本文转载自微信公众号「学习Java的小姐姐」,作者学习Java的小姐姐0618 。转载本文请联系学习Java的小姐姐公众号。
前言
hello,各位小可爱们,又见面了。今天这篇文章来自去年面试阅文的面试题,结果被虐了。这一part不说了,下次专门开一篇,写下我面试被虐的名场面,尴尬的不行,全程尬聊。哈哈哈哈,话不多说,开始把。😂
在Redis中Hash类型的应用非常广泛,其中key到value的映射就通过字典结构来维护的。记笔记,此处要考。
API使用
API的使用比较简单,所以以下就粗略的写了。
插入数据hset
使用hset命令往myhash中插入两个key,value的键值对,分别是(name,zhangsan)和(age,20),返回值当前的myhash的长度。

获取数据hget
使用hget命令获取myhash中key为name的value值。

获取所有数据hgetall
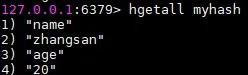
使用hgetall命令获取myhash中所有的key和value值。
获取所有key
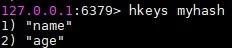
使用hkeys命令获取myhash中所有的key值。
获取长度
使用hlen命令获取myhash的长度。

获取所有value
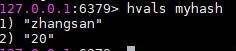
使用hvals命令获取myhash中所有的value值。
具体逻辑图
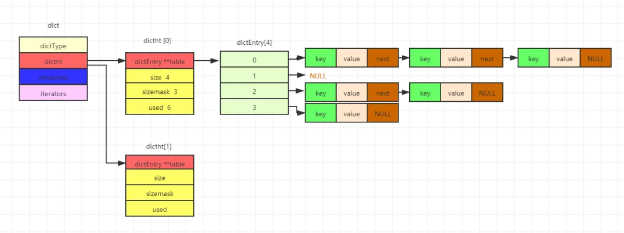
正文要开始了哈。hash的底层主要是采用字典dict的结构,整体呈现层层封装。
首先dict有四个部分组成,分别是dictType(类型,不咋重要),dictht(核心),rehashidx(渐进式hash的标志),iterators(迭代器),这里面最重要的就是dictht和rehashidx。
接下来是dictht,其有两个数组构成,一个是真正的数据存储位置,还有一个用于hash过程,包括的变量分别是真正的数据table和一些常见变量。
最后数据节点,和上篇说的双向链表一样,每个节点都有next指针,方便指向下一个节点,这样目的是为了解决hash碰撞。具体的可以看下图。
这边看不懂没关系,后面会针对每个模块详细说明。(千万不要看到这里就跳过啦)
双向链表的定义
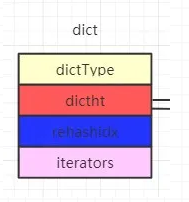
字典结构体dict
我们先看字典结构体dict,其包括四个部分,重点是dictht[2](真正的数据)和rehashidx(渐进式hash的标志)。具体图如下。
具体代码如下:
- //字典结构体
- typedef struct dict {
- dictType *type;//类型,包括一些自定义函数,这些函数使得key和value能够存储
- void *privdata;//私有数据
- dictht ht[2];//两张hash表
- long rehashidx; //渐进式hash标记,如果为-1,说明没在进行hash
- unsigned long iterators; //正在迭代的迭代器数量
- } dict;
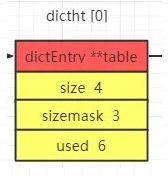
数组结构体dictht
dictht主要包括四个部分,1是真正的数据dictEntry类型的数组,里面存放的是数据节点;2是数组长度size;3是进行hash运算的参数sizemask,这个不咋重要,只要记住等于size-1;4是数据节点数量used,当前有多少个数据节点。
具体代码如下:
- //hash结构体
- typedef struct dictht {
- dictEntry **table;//真正数据的数组
- unsigned long size;//数组的大小
- unsigned long sizemask;//用户将hash映射到table的位置索引,他的值总是等于size-1
- unsigned long used;//已用节点数量
- } dictht;
数据节点dictEntry
dictEntry为真正的数据节点,包括key,value和next节点。
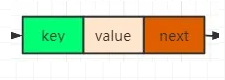
- //每个节点的结构体
- typedef struct dictEntry {
- void *key; //key
- union {
- void *val;
- uint64_t u64;
- int64_t s64;
- double d;
- } v;//value
- struct dictEntry *next; //下一个数据节点的地址
- } dictEntry;
扩容过程和渐进式Hash图解
我们先来第一个部分,dictht[2]为什么会要2个数组存放,真正的数据只要一个数组就够了?
