本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
你是否也在朋友圈看过这样的小广告:
「你要悄悄学Python,然后惊艳所有人。」
现在,GitHub上一位博主告诉你:不用学,用sweetviz就行。
这是一个基于Python编写的数据分析软件,只要掌握3种函数用法,一行Python代码就能实现数据集可视化、分析与比较。
我们以Titanic数据集为例,输入一行代码:

一个1080p的清晰网页界面就出现在了眼前。
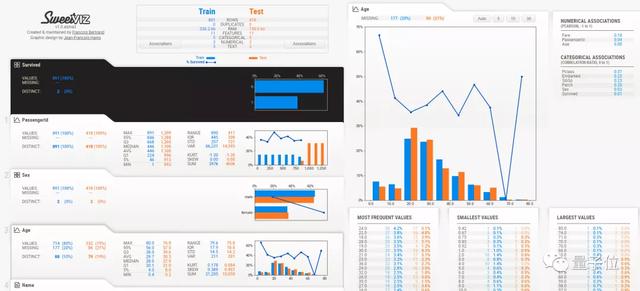
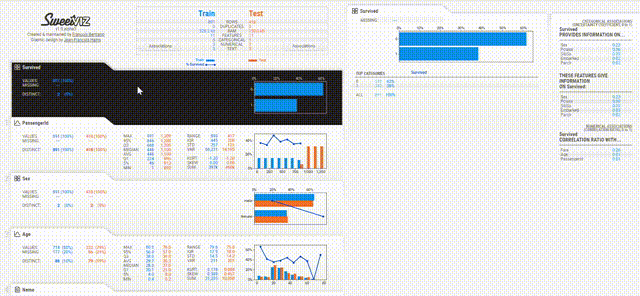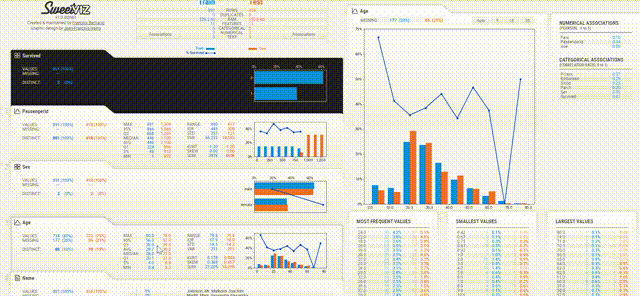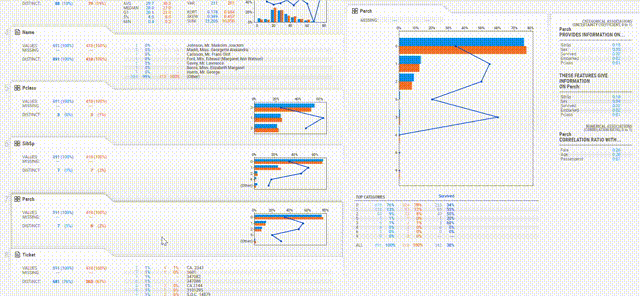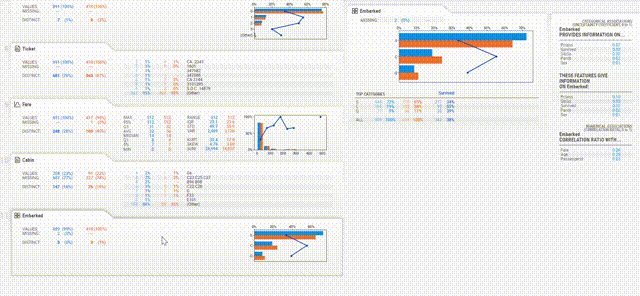
不仅根据性别、年龄等不同栏目纵向分析数据,每个栏目下还有众数、最大值、最小值等横向对比。
所有输入的数值、文本信息都会被自动检测,并进行数据分析、可视化和对比,最后帮你进行数据总结。
在这样的数据分析下,结果一目了然。
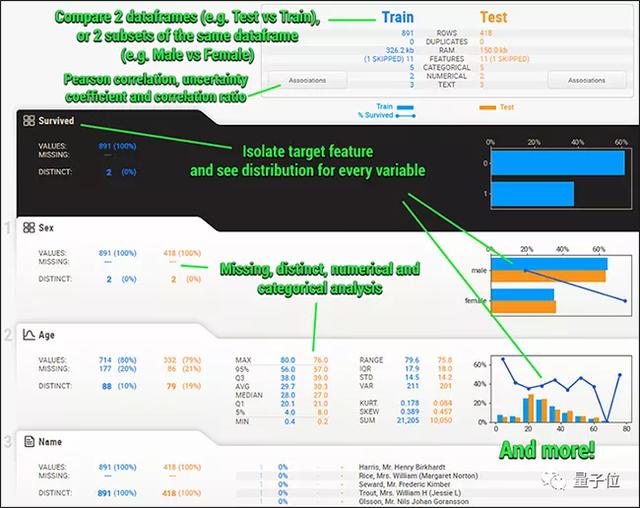
△ Titanic数据集部分功能细节展示
这样的效果,是基于3个主函数实现的。
3种函数用法
analyze()丨数据分析

