本文转载自微信公众号「 Java建设者」,作者cxuan 。转载本文请联系Java建设者公众号。
我们在 MySQL 入门篇主要介绍了基本的 SQL 命令、数据类型和函数,在具备以上知识后,你就可以进行 MySQL 的开发工作了,但是如果要成为一个合格的开发人员,你还要具备一些更高级的技能,下面我们就来探讨一下 MySQL 都需要哪些高级的技能。
MySQL 存储引擎
存储引擎概述
数据库最核心的一点就是用来存储数据,数据存储就避免不了和磁盘打交道。那么数据以哪种方式进行存储,如何存储是存储的关键所在。所以存储引擎就相当于是数据存储的发动机,来驱动数据在磁盘层面进行存储。
MySQL 的架构可以按照三层模式来理解
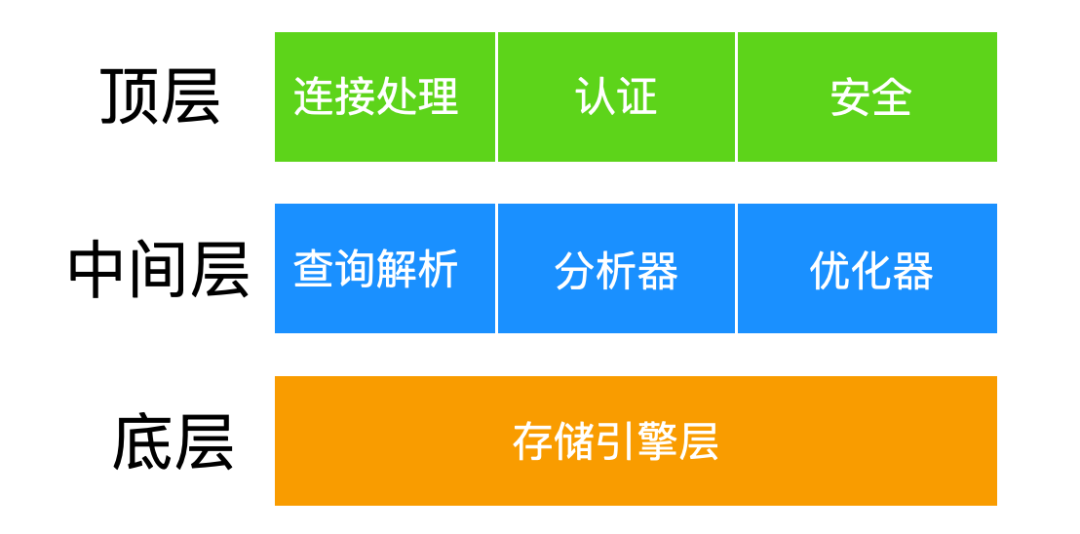
存储引擎也是 MySQL 的组建,它是一种软件,它所能做的和支持的功能主要有
- 并发
- 支持事务
- 完整性约束
- 物理存储
- 支持索引
- 性能帮助
MySQL 默认支持多种存储引擎,来适用不同数据库应用,用户可以根据需要选择合适的存储引擎,下面是 MySQL 支持的存储引擎
- MyISAM
- InnoDB
- BDB
- MEMORY
- MERGE
- EXAMPLE
- NDB Cluster
- ARCHIVE
- CSV
- BLACKHOLE
- FEDERATED
默认情况下,如果创建表不指定存储引擎,会使用默认的存储引擎,如果要修改默认的存储引擎,那么就可以在参数文件中设置 default-table-type,能够查看当前的存储引擎
show variables like 'table_type';
- 1.

奇怪,为什么没有了呢?网上求证一下,在 5.5.3 取消了这个参数
可以通过下面两种方法查询当前数据库支持的存储引擎
show engines \g
- 1.