这其实和Java的HashMap相似,都是数据加链表的结构,随着数据量的增加,hash碰撞发生的就越频繁,每个数组后面的链表就越长,整个链表显得非常累赘。如果业务需要大量查询操作,因为是链表,只能从头部开始查询,等一个数组的链表全部查询完才能开始下一个数组,这样查询时间将无限拉长。
这无疑是要进行扩容,所以第一个数组存放真正的数据,第二个数组用于扩容用。第一个数组中的节点经过hash运算映射到第二个数组上,然后依次进行。那么过程中还能对外提供服务吗?答案是可以的,因为他可以随时停止,这就到了下一个变量rehashidx。(一点都不生硬的转场,哈哈哈)
rehashidx其实是一个标志量,如果为-1说明当前没有扩容,如果不为-1则表示当前扩容到哪个下标位置,方便下次进行从该下标位置继续扩容。
这样说是不是太抽象了,还是一脸懵逼,贴心的送上扩容过程全解,一定要点赞评论多夸夸我哦。
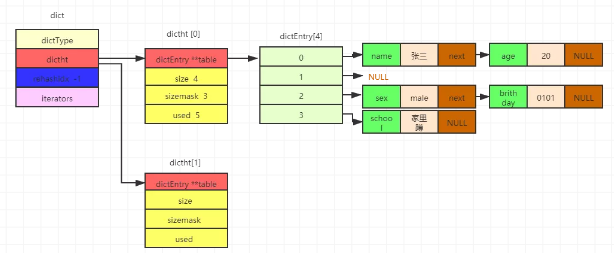
步骤1
首先是未扩容前,rehashidx为-1,表示未扩容,第一个数组的dictEntry长度为4,一共有5个节点,所以used为5。
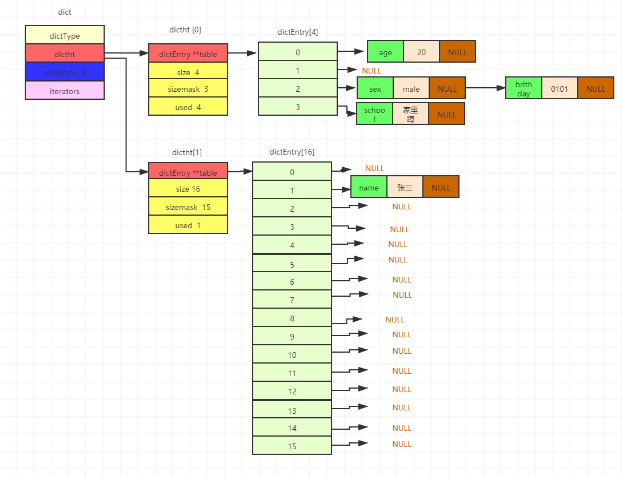
步骤2
当发生扩容了,rahashidx为第一个数组的第一个下标位置,即0。扩容之后的大小为大于used*2的2的n次方的最小值,即能包含这些节点*2的2的倍数的最小值。因为当前为5个数据节点,所以used*2=10,扩容后的数组大小为大于10的2的次方的最小值,为16。从第一个数组0下标位置开始,查找第一个元素,找到key为name,value为张三的节点,将其hash过,找到在第二个数组的下标为1的位置,将节点移过去,其实是指针的移动。这边就简单说了。
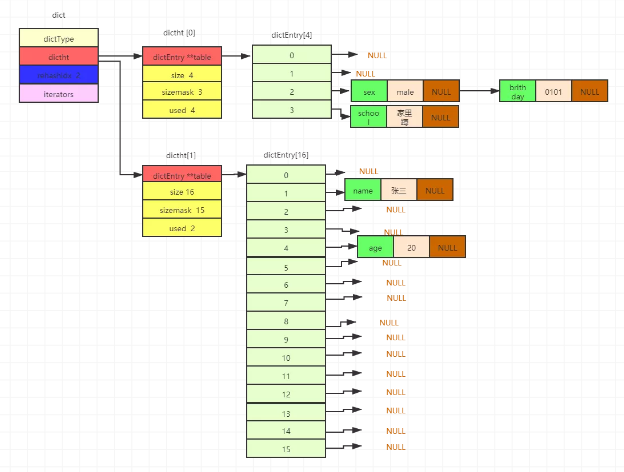
步骤3
key为name,value为张三的节点移动结束后,继续移动第一个数组dictht[0]的下标为0的后续节点,移动步骤和上面相同。
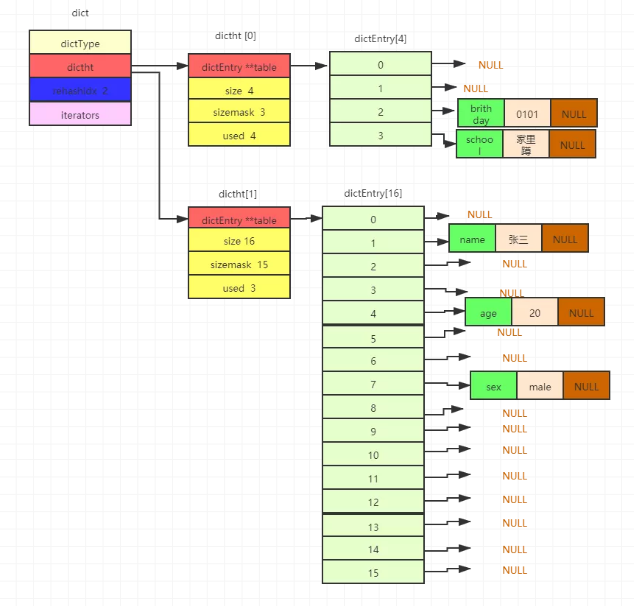
步骤4
继续移动第一个数组dictht[0]的下标为0的后续节点都移动完了,开始移动下标为1的节点,发现其没有数据,所以移动下标为2的节点,同时修改rehashidx为2,移动步骤和上面相同。
整个过程的重点在于rehashidx,其为第一个数组正在移动的下标位置,如果当前内存不够,或者操作系统繁忙,扩容的过程可以随时停止。
停止之后如果对该对象进行操作,那是什么样子的呢?
