之所以写这篇文章是因为之前面试时候被面试官问到(倒)了,面试官说:“你说你对Kafka比较熟?看过源码? 那说说kafka日志段如何读写的吧?”
我心里默默的说了句 “擦…我说看过一点点源码,不是亿点点。早知道不提这句了!”,那怎么办呢,只能回家等通知了啊。
但是为了以后找回场子,咱也不能坐以待毙,日拱一卒从一点点到亿点点。今天我们就来看看源码层面来Kafka日志段的是如何读写的。
Kafka的存储结构
总所周知,Kafka的Topic可以有多个分区,分区其实就是最小的读取和存储结构,即Consumer看似订阅的是Topic,实则是从Topic下的某个分区获得消息,Producer也是发送消息也是如此。
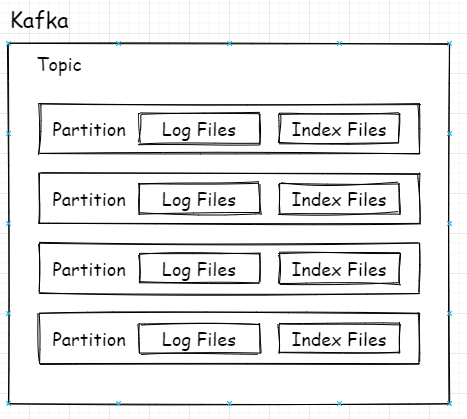
topic-partition关系
上图是总体逻辑上的关系,映射到实际代码中在磁盘上的关系则是如下图所示:
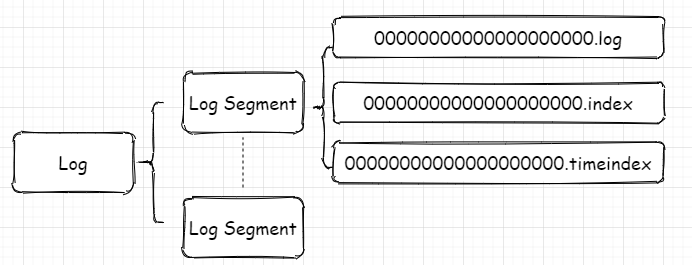
每个分区对应一个Log对象,在磁盘中就是一个子目录,子目录下面会有多组日志段即多Log Segment,每组日志段包含:消息日志文件(以log结尾)、位移索引文件(以index结尾)、时间戳索引文件(以timeindex结尾)。其实还有其它后缀的文件,例如.txnindex、.deleted等等。篇幅有限,暂不提起。
以下为日志的定义
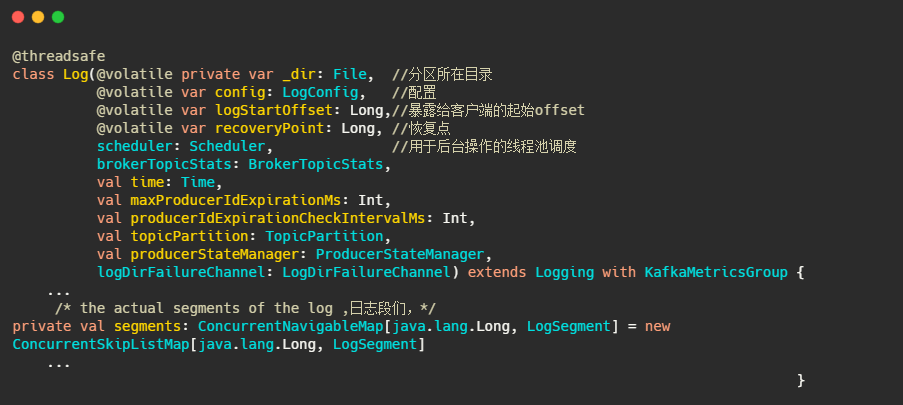
以下为日志段的定义
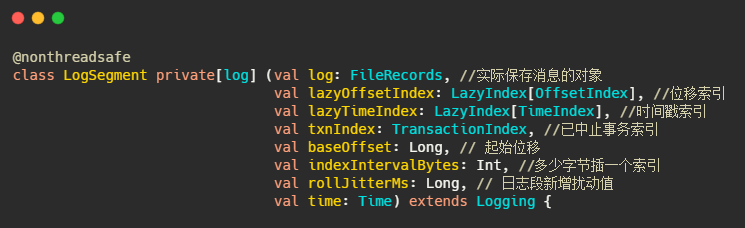
indexIntervalBytes可以理解为插了多少消息之后再建一个索引,由此可以看出Kafka的索引其实是稀疏索引,这样可以避免索引文件占用过多的内存,从而可以在内存中保存更多的索引。对应的就是Broker 端参数log.index.interval.bytes 值,默认4KB。
实际的通过索引查找消息过程是先通过offset找到索引所在的文件,然后通过二分法找到离目标最近的索引,再顺序遍历消息文件找到目标文件。这波操作时间复杂度为O(log2n)+O(m),n是索引文件里索引的个数,m为稀疏程度。
这就是空间和时间的互换,又经过数据结构与算法的平衡,妙啊!
