前言
Python由于其易用性而成为最流行的语言,它提供了许多库,使程序员能够开发更强大的软件,以并行运行模型和数据转换。
有这么一个库,它提供了并行计算、加速了算法,甚至允许您将NumPy和pandas与XGBoost库集成在一起。让我们认识一下吧。
什么是Dask
Dask是一个开源项目,它允许开发者与scikit-learn、pandas和NumPy合作开发他们的软件。它是一个非常通用的工具,可以处理各种工作负载。
这个工具包括两个重要的部分;动态任务调度和大数据收集。前面的部分与Luigi、芹菜和气流非常相似,但它是专门为交互式计算工作负载优化的。
后一部分包括数据帧、并行数组和扩展到流行接口(如pandas和NumPy)的列表。
事实上,Dask的创建者Matthew Rocklin先生确认Dask最初是为了并行化Pandas和NumPy而创建的,尽管它现在提供了比一般的并行系统更多的好处。
Dask的数据帧非常适合用于缩放pandas工作流和启用时间序列的应用程序。此外,Dask阵列还为生物医学应用和机器学习算法提供多维数据分析。
可扩展性
Dask如此受欢迎的原因是它使Python中的分析具有可扩展性。
这个工具的神奇之处在于它只需要最少的代码更改。该工具在具有1000多个核的弹性集群上运行!此外,您可以在处理数据的同时并行运行此代码,这将简化为更少的执行时间和等待时间!
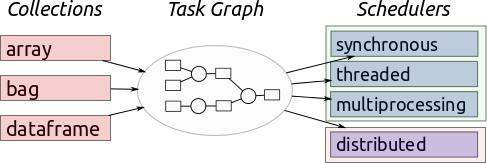
该工具完全能够将复杂的计算计算调度、构建甚至优化为图形。这就是为什么运行在10tb上的公司可以选择这个工具作为首选的原因。
Dask还允许您为数据数组构建管道,稍后可以将其传输到相关的计算资源。总之,这个工具不仅仅是一个并行版本的pandas。
如何工作
现在我们已经理解了Dask的基本概念,让我们看一个示例代码来进一步理解:
- import dask.array as da
- f = h5py.File('myfile.hdf5')
- x = da.from_array(f['/big-data'],
- chunks=(1000, 1000))
对于那些熟悉数据帧和数组的人来说,这几乎就是你放置数据的地方。
在本例中,您已经将数据放入了Dask版本中,您可以利用Dask提供的分发特性来运行与使用pandas类似的功能。
为何如此流行
作为一个由PyData生成的现代框架,Dask由于其并行处理能力而备受关注。
在处理大量数据——尤其是比RAM大的数据块——以便获得有用的见解时,这是非常棒的。公司受益于Dask提供的强大分析,因为它在单机上进行高效的并行计算。
这就是为什么Gitential、Oxlabs、DataSwot和Red Hat等跨国公司已经在他们的日常工作系统中使用Dask的主要原因。总的来说,Dask之所以超级受欢迎是因为:
- 集成:Dask提供了与许多流行工具的集成,其中包括PySpark、pandas、OpenRefine和NumPy。
- 动态任务调度:它提供了动态任务调度并支持许多工作负载。
- 熟悉的API:这个工具不仅允许开发人员通过最小的代码重写来扩展工作流,而且还可以很好地与这些工具甚至它们的API集成。
- 向外扩展集群:Dask计算出如何分解大型计算并有效地将它们路由到分布式硬件上。
- 安全性:Dask支持加密,通过使用TLS/SSL认证进行身份验证。
优缺点
让我们权衡一下这方面的利弊。
使用Dask的优点:
- 它使用pandas提供并行计算。
- Dask提供了与pandas API类似的语法,所以它不那么难熟悉。
使用Dask的缺点:
- 在Dask的情况下,与Spark不同,如果您希望在创建集群之前尝试该工具,您将无法找到独立模式。
- 它在Scala和R相比可扩展性不强。