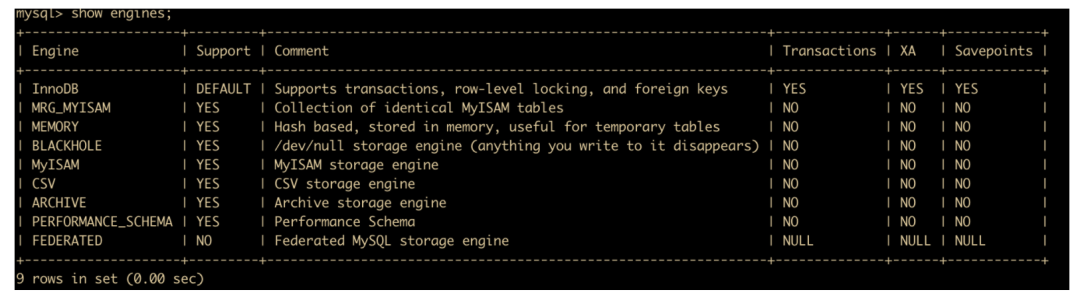
在创建新表的时候,可以通过增加 ENGINE 关键字设置新建表的存储引擎。
create table cxuan002(id int(10),name varchar(20)) engine = MyISAM;
- 1.

上图我们指定了 MyISAM 的存储引擎。
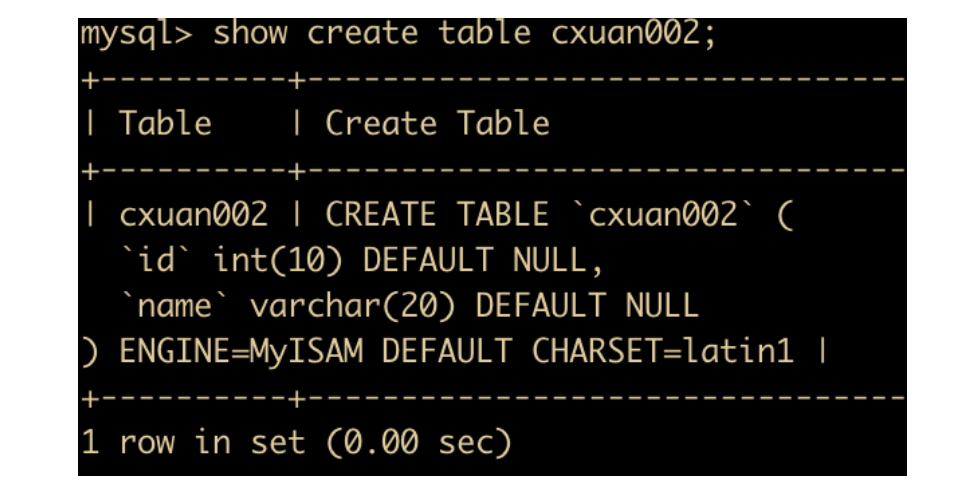
如果你不知道表的存储引擎怎么办?你可以通过 show create table 来查看
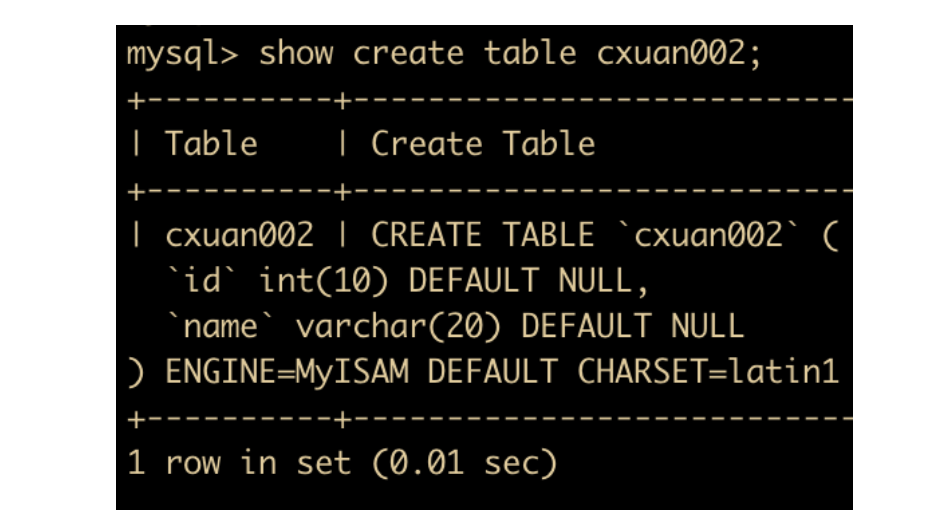
如果不指定存储引擎的话,从MySQL 5.1 版本之后,MySQL 的默认内置存储引擎已经是 InnoDB了。建一张表看一下

如上图所示,我们没有指定默认的存储引擎,下面查看一下表
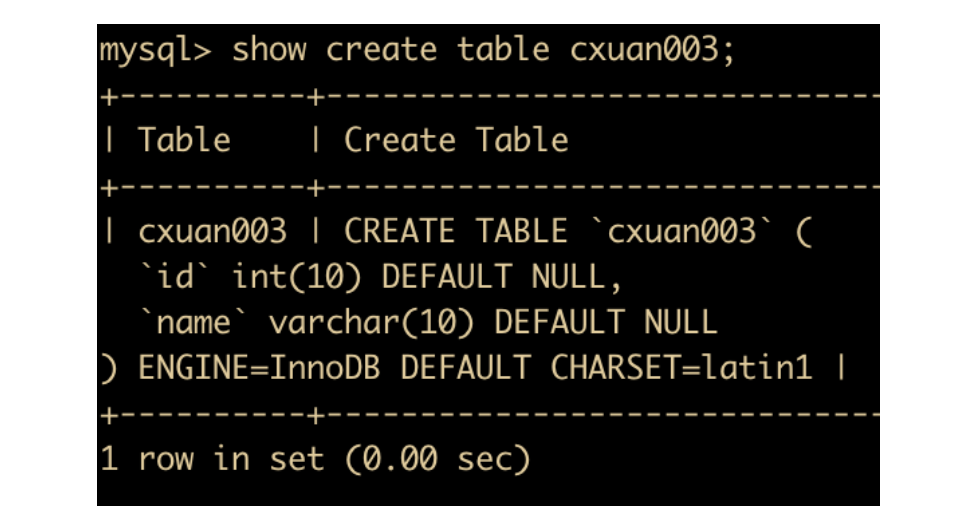
可以看到,默认的存储引擎是 InnoDB。
如果你的存储引擎想要更换,可以使用
alter table cxuan003 engine = myisam;
- 1.
来更换,更换完成后会显示 「0 rows affected」 ,但其实已经操作成功

我们使用 show create table 查看一下表的 sql 就知道
存储引擎特性
下面会介绍几个常用的存储引擎以及它的基本特性,这些存储引擎是 MyISAM、InnoDB、MEMORY 和 MERGE
MyISAM
在 5.1 版本之前,MyISAM 是 MySQL 的默认存储引擎,MyISAM 并发性比较差,使用的场景比较少,主要特点是
- 不支持事务操作,ACID 的特性也就不存在了,这一设计是为了性能和效率考虑的。
- 不支持外键操作,如果强行增加外键,MySQL 不会报错,只不过外键不起作用。
- MyISAM 默认的锁粒度是表级锁,所以并发性能比较差,加锁比较快,锁冲突比较少,不太容易发生死锁的情况。
- MyISAM 会在磁盘上存储三个文件,文件名和表名相同,扩展名分别是 .frm(存储表定义)、.MYD(MYData,存储数据)、MYI(MyIndex,存储索引)。这里需要特别注意的是 MyISAM 只缓存索引文件,并不缓存数据文件。
- MyISAM 支持的索引类型有 全局索引(Full-Text)、B-Tree 索引、R-Tree 索引