- 如果是新增,则直接新增后第二个数组,因为如果新增到第一个数组,以后还是要移过来,没必要浪费时间
- 如果是删除,更新,查询,则先查找第一个数组,如果没找到,则再查询第二个数组。
字典的实现(源码分析)
创建并初始化字典
首先分配内存,接着调用初始化方法_dictInit,主要是赋值操作,重点看下rehashidx赋值为-1(这验证了刚才的图解,-1表示未进行hash扩容),最后返回是否创建成功。
- /* 创建并初始化字典 */
- dict *dictCreate(dictType *type,void *privDataPtr)
- {
- dict *d = zmalloc(sizeof(*d));
- _dictInit(d,type,privDataPtr);
- return d;
- }
- /* Initialize the hash table */
- int _dictInit(dict *d, dictType *type,void *privDataPtr)
- {
- _dictReset(&d->ht[0]);
- _dictReset(&d->ht[1]);
- d->type = type;
- d->privdata = privDataPtr;
- d->rehashidx = -1;//赋值为-1,表示未进行hash
- d->iterators = 0;
- return DICT_OK;
- }
扩容
dict里面有一个静态方法_dictExpandIfNeed,判断是否需要扩容。
首先判断通过dictIsRehashing方法,判断是否处于hash状态,其调用的是宏常量#define dictIsRehashing(d) ((d)->rehashidx != -1),即判断rehashidx是否为-1,如果为-1,即不处于hash状态,if条件为false,可以进行扩容,如果不为-1,即处于hash状态,if条件为true,不可以进行扩容,直接返回常量DICT_OK。
接着判断第一个数组的size是否为0,如果为0,则扩容为默认大小4,如果不为0,则执行下面的代码。
再接着判断是否需要扩容,if中有三个条件,具体的分析如下。
最后就是调用dictExpand扩容方法了,参数为数据节点的双倍大小ht[0].used*2。此处验证了上面扩容过程的数组大小16。
扩容方法比较简单点,获取扩容后的大小,将第二个设置新的大小。
这样讲感觉有点空,看下流程图。
扩容流程图
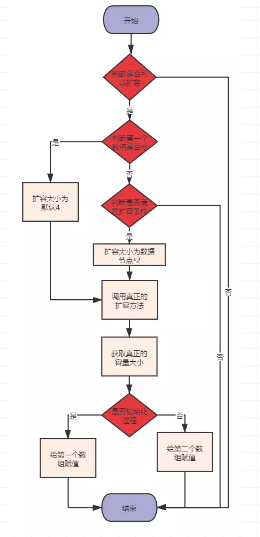
具体代码:
- static int _dictExpandIfNeeded(dict *d)
- {
- //判断是否处于扩容状态中,通过调用宏常量#define
- dictIsRehashing(d) ((d)->rehashidx != -1)
- //来判断是否可以扩容
- if (dictIsRehashing(d)) return DICT_OK;
- //判断第一个数组size是否为0,如果为0,则调用扩容方法,大小为宏常量
- //#define DICT_HT_INITIAL_SIZE 4
- if (d->ht[0].size == 0)
- return dictExpand(d, DICT_HT_INITIAL_SIZE);
- //下面先列出if条件中所使用到的参数
- // static int dict_can_resize = 1;数值为1表示可以扩容
- //static unsigned int dict_force_resize_ratio = 5;
- //我们来分析if条件,如果第一个数组的所有节点数量大于等于第一个数组的大小(表 示节点数据已经有些多)
- //并且可用扩容(数值为1)或者所有节点数量除以数组大小大于5
- //这个条件表示扩容那个的条件,第一个就是节点必要大于等于数组长度,
- //第二点就再可以扩容和数据太多,超过5两个中选其一
- if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||
- d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
- {
- //调用扩容方法
- return dictExpand(d, d->ht[0].used*2);
- }
- return DICT_OK;
- }
- int dictExpand(dict *d, unsigned long size)
- {
- dictht n;
- //获取扩容后真正的大小,找到比size大的最小值,且是2的倍数
- unsigned long realsize = _dictNextPower(size);
- //一些判断条件
- if (dictIsRehashing(d) || d->ht[0].used > size)
- return DICT_ERR;
- if (realsize == d->ht[0].size) return DICT_ERR;
- n.size = realsize;
- n.sizemask = realsize-1;
