













随着技术的发展,需要新方法的新问题也随之发展。随着智能设备(如智能开关、恒温器和第三代语音助手)的出现,数据量激增并降低了集中计算和分析的效率。边缘计算通过帮助这些智能设备处理数据来满足它们在边缘节点上的需求,从而使这些智能设备更加智能。
边缘计算仅传输集中计算所需的数据,从而解决了延时及带宽成本等诸多问题。边缘技术不仅提高了边缘设备的效率,而且还提高了集中式分析系统的效率。鉴于边缘计算的前景,它有望成为2020年及以后最重要的技术趋势之一。
例如,Google的Nest使用机器学习算法,根据每天的温度调整情况,了解居民在工作日或周末是在家还是外出。借助此信息,Nest可以在整个星期和周末自行调节温度。Nest的边缘处理与集中处理相结合,突显了企业数据管理面临的一个有趣挑战。
传统上,企业采用了一种分析数据并使用集中式方法从中获取情报的体系结构。例如,数据仓库是商业智能的主力军,是众所周知的中央存储库,可以将原始数据转化为洞察力。该过程称为ETL,它从操作系统中提取数据,将其转换为适当的格式,然后将其加载到数据仓库中。
多年来,这种架构已被证明是有效的。但是在边缘设备时代,传统的物理数据仓库失去了作为真理的中心来源的光泽。这是因为随着当今世界转向大量非结构化数据,它们只能存储结构化数据。而且,数据量呈指数增长。它已经变得如此庞大,以至于在许多用例中,将所有数据存储在单个数据仓库中在经济上不再可行。为了克服这些挑战,企业将其中央存储库过渡到了更便宜的替代方案(如Hadoop),后者还可以存储非结构化数据。
尽管有了这些发展,但从性能和成本的角度来看,仍然不希望将发布于世界各地的多个设备生成的所有信息收集到数千英里之外的一个中央存储库中。中央系统也无法有效智能地分析信息,然后再将这些信息一直建议给设备,以实现优秀性能。
那么,缺少什么呢?
在我们看来,这是一种在设备本身附近执行计算功能的技术。边缘计算架构的出现使设备能够将其生成的数据发送到边缘节点或距离设备更近的系统,以进行分析或计算。这样,设备从边缘节点获得所需的情报的速度比连接到中央系统时要快得多。
在此设置中,边缘节点连接到中央系统,因此它们仅传输中央系统在所有各种设备上进行分析所需的信息。结果,存在计算的双重性,其中某些计算在边缘节点上进行,达到了本地操作所需的程度,同时,数据被传输到中央分析系统以对所有对象进行整体分析企业系统。
如今,幸运的是,具有在边缘仅智能过滤所需数据并仅将减少的数据传输到集中式系统的功能。通过减少多达80%的移动数据,数据虚拟化可以实时执行这种选择性的数据处理和交付,而不必在其中复制数据。
当数据来自各种设备时,位于更靠近这些设备的边缘节点处的数据虚拟化实例将这些数据集成在一起,然后仅提取结果。然后,将它们传送到位于中心位置的另一个数据虚拟化实例,该实例更靠近数据使用者,后者使用报告工具来分析结果。因此,多位置架构中的数据虚拟化实例网络(其中一些位于边缘节点)连接到中央数据虚拟化实例,从而完善了边缘计算框架。
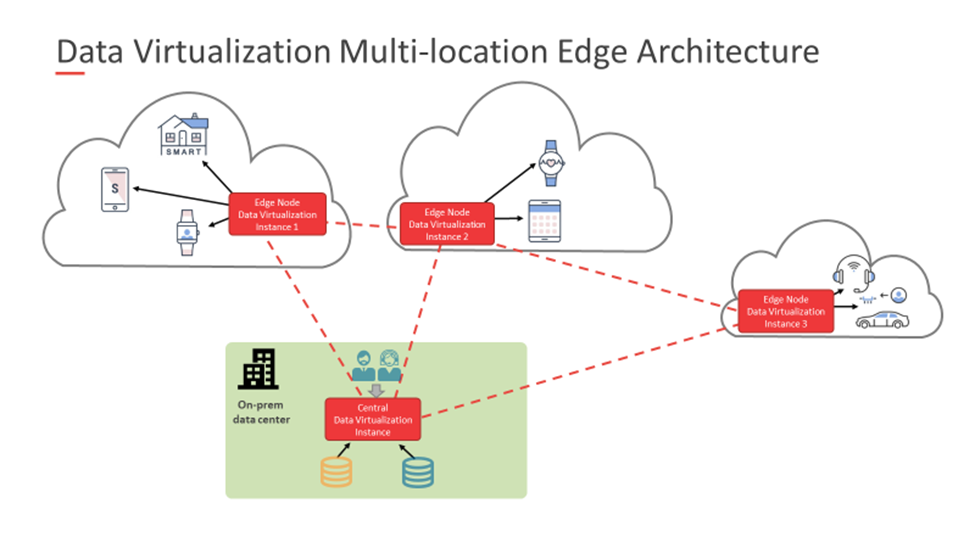
数据虚拟化多位置边缘架构(Source: Denodo)
为什么在边缘更智能?
边缘计算的较大好处是节省时间。在过去的几年中,该技术在存储和计算两个方面发展得比其他方面快得多。 今天的手机比30年前的台式电脑拥有更多的内存和计算能力。但是,边缘技术的一个方面发展得还不如传输数据的带宽快,因为数据从一个位置移动到另一位置仍需要几分钟和几小时。随着设备越来越远地迁移到云和跨大洲,必须传输尽可能少的数据以提高整体效率。
通过将计算委托给边缘,这些设备将实时学习和调整,而不会因与中央系统之间的信息传输而减慢速度。数据虚拟化将带宽需求以及存储成本降低了多达80%。




















