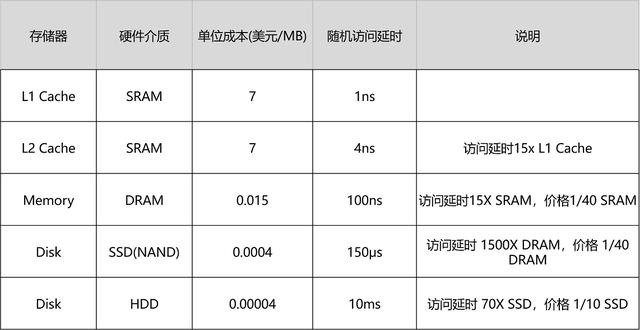
在 SRAM 里面,一个比特的数据,需要 6~8 个晶体管。所以 SRAM 的存储密度不高。同样的物理空间下,能够存储的数据有限。不过,因为 SRAM 的电路简单,所以访问速度非常快。
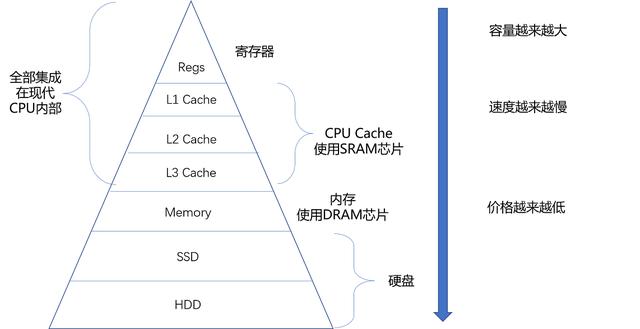
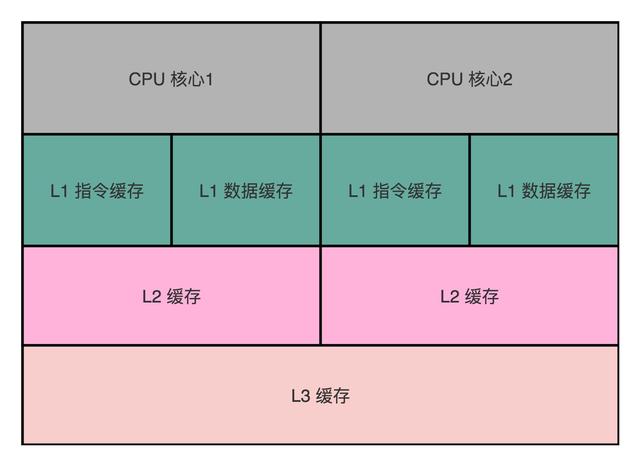
在 CPU 里,通常会有 L1、L2、L3 这样三层高速缓存,每个 CPU 核心都有一块属于自己的 L1 高速缓存,通常分成指令缓存和数据缓存,分开存放 CPU 使用的指令和数据
L1 的 Cache 往往就嵌在 CPU 核心的内部;
L2 的 Cache 同样是每个 CPU 核心都有的,不过它往往不在 CPU 核心的内部。所以,L2 Cache 的访问速度会比 L1 稍微慢一些。而 L3 Cache,则通常是多个 CPU 核心共用的,尺寸会更大一些,访问速度自然也就更慢一些。
DRAM 被称为“动态”存储器,是因为 DRAM 需要靠不断地“刷新”,才能保持数据被存储起来。DRAM 的一个比特,只需要一个晶体管和一个电容就能存储。所以,DRAM 在同样的物理空间下,能够存储的数据也就更多,也就是存储的“密度”更大。但是,因为数据是存储在电容里的,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问延时也就更长。
直接映射 Cache(Direct Mapped Cache直接映射
现代 CPU 已经很少使用直接映射 Cache 了,通常用的是组相连 Cache(set associative cache)
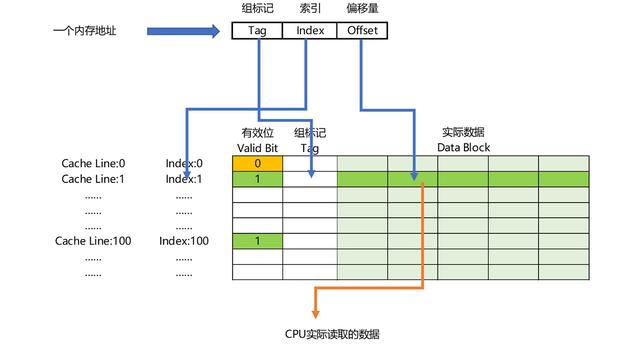
一个内存的访问地址,最终包括高位代表的组标记、低位代表的索引,以及在对应的 Data Block 中定位对应字的位置偏移量
volatile 关键字究竟代表它会确保我们对于这个变量的读取和写入,都一定会同步到主内存里,而不是从 Cache 里面读取
缓存同步 L1 L2 多核
总线嗅探机制和 MESI 协议
M:代表已修改(Modified)E:代表独占(Exclusive)S:代表共享(Shared)I:代表已失效(Invalidated)
这个策略,本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心
总线本身就是一个特别适合广播进行数据传输的机制,所以总线嗅探这个办法也是我们日常使用的 Intel CPU 进行缓存一致性处理的解决方案
映射表。