Full-Text 索引:它的出现是为了解决针对文本的模糊查询效率较低的问题。
B-Tree 索引:所有的索引节点都按照平衡树的数据结构来存储,所有的索引数据节点都在叶节点
R-Tree索引:它的存储方式和 B-Tree 索引有一些区别,主要设计用于存储空间和多维数据的字段做索引,目前的 MySQL 版本仅支持 geometry 类型的字段作索引,相对于 BTREE,RTREE 的优势在于范围查找。
数据库所在主机如果宕机,MyISAM 的数据文件容易损坏,而且难以恢复。
增删改查性能方面:SELECT 性能较高,适用于查询较多的情况
InnoDB
自从 MySQL 5.1 之后,默认的存储引擎变成了 InnoDB 存储引擎,相对于 MyISAM,InnoDB 存储引擎有了较大的改变,它的主要特点是
- 支持事务操作,具有事务 ACID 隔离特性,默认的隔离级别是可重复读(repetable-read)、通过MVCC(并发版本控制)来实现的。能够解决脏读和不可重复读的问题。
- InnoDB 支持外键操作。
- InnoDB 默认的锁粒度行级锁,并发性能比较好,会发生死锁的情况。
- 和 MyISAM 一样的是,InnoDB 存储引擎也有 .frm文件存储表结构 定义,但是不同的是,InnoDB 的表数据与索引数据是存储在一起的,都位于 B+ 数的叶子节点上,而 MyISAM 的表数据和索引数据是分开的。
- InnoDB 有安全的日志文件,这个日志文件用于恢复因数据库崩溃或其他情况导致的数据丢失问题,保证数据的一致性。
- InnoDB 和 MyISAM 支持的索引类型相同,但具体实现因为文件结构的不同有很大差异。
- 增删改查性能方面,果执行大量的增删改操作,推荐使用 InnoDB 存储引擎,它在删除操作时是对行删除,不会重建表。
MEMOR
YMEMORY 存储引擎使用存在内存中的内容来创建表。每个 MEMORY 表实际只对应一个磁盘文件,格式是 .frm。MEMORY 类型的表访问速度很快,因为其数据是存放在内存中。默认使用 HASH 索引。
MERGE
MERGE 存储引擎是一组 MyISAM 表的组合,MERGE 表本身没有数据,对 MERGE 类型的表进行查询、更新、删除的操作,实际上是对内部的 MyISAM 表进行的。MERGE 表在磁盘上保留两个文件,一个是 .frm 文件存储表定义、一个是 .MRG 文件存储 MERGE 表的组成等。