- n.table = zcalloc(realsize*sizeof(dictEntry*));
- n.used = 0;
- //第一个hash为null,说明在初始化
- if (d->ht[0].table == NULL) {
- d->ht[0] = n;
- return DICT_OK;
- }
- //正在hash,给第二个hash的长度设置新的,
- d->ht[1] = n;
- d->rehashidx = 0;//设置当前正在hash
- return DICT_OK;
- }
- /* 找到比size大的最小值,且是2的倍数 */
- static unsigned long _dictNextPower(unsigned long size)
- {
- unsigned long i = DICT_HT_INITIAL_SIZE;
- if (size >= LONG_MAX) return LONG_MAX;
- while(1) {
- if (i >= size)
- return i;
- i *= 2;
- }
- }
渐进式hash
渐进式hash过程已经通过上面图解说明,以下主要看下代码是如何实现的,以及过程是不是对的。
扩容之后就是执行dictRehash方法,参数包括待移动的哈希表d和步骤数字n。
首先判断标志量rehashidx是否等于-1,如果等于-1,则表示hash完成,如果不等于-1,则执行下面的代码。
接着进行循环,遍历第一个数组上的每个下标,每次移动下标位置,都需要更新rehashidx值,每次加1。
再接着进行第二个循环,遍历下标的链表每个节点,完成数据的迁移,主要是指针的移动和一些参数的修改。
最后,返回int数值,如果为0表示整个数据全部hash完成,如果返回1则表示部分hash结束,并没有全部完成,下次可以通过rehashidx值继续hash。
具体代码如下:
- //重新hash这个哈希表
- // Redis的哈希表结构共有两个table数组,t0和t1,平常只使用一个t0,当需要重hash时则重hash到另一个table数组中
- //参数列表
- // 1. d: 待移动的哈希表,结构中存有目前已经重hash到哪个桶了
- // 2. n: N步进行rehash
- // 返回值 返回0说明整个表都重hash完成了,返回1代表未完成
- int dictRehash(dict *d, int n) {
- int empty_visits = n*10;
- //如果当前rehashidx=-1,则返回0,表示hash完成
- if (!dictIsRehashing(d)) return 0;
- //分n步,而且ht[0]还有没有移动的节点
- while(n-- && d->ht[0].used != 0) {
- dictEntry *de, *nextde;
- assert(d->ht[0].size > (unsigned long)d->rehashidx);
- //第一个循环用来更新 rehashidx 的值,因为有些桶为空,所以 rehashidx并非每次都比原来前进一个位置,而是有可能前进几个位置,但最多不超过 10。
- //将rehashidx移动到ht[0]有节点的下标,也就是table[d->rehashidx]非空
- while(d->ht[0].table[d->rehashidx] == NULL) {
- d->rehashidx++;
- if (--empty_visits == 0) return 1;
- }
- //第二个循环用来将ht[0]表中每次找到的非空桶中的链表(或者就是单个节点)拷贝到ht[1]中
- de = d->ht[0].table[d->rehashidx];
- /* 利用循环将数据节点移过去 */
- while(de) {
- unsigned int h;
- nextde = de->next;
- h = dictHashKey(d, de->key) & d->ht[1].sizemask;
- de->next = d->ht[1].table[h];
- d->ht[1].table[h] = de;
- d->ht[0].used--;
- d->ht[1].used++;
- de = nextde;
- }
- d->ht[0].table[d->rehashidx] = NULL;
- d->rehashidx++;
- }
- if (d->ht[0].used == 0) {
- zfree(d->ht[0].table);
- d->ht[0] = d->ht[1];
- _dictReset(&d->ht[1]);
- d->rehashidx = -1;
- return 0;
- }
- return 1;
- }
总结
该篇主要讲了Redis的Hash数据类型的底层实现字典结构Dict,先从Hash的一些API使用,引出字典结构Dict,剖析了其三个主要组成部分,字典结构体Dict,数组结构体Dictht,数据节点结构体DictEntry,进而通过多幅过程图解释了扩容过程和rehash过程,最后结合源码对字典进行描述,如创建过程,扩容过程,渐进式hash过程,中间穿插流程图讲解。