1.背景
计算、存储和网络是云时代的三大基础服务,作为新一代基础架构的 Kubernetes 也不例外。而这三者之中,网络又是一个最难掌握和最容易出问题的服务;本文通过对Kubernetes网络流量模型进行简单梳理,希望对初学者能够提供一定思路。先看一下kubernetes 总体模型:
容器网络中涉及的几个地址:
Node Ip:物理机地址。
POD Ip:Kubernetes的最小部署单元是Pod,一个pod 可能包含一个或多个容器,简单来讲容器没有自己单独的地址,他们共享POD 的地址和端口区间。
ClusterIp:Service的Ip地址,外部网络无法ping通改地址,因为它是虚拟IP地址,没有网络设备为这个地址负责,内部实现是使用Iptables规则重新定向到其本地端口,再均衡到后端Pod;只有Kubernetes集群内部访问使用。
Public Ip :Service对象在Cluster IP range池中分配到的IP只能在内部访问,适合作为一个应用程序内部的层次。如果这个Service作为前端服务,准备为集群外的客户提供业务,我们就需要给这个服务提供公共IP。
2.容器网络流量模型
容器网络至少需要解决如下几种场景的通信:①POD内容器间通信
②同主机POD间 通信
③跨主机POD间 通信
④集群内Service Cluster Ip和外部访问下面具体介绍实现方式
2.1 POD内容器间通信
Pod中的容器可以通过“localhost”来互相通信,他们使用同一个网络命名空间,对容器来说,hostname就是Pod的名称。Pod中的所有容器共享同一个IP地址和端口空间,你需要为每个需要接收连接的容器分配不同的端口。也就是说,Pod中的应用需要自己协调端口的使用。实验如下:首先我们创建一个Pod ,包含两个容器,容器参数如下:
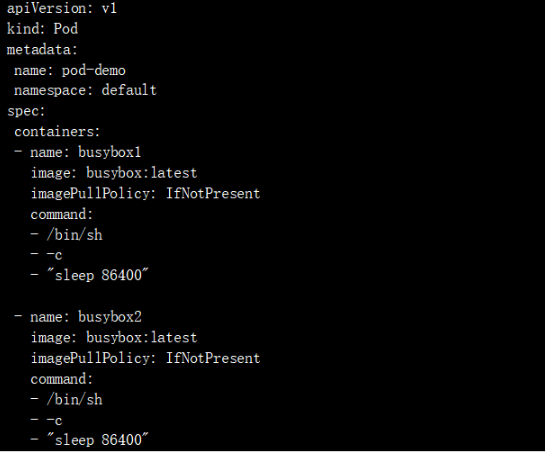
查看:

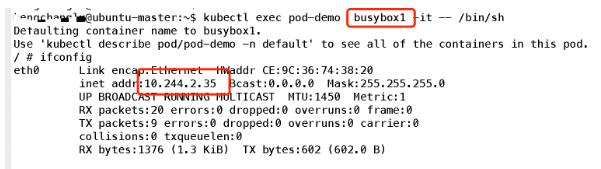
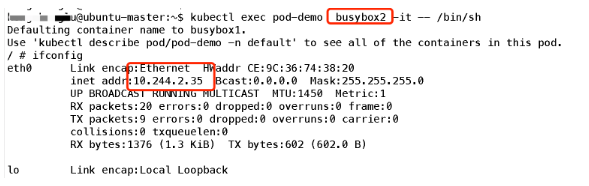
可以看到容器共享Pod 的地址,那么他们是否使用同一端口资源呢,我们可以简单实验一下:首先在容器1监听一个端口:

然后在容器2查看该端口是否被占用:

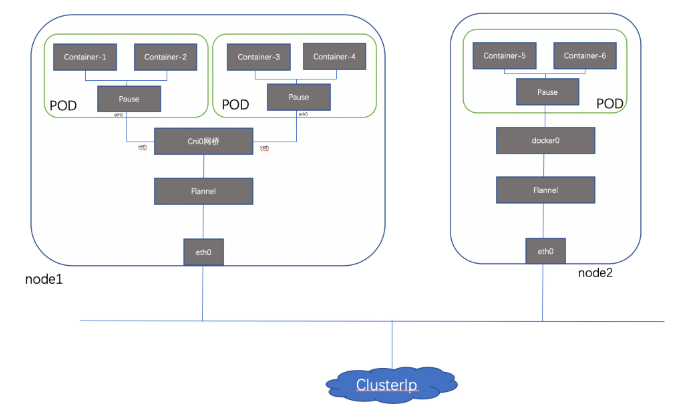