选择合适的存储引擎
在实际开发过程中,我们往往会根据应用特点选择合适的存储引擎。
- MyISAM:如果应用程序通常以检索为主,只有少量的插入、更新和删除操作,并且对事物的完整性、并发程度不是很高的话,通常建议选择 MyISAM 存储引擎。
- InnoDB:如果使用到外键、需要并发程度较高,数据一致性要求较高,那么通常选择 InnoDB 引擎,一般互联网大厂对并发和数据完整性要求较高,所以一般都使用 InnoDB 存储引擎。
- MEMORY:MEMORY 存储引擎将所有数据保存在内存中,在需要快速定位下能够提供及其迅速的访问。MEMORY 通常用于更新不太频繁的小表,用于快速访问取得结果。
- MERGE:MERGE 的内部是使用 MyISAM 表,MERGE 表的优点在于可以突破对单个 MyISAM 表大小的限制,并且通过将不同的表分布在多个磁盘上, 可以有效地改善 MERGE 表的访问效率。
选择合适的数据类型
我们会经常遇见的一个问题就是,在建表时如何选择合适的数据类型,通常选择合适的数据类型能够提高性能、减少不必要的麻烦,下面我们就来一起探讨一下,如何选择合适的数据类型。
CHAR 和 VARCHAR 的选择
char 和 varchar 是我们经常要用到的两个存储字符串的数据类型,char 一般存储定长的字符串,它属于固定长度的字符类型,比如下面
| 值 | char(5) | 存储字节 |
|---|---|---|
| '' | ' ' | 5个字节 |
| 'cx' | 'cx ' | 5个字节 |
| 'cxuan' | 'cxuan' | 5个字节 |
| 'cxuan007' | 'cxuan' | 5个字节 |
可以看到,不管你的值写的是什么,一旦指定了 char 字符的长度,如果你的字符串长度不够指定字符的长度的话,那么就用空格来填补,如果超过字符串长度的话,只存储指定字符长度的字符。
❝这里注意一点:如果 MySQL 使用了非 严格模式的话,上面表格最后一行是可以存储的。如果 MySQL 使用了 严格模式 的话,那么表格上面最后一行存储会报错。❞
如果使用了 varchar 字符类型,我们来看一下例子
| 值 | varchar(5) | 存储字节 |
|---|---|---|
| '' | '' | 1个字节 |