再说下rollJitterMs,这其实是个扰动值,对应的参数是log.roll.jitter.ms,这其实就要说到日志段的切分了,log.segment.bytes,这个参数控制着日志段文件的大小,默认是1G,即当文件存储超过1G之后就新起一个文件写入。这是以大小为维度的,还有一个参数是log.segment.ms,以时间为维度切分。
那配置了这个参数之后如果有很多很多分区,然后因为这个参数是全局的,因此同一时刻需要做很多文件的切分,这磁盘IO就顶不住了啊,因此需要设置个rollJitterMs,来岔开它们。
怎么样有没有联想到redis缓存的过期时间?过期时间加个随机数,防止同一时刻大量缓存过期导致缓存击穿数据库。看看知识都是通的啊!
日志段的写入
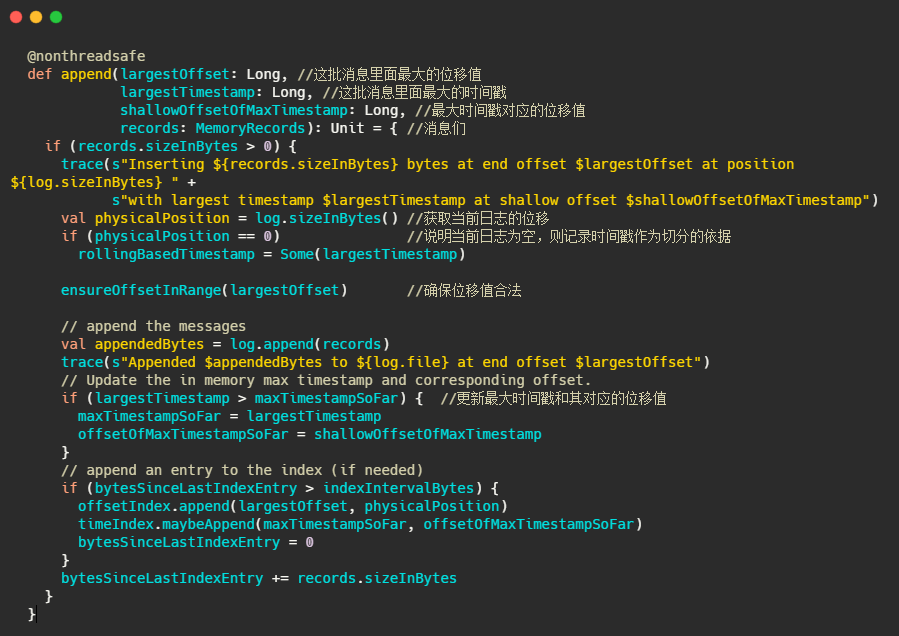
1、判断下当前日志段是否为空,空的话记录下时间,来作为之后日志段的切分依据
2、确保位移值合法,最终调用的是AbstractIndex.toRelative(..)方法,即使判断offset是否小于0,是否大于int最大值。
3、append消息,实际上就是通过FileChannel将消息写入,当然只是写入内存中及页缓存,是否刷盘看配置。
4、更新日志段最大时间戳和最大时间戳对应的位移值。这个时间戳其实用来作为定期删除日志的依据
5、更新索引项,如果需要的话(bytesSinceLastIndexEntry > indexIntervalBytes)
最后再来个流程图
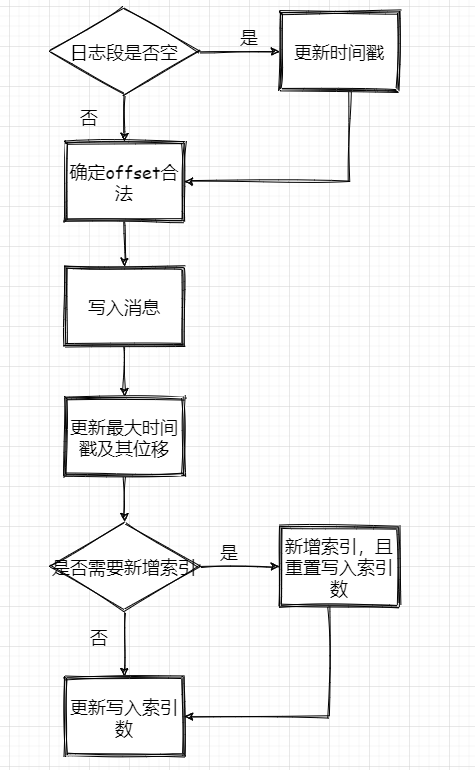
消息写入流程
日志段的读取
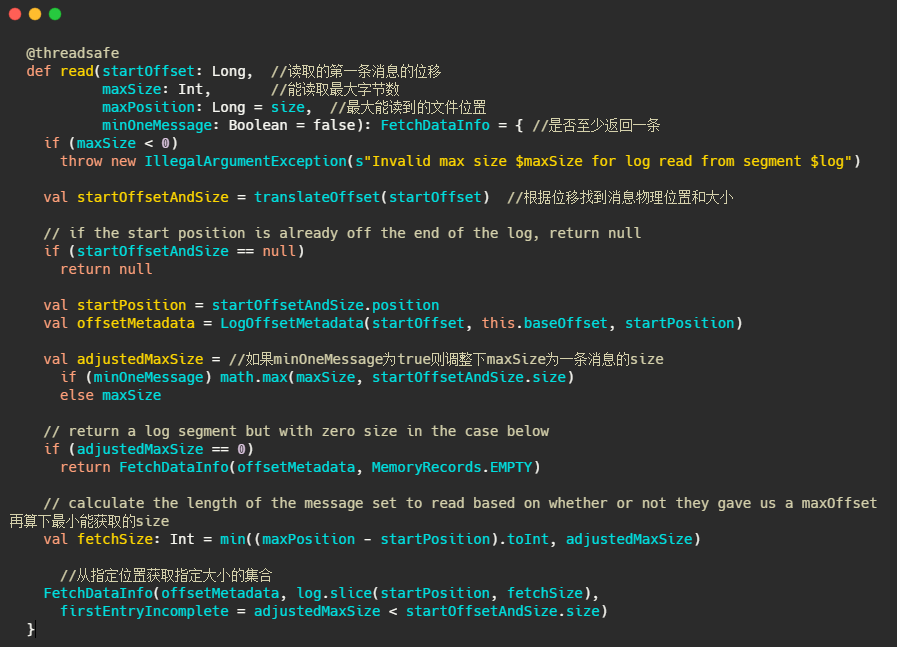
1、根据第一条消息的offset,通过OffsetIndex找到对应的消息所在的物理位置和大小。