可见端口也是共享的;所以简单理解,可以把Pod看做一个小系统,容器当做系统中的不同进程;内部实现:同POD 内的容器实际共享同一个Namespace,因此使用相同的Ip和Port空间,该Namespace 是由一个叫Pause的小容器来实现,每当一个Pod被创建,那么首先创建一个pause容器, 之后这个pod里面的其他容器通过共享这个pause容器的网络栈,实现外部pod进行通信,因此对于同Pod里面的所有容器来说,他们看到的网络视图是一样的,我们在容器中看的地址,也就是Pod地址实际是Pause容器的IP地址。总体模型如下:
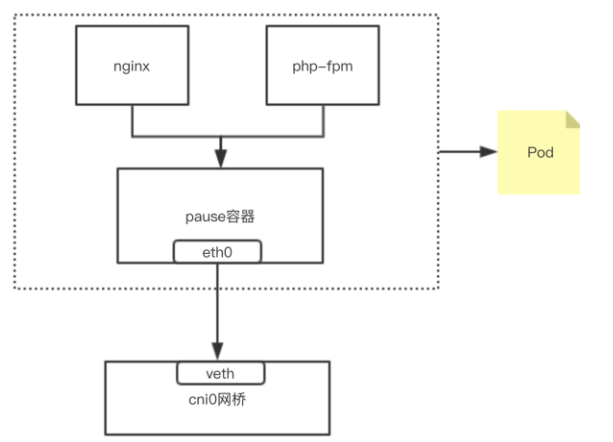
我们在node 节点查看之前创建的POD,可以看到该pause容器 :
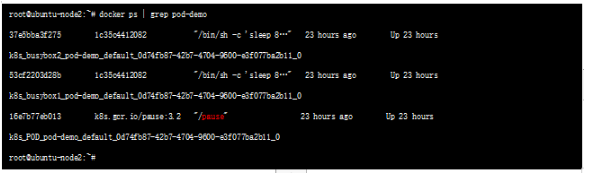
这种新创建的容器和已经存在的一个容器(pause)共享一个 Network Namespace(而不是和宿主机共享) 就是我们常说的container 模式。
2.2 同主机POD间通信
每个节点上的每个Pod都有自己的namespace,同主机上的POD之间怎么通信呢?我们可以在两个POD之间建立Vet Pair进行通信,但如果有多个容器,两两建立Veth 就会非常麻烦,假如有N 个POD ,那么我们需要创建n(n-1)/2个Veth Pair,扩展性非常差,如果我们可以将这些Veth Pair 连接到一个集中的转发点,由它来统一转发就就会非常便捷,这个集中转发点就是我们常说的bridge;如下所示(简单起见,这里把pause忽略):
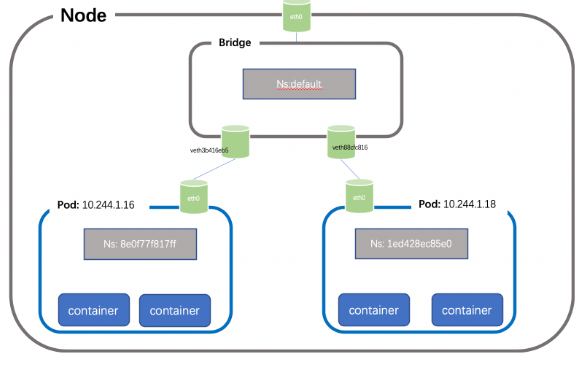
仍然以我们的测试环境为例,创建pod1 和pod2地址分别为:10.244.1.16、10.244.1.18,位于node1 节点
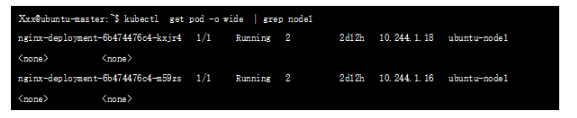
查看节点下的namespace:
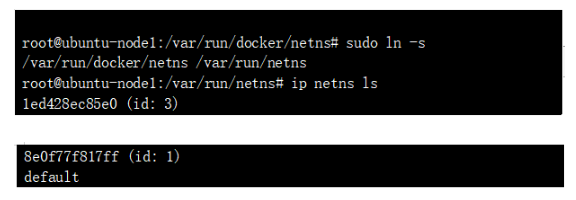
这两个NS就是上述两个POD 对应的namespace,查询对应namespace 下的接口:
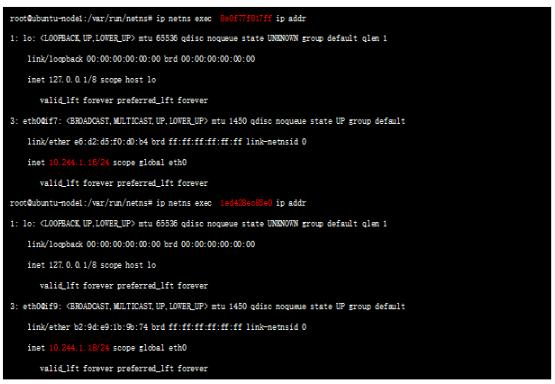
可以看到标红处的地址,实际就是POD 的ip地址;NS 和对应的POD 地址都找到了,那么如何确认这两个ns 下的虚接口的另一端呢? 比较直观的确认方式为:上述接口如 3: eth0@if7,表示本端接口id 为3 ,对端接口id是7,我们看下default namespace(我们平时看的默认都在default下) 的veth口:
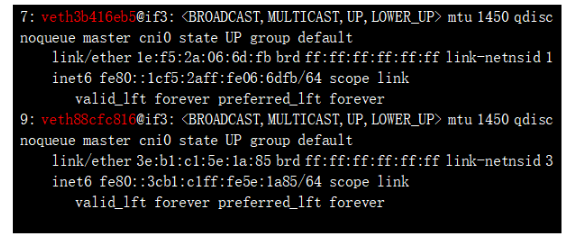