| 'cx' | 'cx ' | 3个字节 |
| 'cxuan' | 'cxuan' | 6个字节 |
| 'cxuan007' | 'cxuan' | 6个字节 |
可以看到,如果使用 varchar 的话,那么存储的字节将根据实际的值进行存储。你可能会疑惑为什么 varchar 的长度是 5 ,但是却需要存储 3 个字节或者 6 个字节,这是因为使用 varchar 数据类型进行存储时,默认会在最后增加一个字符串长度,占用1个字节(如果列声明的长度超过255,则使用两个字节)。varchar 不会填充空余的字符串。
一般使用 char 来存储定长的字符串,比如「身份证号、手机号、邮箱等」;使用 varchar 来存储不定长的字符串。由于 char 长度是固定的,所以它的处理速度要比 VARCHAR 快很多,但是缺点是浪费存储空间,但是随着 MySQL 版本的不断演进,varchar 数据类型的性能也在不断改进和提高,所以在许多应用中,VARCHAR 类型更多的被使用。
在 MySQL 中,不同的存储引擎对 CHAR 和 VARCHAR 的使用原则也有不同
- MyISAM:建议使用固定长度的数据列替代可变长度的数据列,也就是 CHAR
- MEMORY:使用固定长度进行处理、CHAR 和 VARCHAR 都会被当作 CHAR 处理
- InnoDB:建议使用 VARCHAR 类型
TEXT 与 BLOB
一般在保存较少的文本的时候,我们会选择 CHAR 和 VARCHAR,在保存大数据量的文本时,我们往往选择 TEXT 和 BLOB;TEXT 和 BLOB 的主要差别是 BLOB 能够保存二进制数据;而 TEXT 只能保存字符数据,TEXT 往下细分有
- TEXT
- MEDIUMTEXT
- LONGTEXT
BLOB 往下细分有
- BLOB
- MEDIUMBLOB
- LONGBLOB
三种,它们最主要的区别就是存储文本长度不同和存储字节不同,用户应该根据实际情况选择满足需求的最小存储类型,下面主要对 BLOB 和 TEXT 存在一些问题进行介绍
TEXT 和 BLOB 在删除数据后会存在一些性能上的问题,为了提高性能,建议使用 OPTIMIZE TABLE 功能对表进行碎片整理。