2、获取LogOffsetMetadata,元数据包含消息的offset、消息所在segment的起始offset和物理位置
3、判断minOneMessage是否为true,若是则调整为必定返回一条消息大小,其实就是在单条消息大于maxSize的情况下得以返回,防止消费者饿死
4、再计算最大的fetchSize,即(最大物理位移-此消息起始物理位移)和adjustedMaxSize的最小值(这波我不是很懂,因为以上一波操作adjustedMaxSize已经最小为一条消息的大小了)
5、调用 FileRecords 的 slice 方法从指定位置读取指定大小的消息集合,并且构造FetchDataInfo返回
再来个流程图:
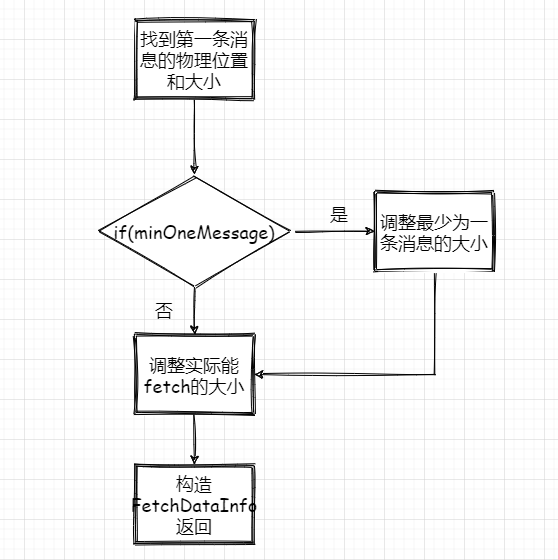
消息读取流程
小结
从哪里跌倒就从哪里爬起来对吧,这波操作下来咱也不怕下次遇到面试官问了。
区区源码不过尔尔,哈哈哈哈(首先得要有气势)
实际上这只是Kafka源码的冰山一角,长路漫漫。虽说Kafka Broker都是由Scala写的,不过语言不是问题,这不看下来也没什么难点,注释也很丰富。遇到不知道的语法小查一下搞定。
所以强烈建议大家入手源码,从源码上理解。今天说的 append 和 read 是很核心的功能,但一看也并不复杂,所以不要被源码这两个字吓到了。
看源码可以让我们深入的理解内部的设计原理,精进我们的代码功力(经常看着看着,我擦还能这么写)。当然还有系统架构能力。
然后对我而言最重要的是可以装逼了(哈哈哈)。
情景剧
老白正目不转睛盯着监控大屏,“为什么?为什么Kafka Broker物理磁盘 I/O 负载突然这么高?”。寥寥无几的秀发矗立在老白的头上,显得如此的无助。
“是不是设置了 log.segment.ms参数 ?试试 log.roll.jitter.ms吧”,老白抬头间我已走出了办公室,留下了一个伟岸的背影和一颗锃亮的光头!
“我变秃了,也变强了”