7: veth3b416eb5@if3 ,该接口的id 正是我们要找的id 为7的接口 ,是veth pair的另一端;
2.3 跨主机POD 间通信
简单来看,对于网络上两个端点之间的互通无非两种方案,一种是underlay 直接互通,那么就需要双方有彼此的路由信息并且该路由信息在underlay的路径上存在,一种是overlay 方案,通过隧道实现互通,underlay 层面保证主机可达即可,前者代表方案有 Calico(direct模式)和Macvlan,后者有Overlay,OVS,Flannel和Weave。我们取代表性的Flannel 和calico 插件进行介绍;
2.3.1 Flannel
总体通信流程如下:
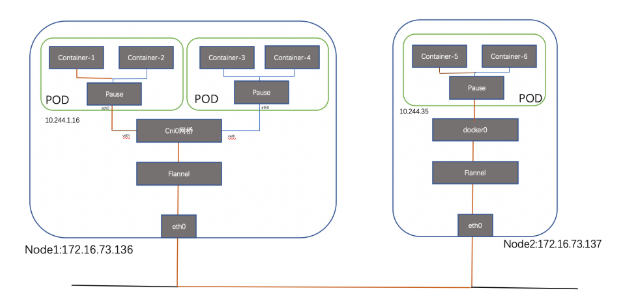
通信过程
2.3.1.1地址分配
flanneld第一次启动时,从 etcd 获取配置的 Pod 网段信息,为本节点分配一个未使用的地址段,然后创建 flannedl.1 网络接口(也可能是其它名称,如 flannel1 等),flannel 将分配给自己的 Pod 网段信息写入 /run/flannel/docker 文件(不同k8s版本文件名存在差异),docker 后续使用这个文件中的环境变量设置 docker0 网桥,从而使这个地址段为本节点的所有;
查看flannel 为docker 分配的地址段:

表示该节点创建的POD 地址都从10.244.1.1/24中分配,比如node1 节点的如下2个pod。

2.3.1.2路由下发
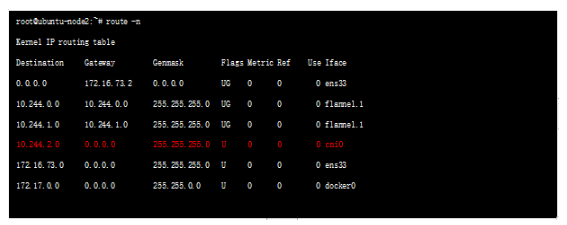
每台主机上,flannel 运行一个daemon 进程叫flanneld,它可以在内核中创建路由表,查看node1节点的路由表如下:
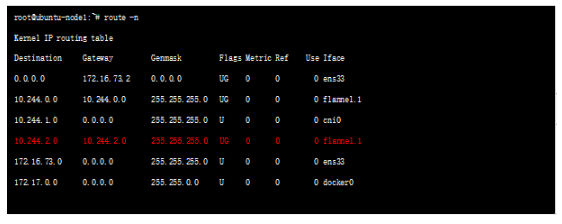
可以看到node2 节点的路由match 10.244.2.0 一行规则,出接口为flannel.1 口(接口名flannel后数字可能不一样) flannel.1 是flanneld程序创建的一个隧道口;这里有一个问题,就是如何判断隧道打到那里呢,很显然,flannld存储了类似容器-物理节点之间的映射关系,这种信息存放在etcd里面,flannld进程通过读取etcd中的映射关系信息,决定隧道外层封装。
2.3.1.3数据面封装