也可以使用合成索引来提高文本字段(BLOB 和 TEXT)的查询性能。合成索引就是根据大文本(BLOB 和 TEXT)字段的内容建立一个散列值,把这个值存在对应列中,这样就能够根据散列值查找到对应的数据行。一般使用散列算法比如 md5() 和 SHA1() ,如果散列算法生成的字符串带有尾部空格,就不要把它们存在 CHAR 和 VARCHAR 中,下面我们就来看一下这种使用方式
首先创建一张表,表中记录 blob 字段和 hash 值

向 cxuan005 中插入数据,其中 hash 值作为 info 的散列值。

然后再插入两条数据

插入一条 info 为 cxuan005 的数据

如果想要查询 info 为 cxuan005 的数据,可以通过查询 hash 列来进行查询

这是合成索引的例子,如果要对 BLOB 进行模糊查询的话,就要使用前缀索引。
其他优化 BLOB 和 TEXT 的方式:
- 非必要的时候不要检索 BLOB 和 TEXT 索引
- 把 BLOB 或 TEXT 列分离到单独的表中。
浮点数和定点数的选择
浮点数指的就是含有小数的值,浮点数插入到指定列中超过指定精度后,浮点数会四舍五入,MySQL 中的浮点数指的就是 float 和 double,定点数指的是 decimal,定点数能够更加精确的保存和显示数据。下面通过一个示例讲解一下浮点数精确性问题
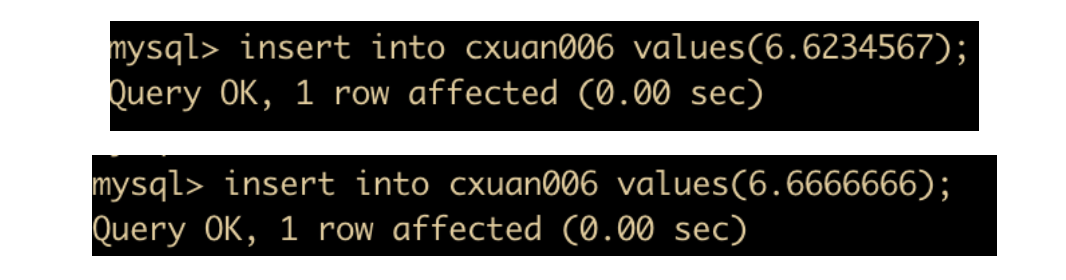
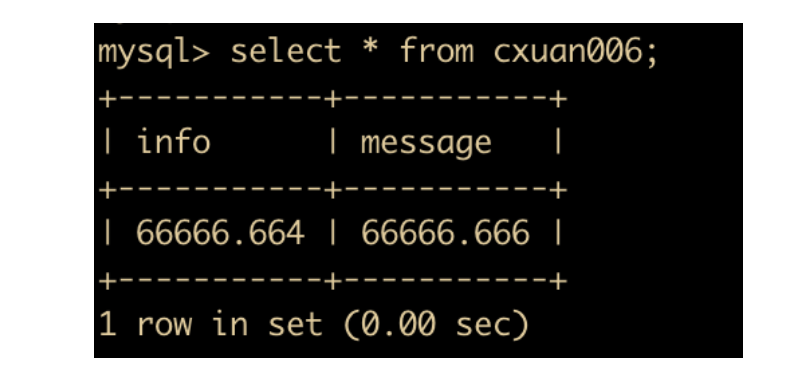
首先创建一个表 cxuan006 ,只为了测试浮点数问题,所以这里我们选择的数据类型是 float

然后分别插入两条数据
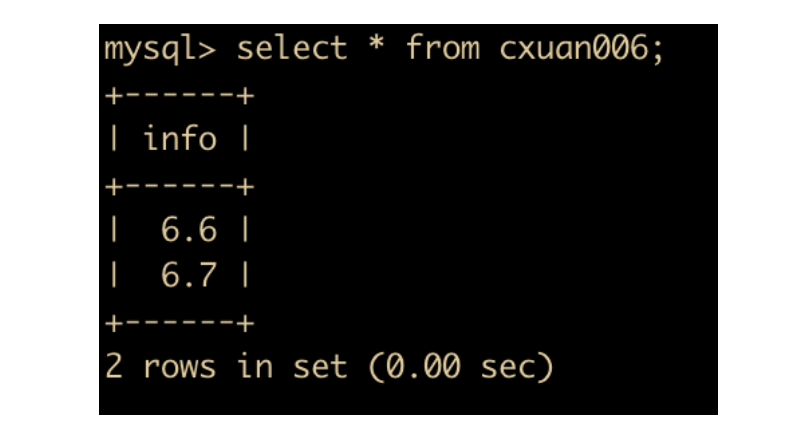
然后执行查询,可以看到查询出来的两条数据执行的舍入不同
为了清晰的看清楚浮点数与定点数的精度问题,再来看一个例子
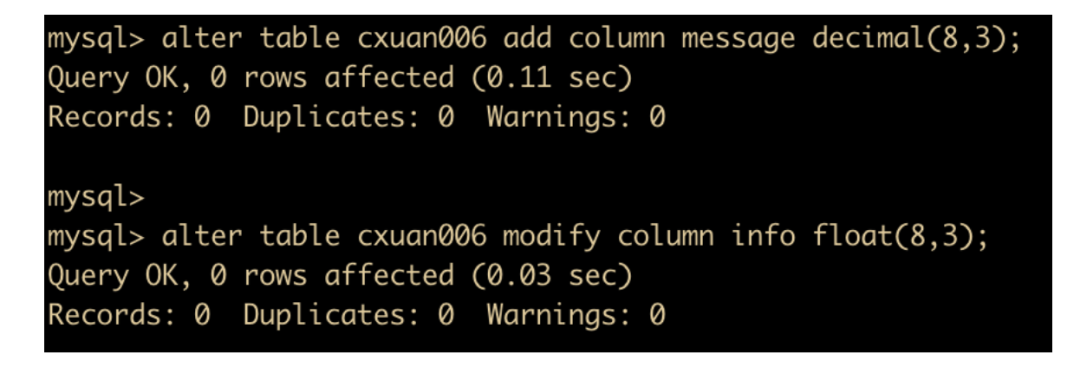
先修改 cxuan006 的两个字段为相同的长度和小数位数
然后插入两条数据

执行查询操作,可以发现,浮点数相较于定点数来说,会产生误差
日期类型选择
在 MySQL 中,用来表示日期类型的有 「DATE、TIME、DATETIME、TIMESTAMP」,在
138 张图带你 MySQL 入门
这篇文中介绍过了日期类型的区别,我们这里就不再阐述了。下面主要介绍一下选择
- TIMESTAMP 和时区相关,更能反映当前时间,如果记录的日期需要让不同时区的人使用,最好使用 TIMESTAMP。
