MySQL:先别跑好吗?
程序员:不跑你养我啊?
MySQL:你听我给你「解释」啊。
程序员:你先管好你自己吧。
现在的互联网应用也好,传统应用也罢,不管开发语言是什么,涉及到关系型数据库,MySQL 基本都是不二之选。
在 Java 的开发框架里, MyBatis 可以自定义 SQL,ORM/JPA 会根据对象映射,自动生成一系列相关的 SQL。至于自动生成的SQL,甚至自定义的SQL 执行效率到底高不高,不用 select *, 增加 where 条件,避免查全量数据等等,我们开发人员可能基本都是根据现有的知识储备,在大脑里过滤一遍,至于到底 SQL 是否高效执行,却从来没有去问过MySQL 一句。
而实际上,SQL语句写完,这项工作完成了还不到一半,其余还需要评估我们SQL写的质量如何,执行效率够不够高。MySQL 像一位智者一样,一直待在那里,只要你问,知无不言。重点在于,你不要急着走,要听他解释一下。
Explain
在 MySQL 中,我们一般常用 desc tableName 来查看一张表的信息,各个列的定义等、通过 Explain SQL 来了解MySQL 是如何执行当前这条SQL的 。
实际上 desc、describe、explain 都可以用来查看MySQL 是如何执行当前这条SQL的,在 MySQL 8.0.19 之后,这三者的作用可以说是等价的,explain 也可以用来查看表信息。后面我们会直接以 explain 为例,来说明具体的作用。
官方文档说的明白, explain 可以和SELECT、INSERT、UPDATE、DELETE 一起工作,显示 MySQL 优化器的语句执行计划,即用来告诉用户 MySQL 会怎样执行这条 SQL,以什么样的顺序,如果是多表的话是怎样 Join的。
输出字段官网文档截图如下:
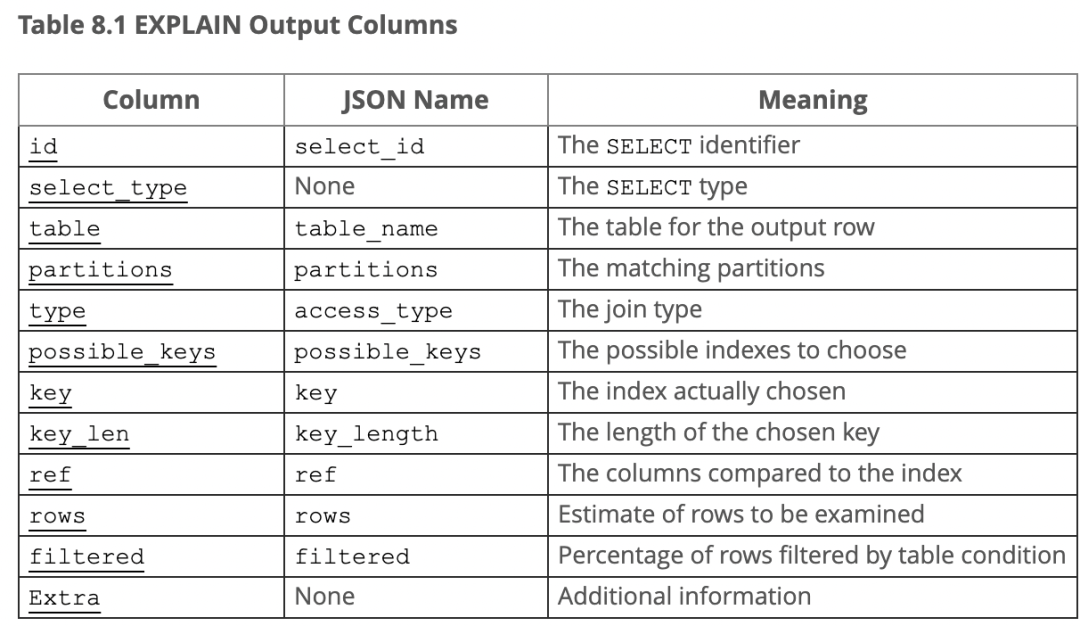
上面返回看似不少,不过我们重点关注 type、key、rows 这三个。
我们常见应用的场景都是读多写少,而且对于 SQL 的执行的效率评估,一般也是说从已经存储的十成、百万甚至千万条数据中查询需要数据的效率。
后面以 SELECT 为例,来看看 explain 能带给我们什么帮忙和建议。
假设有如下表定义及数据:
- CREATE TABLE `t3` (
- `id` int NOT NULL,
- `a` int DEFAULT NULL,
- `b` int DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `a` (`a`)
- ) ENGINE=InnoDB;
- delimiter ;;
- create procedure idata()
- begin
- declare i int;
- set i=1;
- while(i<=100000) do
- insert into t3 values(i,i,i);
- set i=i+1;
- end while;
- end;;
- delimiter ;
- call idata();
执行完上述SQL,我们来试想一下,在当前十万行数据的表中如果执行一条查询SQL,那在少量数据中查找一定比全表查找要快很好。
比如我们最熟悉的通过主键查询
- select a from t3 where id=100;
你会发现,explain 中 type 是 const, key 是 PRIMARY

