- 2.
- 3.
刚开始写这段代码时还出现了一个小问题,如图9所示。图9当中第一行和最后一行的子图只显示了一部分,而其他子图都是完整显示,这是matplotlib的一个bug,因为seaborn是基于matplotlib的库,所以只要升级matplotlib就行了,刚开始笔者的matplotlib版本是3.1.1,现在已升级到3.2.2,这个bug已经被修复。正常图如图10所示。第二行代码中square=True表示每个子图是否以正方形显示,这里设置为True,annot=True则表示是否在图中显示每个子图的数值,这里同样设置为True。
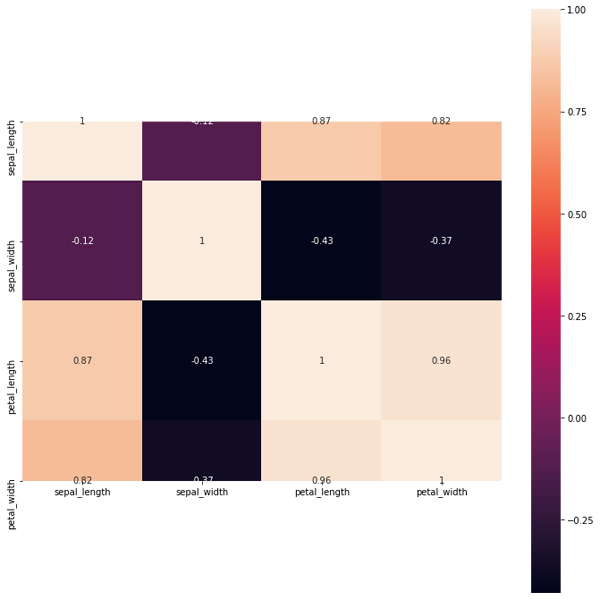
图9. 老版本matplotlib生成的热力图
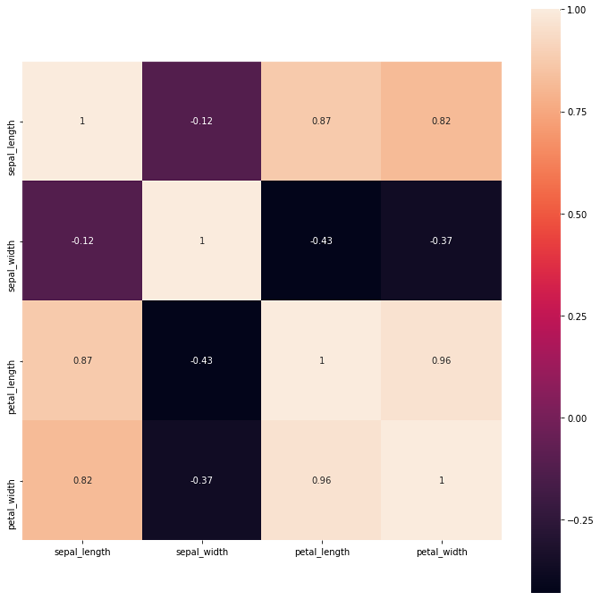
图10. 新版本matplotlib生成的热力图
本文从数据计算到可视化,介绍了用python求多维数据间的相关关系的多种方法,我们可以根据自己的需求来选择对应的方法。
作者简介:Mort,数据分析爱好者,擅长数据可视化,比较关注机器学习领域,希望能和业内朋友多学习交流。

















