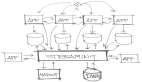
缓存雪崩
我们多次提到了「cache miss」这个词,利用「cache miss」来更好的保障DB和缓存之间的数据一致性。
然而,任何事物都是有两面性的,「cache miss」在提供便利的同时,也带来了一个潜在风险。
这个风险就是「缓存雪崩」。
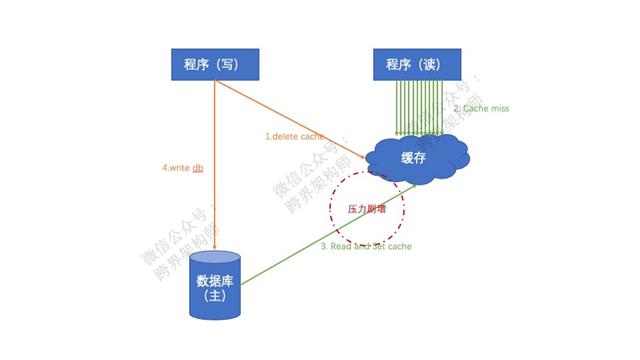
在图中的第二步,大量的请求并发进入,这里的一次「cache miss」就有可能导致产生「缓存雪崩」。
不过,虽然「cache miss」会产生「缓存雪崩」,但「缓存雪崩」并不仅仅产生于「cache miss」。
雪崩一词源于「雪崩效应」,是指像「多米勒骨牌」这样的级联反应。前面没顶住,导致影响后面,如此蔓延。(关于对应雪崩的方式参考之前的文章,文末放链接)
所以「缓存雪崩」的根本问题是:缓存由于某些原因未起到预期的缓冲效果,导致请求全部流转到数据库,造成数据库压力过重。
因此,流量激增、高并发下的缓存过期、甚至缓存系统宕机都有可能产生「缓存雪崩」问题。
怎么解决这个问题呢?宕机可以通过做高可用来解决(可以参考之前的文章,文末放链接)。而在“流量激增”、“高并发下的缓存过期”这两种场景下,也有两种方式可以来解决。
加锁排队
通过加锁或者排队机制来限制读数据库写缓存的线程数量。比如,下面的伪代码就是对某个key只允许一个线程进入的效果。
key = "aaa";
var cacheValue = cache.read(key);
if (cacheValue != null) {
return cacheValue;
}
else {
lock(key) {
cacheValue = cache.read(key);
if (cacheValue != null) {
return cacheValue;
}
else {
cacheValue = db.read(key);
cache.set(key,cacheValue);
}
}
return cacheValue;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
这个比较好理解,就不废话了。
缓存时间增加随机值
这个主要针对的是「缓存定时过期」机制下的取巧方案。它的目的是避免多个缓存key在同一时间失效,导致压力更加集中。
比如,你有10个key,他们的过期时间都是30分钟的话,那么30分钟后这10个key的所有请求会同时流到db去。
而这里说的这种方式就是将这10个key的过期时间打乱,比如设置成25、26、27、...、34分的过期时间,这样压力就被分散了,每分钟只有一个key过期。
最简单粗暴的方式就是在设置「过期时间」的时候加一个随机数字。
cache.set(key,cacheValue,30+random())
总体来看,相比后者,前者的适用面更广,所以Z哥建议你用「加锁排队」作为默认的通用方案不失为一个不错的选择。
「缓存穿透」、「缓存雪崩」傻傻分不清楚?
如果你听说过「缓存穿透」的话,可能会问:「缓存雪崩」和「缓存穿透」一样吗?