- DATE 用于表示年月日,如果实际应用值需要保存年月日的话就可以使用 DATE。
- TIME 用于表示时分秒,如果实际应用值需要保存时分秒的话就可以使用 TIME。
- YEAR 用于表示年份,YEAR 有 2 位(最好使用4位)和 4 位格式的年。默认是4位。如果实际应用只保存年份,那么用 1 bytes 保存 YEAR 类型完全可以。不但能够节约存储空间,还能提高表的操作效率。
MySQL 字符集
下面来认识一下 MySQL 字符集,简单来说字符集就是一套文字符号和编码、比较规则的集合。1960 年美国标准化组织 ANSI 发布了第一个计算机字符集,就是著名的 ASCII(American Standard Code for Information Interchange) 。自从 ASCII 编码后,每个国家、国际组织都研究了一套自己的字符集,比如 ISO-8859-1、GBK 等。
但是每个国家都使用自己的字符集为移植性带来了很大的困难。所以,为了统一字符编码,国际标准化组织(ISO) 指定了统一的字符标准 - Unicode 编码,它容纳了几乎所有的字符编码。下面是一些常见的字符编码
| 字符集 | 是否定长 | 编码方式 |
|---|---|---|
| ASCII | 是 | 单字节 7 位编码 |
| ISO-8859-1 | 是 | 单字节 8 位编码 |
| GBK | 是 | 双字节编码 |
| UTF-8 | 否 | 1 - 4 字节编码 |
| UTF-16 | 否 | 2 字节或 4 字节编码 |
| UTF-32 | 是 | 4 字节编码 |
对数据库来说,字符集是很重要的,因为数据库存储的数据大多数都是各种文字,字符集对数据库的存储、性能、系统的移植来说都非常重要。
MySQL 支持多种字符集,可以使用 show character set; 来查看所有可用的字符集
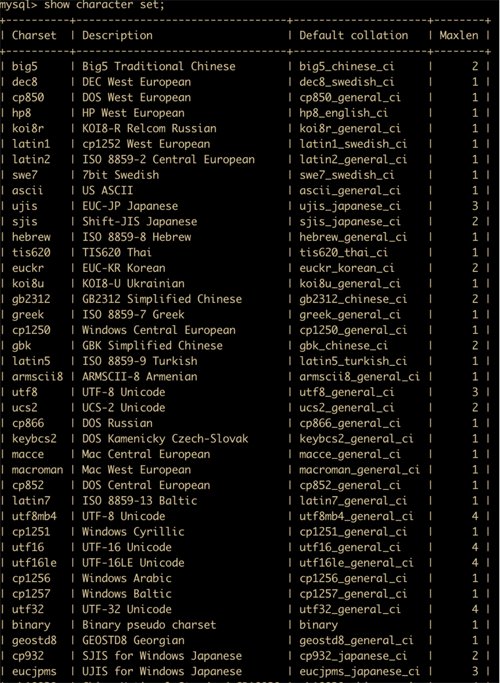
或者使用
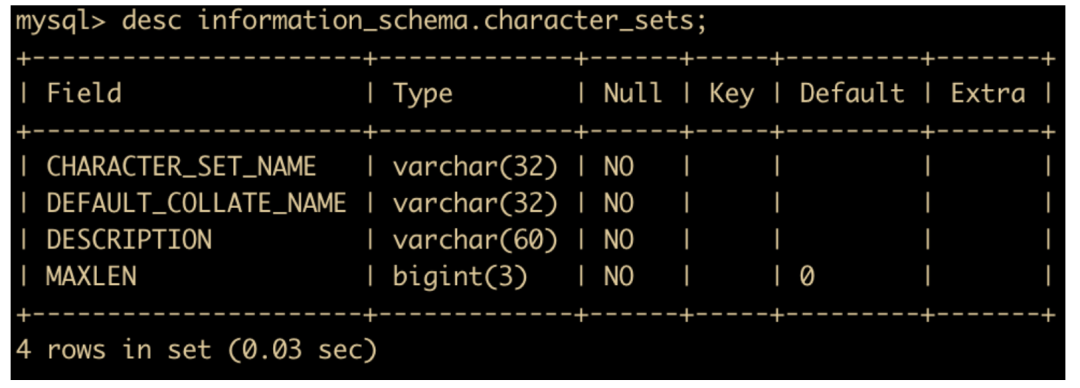
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;
来查看。
使用 information_schema.character_set 来查看字符集和校对规则。