












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
如何快速优雅地处理你的NLP数据集?
试试这款号称「从小白到大神」的Texthero的工具包。
不仅编写界面友好美观,而且功能全面,预处理、表征、可视化样样精通,在Reddit上17个小时内就获得了近1.1k的热度。
连刚脱机的NLP程序猿看了都想与数据集再战几回:

下面是Texthero的使用界面。
△ 优雅美观的NLP数据处理界面
事实上,Texthero的优雅绝不仅仅在于界面的友好,最关键的是,它省略了大量重复性代码编写工作。
只需要几行代码,Texthero就能帮你完成想要的数据预处理、表征、可视化等操作,极大程度上解放了你的双手。
来看看Texthero进行数据预处理、各种算法后的可视化效果。
效果展示
首先,进行文本清理,然后采用TF-IDF算法进行特征表示,并对此可视化:

PCA降维后的效果duangduang的:
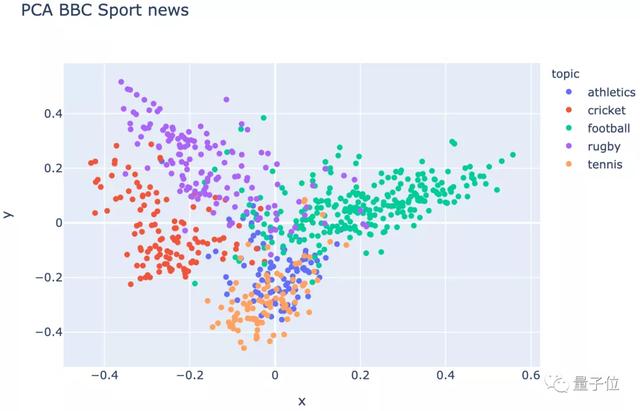
△ 进行文本清理和TF-IDF表征后的可视化效果
这不是你想要的?
那么,除了预处理和表征外,试试加上K均值聚类算法,并进行可视化:

效果如下:
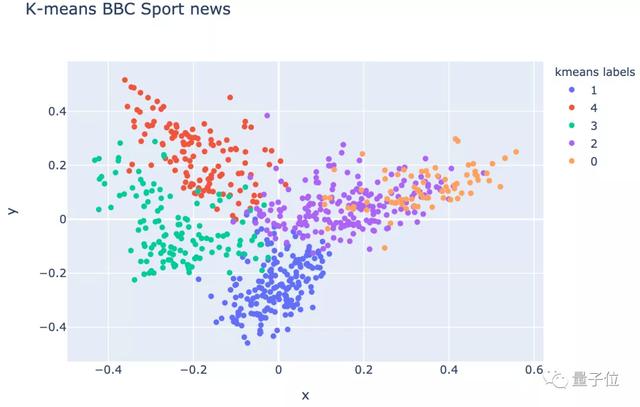
△ 进行预处理、表征和K均值聚类算法后的数据效果
经过K均值聚类算法处理后的结果一目了然。
不仅设计友好,加载代码后,结果会生成在在同一个界面上,整体逻辑流程显得非常明了。
△ 使用效果
从展示界面来看,Texthero只需要编写少量代码,就能得到你想要的结果,为数据处理省去了不少时间。
事实上,只要掌握基本使用逻辑,萌新也能快速上手这款NLP数据处理神器。
使用指南
pip一下texthero后(或从GitHub上直接下载工具包,文末附代码链接),采用import导入它和pandas:

之后,加载你需要处理的文本信息数据集(这里采用了BBC sport数据库举例):

然后就可以开始使用了:
预处理
如果需要进行快速的数据预处理操作,直接使用「文本清理」就行:

当然,如果你需要对文本信息进行更细节的处理操作,例如将所有标点符号替换成空格、或者删除<>中的所有内容,Texthero也提供了非常完备的工具包,以供使用。

△ 光是预处理栏目就有这么多工具
再也不用编写一大堆代码,专门清理文本中的冗余数据了。
表征
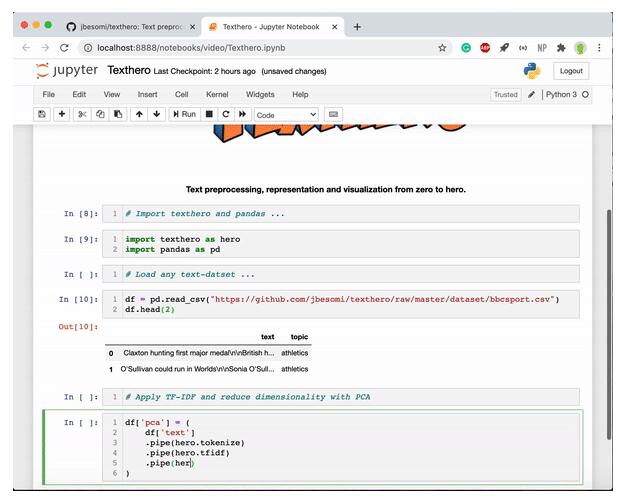
同样,如果需要进行TF-IDF算法特征表示的话,同样只需要几行代码就能实现:

一键出结果:
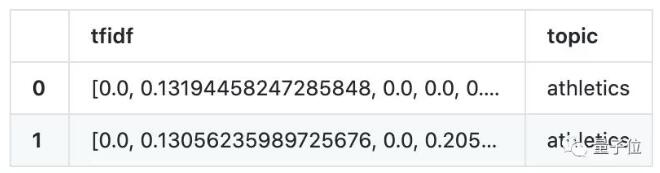
如果需要更多的算法,这里也有meanshift、NMF等算法可以选用,每种算法基本都集成在一行代码中,你想要的这里都有。
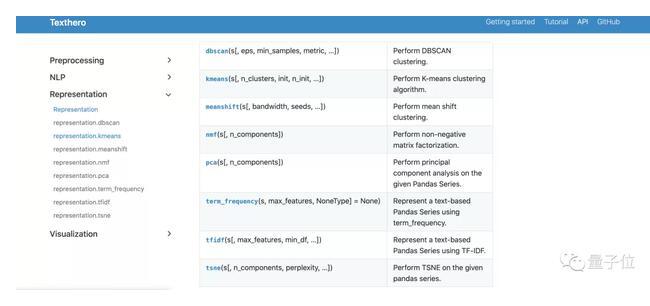
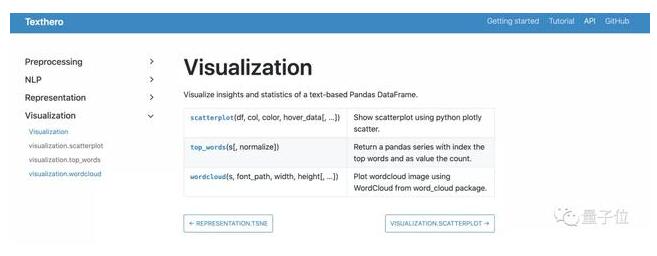
可视化
而在可视化方向上,Texthero同样展现出了强大的能力,这里以PCA降维后的结果进行展示:

可视化界面非常清晰:

同样,可视化也可以自定义颜色、界面展示效果等,只需要一点Python的知识就能快速使用。
这么方便的NLP数据处理工具包,赶紧用起来~
传送门
代码链接:
https://github.com/jbesomi/texthero
项目链接:
https://texthero.org/
