再比如执行
- select * from t3 where b=100;
这个时候, explain 告诉我们,查询类型是ALL,全表扫描:

如果我们是想要把这个表里全部数据显示也就罢了,目前只查一条数据却执行全表扫描,explain 告诉我们扫描行可能会到9万多行,效率可想而知。
如果我们把SQL 改成这样:
- select * from t3 where a=100;
此时 explain 变成了这样:

你会发现,type 变成了 ref, key 变成了a, rows 是1, 区别只在于 a 列上建立了索引,此时扫描行数变成了一行,差别太明显了。
如果我们要查找一个范围内的数据,通过主键或者包含索引的列进行查询时,

扫描的还是有限行,此时type是range,但如果还是通过 b 做为条件进行过滤,那还是全表扫描:

另外,为什么一般的SQL优化建议里都会说别用 select * ,指定具体用到的列呢?
肯定是用到什么列的数据查什么数据更节省内存,传输,不要等到查出结果再在内存里进行过滤,此外更重要的一点是,每个创建的索引,都有自己的索引树,能够在索引树上完成查询操作,就不需要再回表去查询,效率当然会更高。
比如,我们把查询换成了
- select a,id from t3 where a < 100;
此时,explain 会在Extra里告诉咱们,查询的时候没有回表,用到了index

如果把查询列改成星,这个时候,就需要回表了,

咱们前面说重点关注 type, key, rows,可以再看下 Extra, type 里查询效率从优到差,有
const
表中只有一行匹配,查询一次即可满足。常用来匹配主键或者唯一索引。
eq_ref
唯一索引
ref
非唯一索引
range
通过一个索引去查询,只扫描指定范围内的行。一般是在检索列中包含 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN()
index
类似于全表扫描,区别在于只扫描索引树
all
全表扫描,效率最低的。
在 MySQL 8.0.18 开始,还加入了一个 explain analyze,可以查看具体预计SQL执行耗时,比如我们通过它来查看上面的几个命令,会有如下输出,你会更直观的感觉到加了索引带来的效率提升。


是不是很明显?
所有,你听到MySQL 又在和你说了吗?
『小伙子,你慢些走。有事没事听我给你先解释解释,说道说道啊』
小结一下,通过 explain,我们能在执行前就从 MySQL的优化器拿到对于当前 SQL 的执行计划,了解执行中至少会扫描多少行,是否会使用到索引,大致会用多少时间等,这样该加索引加索引,该改SQL就改SQL,这样做到心中有数,应用的性能会更心中有数。
本文转载自微信公众号「Tomcat那些事儿」,可以通过以下二维码关注。转载本文请联系Tomcat那些事儿公众号。