从产生的效果上看是一样的,但是过程不同。
来举个例子。例子纯属虚构,别太在意合理性。
在一个方圆一万里的地区内,只有一个修手机的老师傅。他收了一个徒弟,希望徒弟能帮他分担掉一部分的工作压力。这里的老师傅可以看作是DB,徒弟看作是缓存。
老师傅对徒弟说,如果遇到你不会做的事你来请教我。
然后,一个客户过来说要修一下他的卫星电话,徒弟去请教老师傅,老师傅说他也不会,先拒绝了吧。
但是由于没告诉他后续遇到修卫星电话的人该怎么做,所以后续这个客户一直来问,徒弟每次都又去请教老师傅。最终,在修卫星电话这件事上,徒弟并没有帮老师傅缓解任何的压力,快被烦死了。
上面这个故事就好比「缓存穿透」。
而「缓存雪崩」则是,由于徒弟年轻力壮,精力充沛,1小时能修20个手机,老师傅只能修10个(但是手艺好,更考究)。
然后,有一天徒弟请假了,但恰巧这天来了2000个修手机的,老师傅修不过来就被累垮了。
所以,「缓存穿透」和「缓存雪崩」最终产生的效果是一样的,就是因为大量请求流到DB后,把DB拖垮(正如前面故事中的老师傅)。
两者最大的不同在于,「缓存雪崩」问题只要数据从db中找到并放入缓存就能恢复正常(徒弟休假归来),而「缓存穿透」指的是所需的数据在DB中一直不存在的情况(老师傅也不会修)。并且,由于DB中数据不存在,所以自然每次从缓存中也找不到(徒弟也不会修)。
清楚了两者的区别之后,我们下面就来聊聊「缓存穿透」的常见应对方式。
缓存穿透
「缓存穿透」有时也叫做「缓存击穿」,产生的逻辑过程是这样,一直在虚线范围内流转。
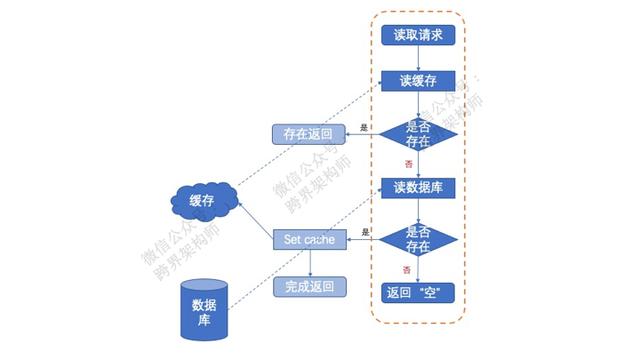
在这种场景下,缓存的作用完全失效,每次请求都“穿透”到了DB中。
可能你会想,为什么会存在大量的这种db中数据不存在的情况呢?其实,任何依赖外部参数进行查询的地方都可能有这个问题的存在。比如,一个文本输入框,本来是让你输入用户名的,但是手误输入了密码,自然就找不到数据咯。更主要的问题是,会有恶意分子利用这种机制来对你的系统进行攻击,击穿缓存搞垮你的数据库,导致整个系统全面瘫痪。
同样也有两种方式来解决这个问题。
布隆过滤器(bloomfilter)
布隆过滤器就是由一个很长的二进制向量和一系列随机映射函数组成,将确定不存在的数据构建到过滤器中,用它来过滤请求。这里就放个图,具体就不展开了,后续我们再聊(有兴趣的可以先到搜索引擎搜《Space time trade-offs in hash coding with allowable errors》找到bloom的原始论文)。
实现代码其实并不很复杂,参考论文或者网上其他作者的一些实现就可以写出来。
不过,布隆过滤器有一个最大的缺点,也是其为了高效利用内存而付出的代价,就是无法确保100%的准确率。
所以,如果你的场景要求是100%准确的,就只能用下面这种方式了。
缓存空对象
其实就是哪怕从db中取出的数据是“空(null)”,也把它丢失到缓存中。
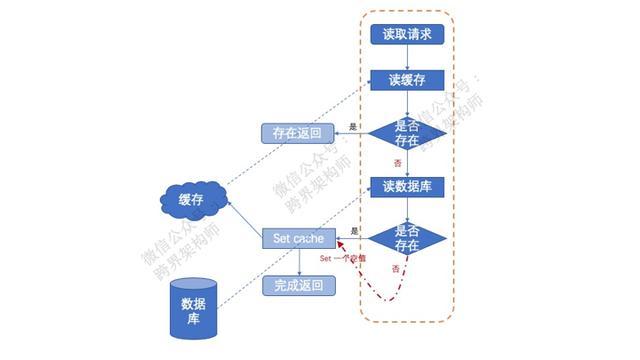
这样一来,虽然缓存中存在着一个value为空的数据,但是至少他能表示“数据库里也没有不用找了”。
其实这个思路和布隆过滤器有些类似,但是它对内存的消耗会大很多,毕竟布隆过滤器是利用的bit位来存储。不过这种方式的优势是前面提到的,不会出现误差,而布隆过滤器的错误率会随着「位数」的增加而减少,会不断趋近于0,但不会为0。
总结
好了,我们一起总结一下。
这次呢,Z哥主要和你聊了隐藏在缓存中的两颗具有“毁灭性”的种子,「缓存雪崩」和「缓存穿透」,以及应对这两颗种子的常用方式。
而且,顺便帮你区分清楚了「缓存雪崩」和「缓存穿透」的差异。
希望对你有所启发。