我们的内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而我们的程序看到的内存地址,都是虚拟内存地址。
TLB,全称是地址变换高速缓冲
我们通过页表这个数据结构来处理。为了节约页表的内存存储空间,我们会使用多级页表数据结构
不过,多级页表虽然节约了我们的存储空间,但是却带来了时间上的开销,变成了一个“以时间换空间”的策略。原本我们进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是用了 4 级页表,我们就需要访问 4 次内存,才能找到物理页号。
为了节约页表所需要的内存空间,我们采用了多级页表这样一个数据结构。但是,多级页表虽然节省空间了,却要花费更多的时间去多次访问内存。于是,我们在实际进行地址转换的 MMU 旁边放上了 TLB 这个用于地址转换的缓存。TLB 也像 CPU Cache 一样,分成指令和数据部分,也可以进行 L1、L2 这样的分层。
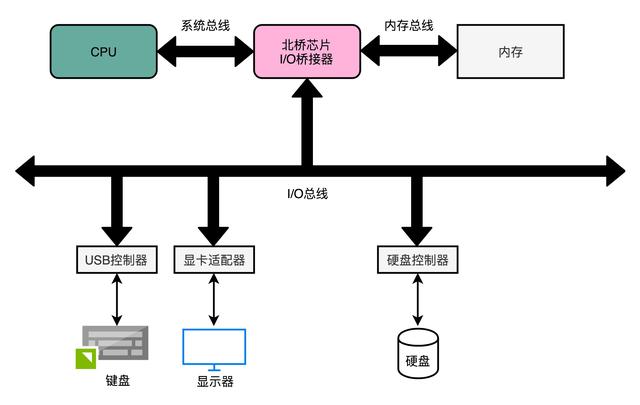
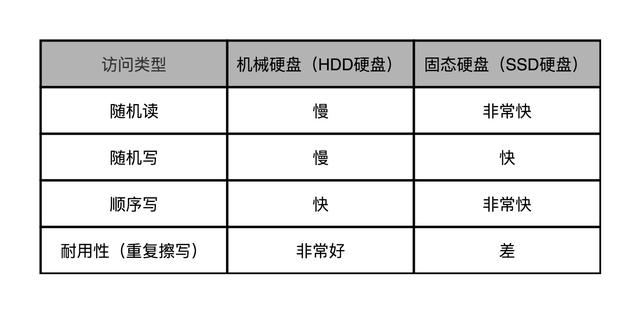
我们现在常用的硬盘有两种。一种是 HDD 硬盘,也就是我们常说的机械硬盘。另一种是 SSD 硬盘,一般也被叫作固态硬盘。现在的 HDD 硬盘,用的是 SATA 3.0 的接口。而 SSD 硬盘呢,通常会用两种接口,一部分用的也是 SATA 3.0 的接口;另一部分呢,用的是 PCI Express 的接口。现在我们常用的 SATA 3.0 的接口,带宽是 6Gb/s。这里的“b”是比特。这个带宽相当于每秒可以传输 768MB 的数据。而我们日常用的 HDD 硬盘的数据传输率,差不多在 200MB/s 左右。
SSD 硬盘能够更快,所以我们可以换用 PCI Express 的接口。我自己电脑的系统盘就是一块使用了 PCI Express 的三星 SSD 硬盘。它的数据传输率,在读取的时候就能做到 2GB/s 左右,差不多是 HDD 硬盘的 10 倍,而在写入的时候也能有 1.2GB/s
顺序读写和随机读写
随机读写的时候,数据传输率也只能到 40MB/s 左右,是顺序读写情况下的几十分之一。
在 top 命令的输出结果里面,有一行是以 %CPU 开头的。这一行里,有一个叫作 wa 的指标,这个指标就代表着 iowait,也就是 CPU 等待 IO 完成操作花费的时间占 CPU 的百分比。下一次,当你自己的服务器遇到性能瓶颈,load 很大的时候,你就可以通过 top 看一看这个指标。