Flannel 知道外层封装地址后,对报文进行封装,源采用自己的物理ip 地址,目的采用对端的,vxlan 外层的udp port 8472(如果是UDP封装使用8285作为默认目的端口,下文会提到),对端只需监控port 即可,当改端口收到报文后将报文送到flannedld 进程,进程将报文送到flanned 接口接封装,然后查询本地路由表:
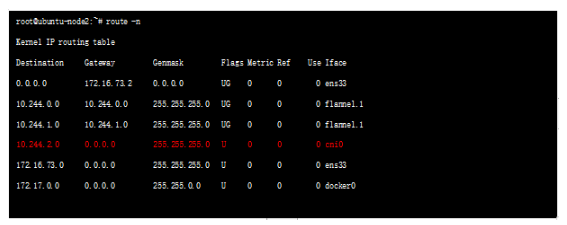
可以看到目的地址为cni0 ;Flannel功能内部支持三种不同后端实现,分别是:
Host-gw:需要两台host 在同一网段,不支持跨网,因此不适合大规模部署
UDP:不建议使用,除非内核不支持vxlan 或者debugg时候使用,当前也已经废弃;
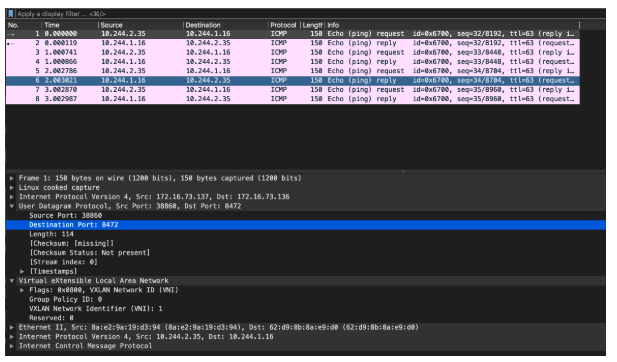
Vxlan : vxlan 封装,flannel 使用 vxlan 技术为各节点创建一个可以互通的 Pod 网络,使用的端口为 UDP 8472(需要开放该端口,如公有云 AWS 等)。
我们在node 节点进行抓包验证一下:
(注:因为在linux 环境中,Flannel的vxlan 封装中UDP 目的port 是 8472 ,标准Vxlan 报文的识别依据是目的端口4789,因此需要手动指定按照vxlan 来解析,否则无法识别内层信息)
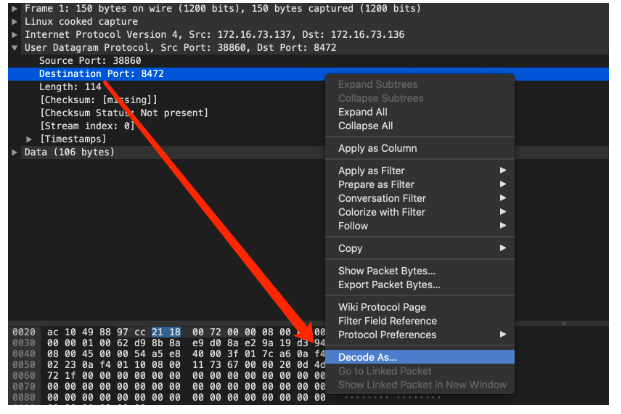

2.3.2 CalicoCalico支持3种路由模式:
Direct: 路由转发,报文不做封装;
Ip-In-Ip:Calico 默认的路由模式,数据面采用ipip封装;
Vxlan:vxlan 封装;
这里主要介绍Direct模式,采用软路由建立BGP 宣告容器网段,使得全网所有的Node和网络设备都有到彼此的路由的信息,然后直接通过underlay 转发。Calico实现的总体结构如下:
组件包含:
Felix:Calico agent:运行在每台node上,为容器设置网络信息:IP,路由规则,iptable规则等BIRD:
BGP Client:监听 Host上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉其他Host节点,从而实现网络互通
BGP Route Reflector: BGP peer建立方式多样,可以在node 之间两两建立bgp peer(默认模式),和传统ibgp peer问题类似,这会带来n*(n-1)/2 的邻居量,因此也可以自建RR 反射器(上图中结构),node 节点和RR 建立peer,当然node也可以和Tor 建peer,详细的组网讨论可以参考官网:
https://docs.projectcalico.org/reference/architecture/design/l3-interconnect-fabric
Calicoctl: calico命令行管理工具。
具体选择哪种peer方式没有固定标准,要适配总体网络规划,只要最终保证容器网络可正确发布到物理网络即可;
数据通信的流程为:数据包先从veth设备对另一口发出,到达宿主机上的Cali开头的虚拟网卡上,到达这一头也就到达了宿主机上的网络协议栈,然后查询路由表转发;因为本机通过bird 和RR 建立bgp 邻居关系,会将本地的容器地址发送到RR 从而反射到网络其它节点,同样,其它节点的网络地址也会传送到本地,然后由Felix 进程进行管理并下发到路由表中,报文匹配路由规则后正常进行转发即可(实际还有复杂的iptables 规则,这里不做展开)
下面通过简单实验学习下:
具体安装过程不再讨论,可参考官网:https://www.projectcalico.org/进行安装部署;
Node节点bgp配置如下:
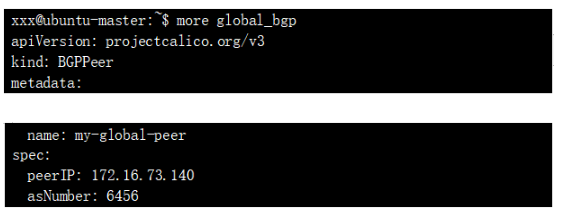
为了简化实验,我们再启用一台机器运行FRR 来充当RR(关于Frr参考官网https://frrouting.org/) ,RR配置如下:
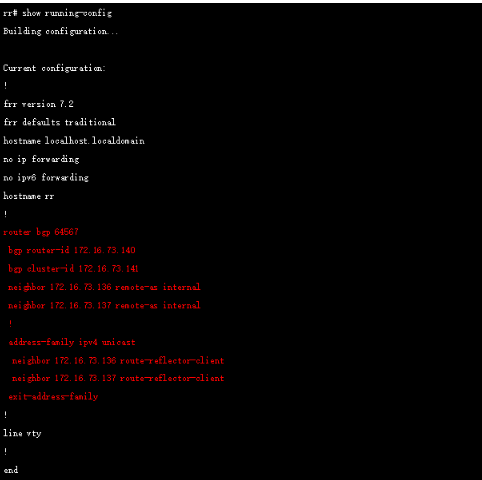
这样所有节点都和RR 建立了bgp 邻居,通过如下方式检查邻居状态:
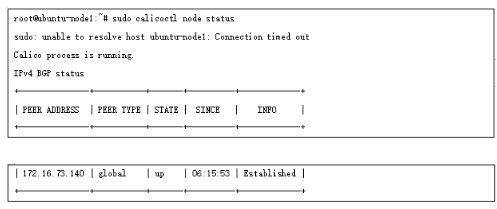
我们新建两个pod ,分别位于两个node节点:

默认情况下,当网络中出现第一个容器,calico会为容器分配一段子网(子网掩码/26),后续出现该节点上的pod都从这个子网中分配ip地址,这样做的好处是能够缩减节点上的路由表的规模.进入容器查看路由我们发现网关地址为169.254.1.1
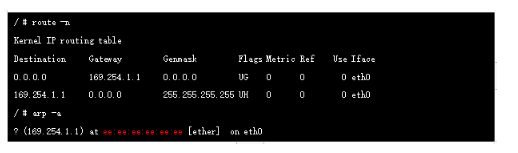
实际上在calico 网络中,容器网关始终是169.254.1.1,该地址在实际网络中不存在的,是直接进行的ARP 代理(ee:ee:ee:ee:ee:ee),我们在创建Pod的时候系统会在对应的node 上新增一个cali开头的虚拟网卡,它就是veth Pair的另一端(本端是容器本地eth0口),它的mac 就是上面的169.254.1.1 对应的mac地址
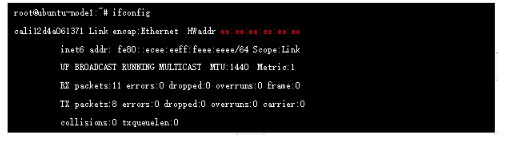
此时的报文已经进入default namespace ,这里开始查看路由表:
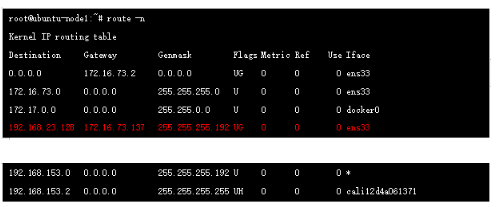
其中192.168.23.128/26 是node2上的地址空间,该路由由node2 节点bird发送到RR,RR 反射到node1节点的bird ,然后由felix来进行管理和下发到路由表中,我们可以在node1节点抓包进一步确认:
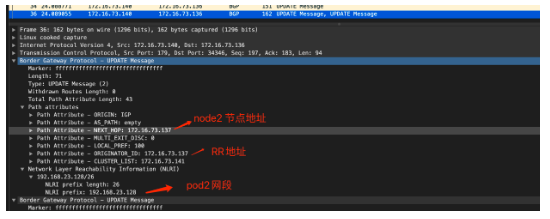
同时因为calico 的代理方式,使得同node的不同POD通信也比较特殊,它也是通过三层转发来实现,比如node2 节点的2个地址,在路由表中都是/32位存在,下一跳接口为veth-pair的一端,另一端就是对应的pod内接口;
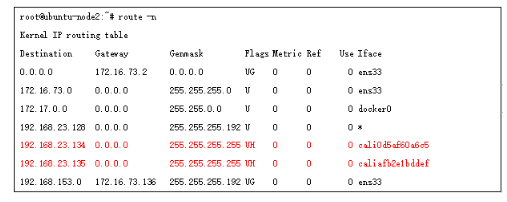
这和flannel 经过bridge 方式实现是不一样的;
2.3.3 总结
这里我们从网络角度对flannel 和calico 进行简单对比:
总体来看,对性能敏感、策略需求较高时偏向于Calio方案,否则的话,采用Flannel会是更好的选择;
2.4 Service 和外部通信
Serice 和外部通信场景实现涉及较多iptables 转发原理,限于篇幅这里不再展开,简单介绍如下:
Pod与service通信: Pod间可以直接通过IP地址通信,但前提是Pod知道对方的IP。在 Kubernetes集群中,Pod可能会频繁地销毁和创建,也就是说Pod的IP 不是固定的。为了解决这个问题,Service提供了访问Pod的抽象层。 无论后端的Pod如何变化,Service都作为稳定的前端对外提供服务。 同时,Service还提供了高可用和负载均衡功能,Service负责将请求转 给正确的Pod;
外部通信:无论是Pod的IP还是Service的Cluster IP,它们只能在Kubernetes集群中可见,对集群之外的世界,这些IP都是私有的Kubernetes提供了两种方式让外界能够与Pod通信:
NodePort:Service通过Cluster节点的静态端口对外提供服务, 外部可以通过:访问Service。
LoadBalancer:Service利用cloud provider提供的load balancer对外提供服务,cloud provider负责将load balancer 的流量导向Service。目前支持的cloud provider有GCP、AWS、 Azur等。
3.结语
容器网络场景复杂,涉及面广,希望一些心得体会可以给大家带来参考,错误之处还望指正。