数据分析函数中,有4个参数source,target_feat,feat_cfg和pairwise_analysis需要被设置。
source:以pandas中的DataFrame数据结构、或是DataFrame中的某一类字符串作为分析对象。
target_feat:需要被标记为目标对象的字符串。
feat_cfg:需要被跳过、或是需要被强制转换为某种数据类型的特征。
pairwise_analysis:相关性和其他类型的数据关联可能需要花费较长时间。如果超过了某个阈值,就需要设置这个参数为on或者off,以判断是否需要分析数据相关性。
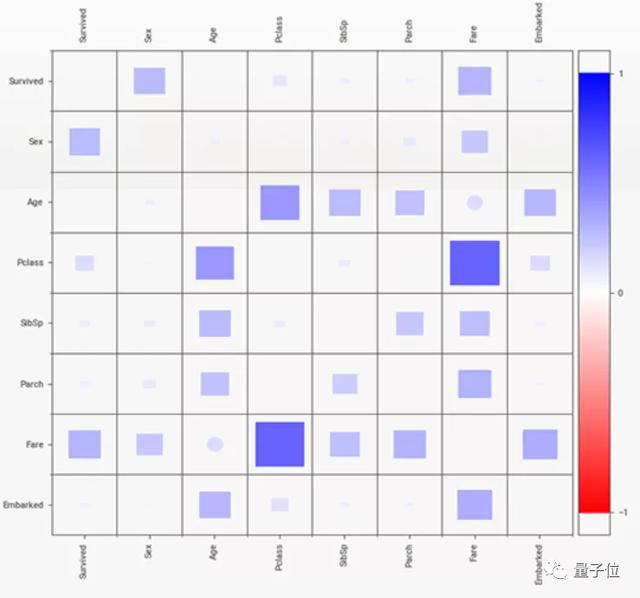
△ 数据相关性分析效果,可能需要花费一定时间
compare()丨两个数据集比较

如果想要对两个数据集进行对比分析,就使用这个比较函数。
例子中的my_dataframe和test_df是两个数据集,分别被命名为训练数据和测试数据。
除了这个被插入的数据集,剩余的参数与analyze中的一致。
compare_intra()丨数据集栏目比较

想要对数据集中某个栏目下的参数进行分析,就采用这个函数进行。
例如,如果需要比较“性别”栏目下的“男性”和“女性”,就可以采用这个函数。
理解这几种函数的变量后,一行代码就能实现Python数据分析。
使用指南
sweetviz支持Python 3.6+和Pandas0.25.3+环境,配置好环境后,使用万能的pip下载安装包:

但有一个条件需要注意:sweetviz需要用到基础「os」模块。所以,如果你在使用类似于Google Colab的自定义环境,可能会无法使用sweetviz,目前开发者也在探索解决方案。
下载好后,使用import快速导入sweetviz,就可以开始使用了~

sweetviz使用的原理是,使用一行代码,生成一个数据报告的对象(其中,my_dataframe是pandas中的DataFrame,一种表格型数据结构):

在这里,analyze函数可以被替换为compare或compare_intra函数,使用方法在上面已经给出,全看你需要什么类型的数据报告了。
最后,用show一键输出。(结果会以SWEETVIZ_REPORT.html网页形式展示)

由于在这个过程中,实际上真正需要编写的只有第二行的生成对象代码,可以说是名副其实的1行代码生成数据分析。
展示界面也非常简洁,只要鼠标停留在感兴趣的栏目上,右侧就会自动显示出数据分析的图表和报告。
感兴趣的小伙伴,快戳下方的传送门用起来吧~
传送门:
https://github.com/fbdesignpro/sweetviz