我们看到,即使是用上了 PCI Express 接口的 SSD 硬盘,IOPS 也就是在 2 万左右。而我们的 CPU 的主频通常在 2GHz 以上,也就是每秒可以做 20 亿次操作。
这里的 tps 指标,其实就对应着我们上面所说的硬盘的 IOPS 性能。而 kB_read/s 和 kB_wrtn/s 指标,就对应着我们的数据传输率的指标。
通过 iotop 这个命令,你可以看到具体是哪一个进程实际占用了大量 I/O,那么你就可以有的放矢,去优化对应的程序了
每秒钟能够进行输入输出的操作次数,也就是 IOPS 这个核心性能指标。
如果随机在整个硬盘上找一个数据,需要 8-14 ms。我们的硬盘是机械结构的,只有一个电机转轴,也只有一个悬臂,所以我们没有办法并行地去定位或者读取数据。那一块 7200 转的硬盘,我们一秒钟随机的 IO 访问次数,也就是1s / 8 ms = 125 IOPS 或者 1s / 14ms = 70 IOPS
SSD 硬盘,我们也可以先简单地认为,它是由一个电容加上一个电压计组合在一起,
记录了一个或者多个比特。
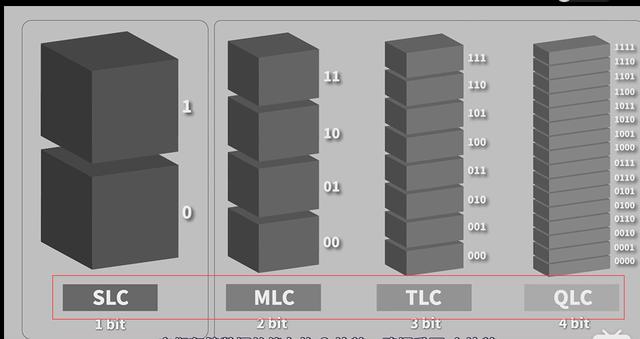
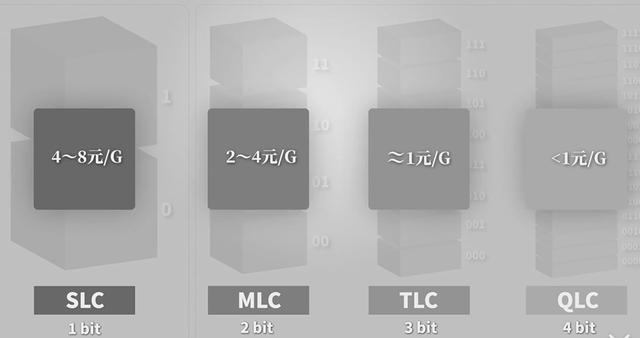
我们上面说的 SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右而 TLC 和 QLC 就只在几千次了
为什么ssd断电后不会丢数据
作者回复: 现在大家用的SSD的存储硬件都是NAND Flash。实现原理和通过改变电压,让电子进入绝缘层的浮栅(Floating Gate)内。断电之后,电子仍然在FG里面。但是如果长时间不通电,比如几年,仍然可能会丢数据。所以换句话说,SSD的确也不适合作为冷数据备份。
https://www.bilibili.com/video/av61437877
当 SSD 硬盘的存储空间被占用得越来越多,每一次写入新数据,我们都可能没有足够的空白。我们可能不得不去进行垃圾回收,合并一些块里面的页,然后再擦除掉一些页,才能匀出一些空间来。这个时候,从应用层或者操作系统层面来看,我们可能只是写入了一个 4KB 或者 4MB 的数据。但是,实际通过 FTL 之后,我们可能要去搬运 8MB、16MB 甚至更多的数据。我们通过“实际的闪存写入的数据量 / 系统通过 FTL 写入的数据量 = 写入放大”,可以得到,写入放大的倍数越多,意味着实际的 SSD 性能也就越差,会远远比不上实际 SSD 硬盘标称的指标。
尝试不停地提升 I/O 设备的速度。把 HDD 硬盘换成 SSD 硬盘,我们仍然觉得不够快;用 PCI Express 接口的 SSD 硬盘替代 SATA 接口的 SSD 硬盘,我们还是觉得不够快,所以,现在就有了傲腾(Optane)这样的技术
但是,无论 I/O 速度如何提升,比起 CPU,总还是太慢。SSD 硬盘的 IOPS 可以到 2 万、4 万,但是我们 CPU 的主频有 2GHz 以上,也就意味着每秒会有 20 亿次的操作。如果我们对于 I/O 的操作,都是由 CPU 发出对应的指令,然后等待 I/O 设备完成操作之后返回,那 CPU 有大量的时间其实都是在等待 I/O 设备完成操作。但是,这个 CPU 的等待,在很多时候,其实并没有太多的实际意义。我们对于 I/O 设备的大量操作,其实都只是把内存里面的数据,传输到 I/O 设备而已。在这种情况下,其实 CPU 只是在傻等而已。特别是当传输的数据量比较大的时候,比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。因此,计算机工程师们,就发明了 DMA 技术,
也就是直接内存访问(Direct Memory Access)技术,来减少 CPU 等待的时间
Kafka 是一个用来处理实时数据的管道,我们常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在 I/O 层面。Kafka 里面会有两种常见的海量数据传输的情况。一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。另一种情况呢,则是从本地磁盘上读取出来,通过网络发送出去。
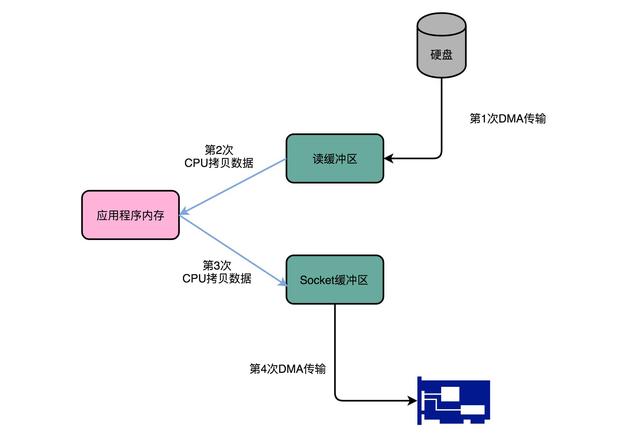
Kafka 做的事情就是,把这个数据搬运的次数,从上面的四次,变成了两次,并且只有 DMA 来进行数据搬运,而不需要 CPU
fileChannel.transferTo(position, count, socketChannel);
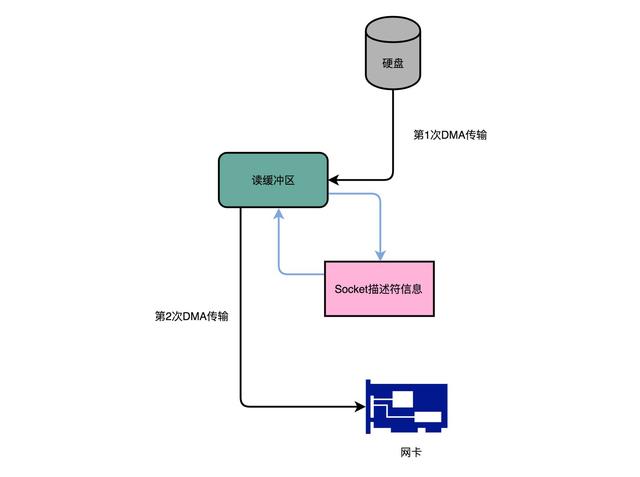
Kafka 的代码调用了 Java NIO 库,具体是 FileChannel 里面的 transferTo 方法。我们的数据并没有读到中间的应用内存里面,而是直接通过 Channel,写入到对应的网络设备里。并且,对于 Socket 的操作,也不是写入到 Socket 的 Buffer 里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。于是,在这个过程之中,我们只进行了两次数据传输。
单笔特翻转发生的概率是0.01%,那么两个比特都翻转概率就是0.000001%。 要解决这个问题成本会进一步大幅度上升,就没有必要在硬件层面这么干了。