在进行数据分析时,我们往往会遇到要对某个变量的影响因素进行分析的情况,而影响一事物的因素往往是很多的。比如在化工生产中,有温度、压力、剂量、反应时间等因素。每一因素的改变都有可能影响产品的数量和质量。我们往往要找出对产品质量有显著影响的那些因素。而方差分析就是根据试验的结果进行分析,鉴别各个有关因素对试验结果影响的有效方法,本文主要讲述如何用python中的两种方法来进行方差分析。
首先,还是先简介一下方差分析。
方差分析(Analysis of Variance,ANOVA)又称“变异数分析”或“F检验”,是由罗纳德·费舍尔(Ronald Aylmer Fisher)发明的,用于两个及两个以上样本均数差别的显著性检验,其原理是认为不同处理组的均数间的差别基本来源有两个:
(1) 实验条件,即不同的处理造成的差异,称为组间差异。用变量在各组的均值与总均值之偏差平方和的总和表示,记作SSa,组间自由度dfa。
(2) 随机误差,如测量误差造成的差异或个体间的差异,称为组内差异,用变量在各组的均值与该组内变量值之偏差平方和的总和表示, 记作SSe,组内自由度dfe。
总偏差平方和 SSt = SSa + SSe。
组内SSe、组间SSa除以各自的自由度(组内dfe =n-m,组间dfa=m-1,其中n为样本总数,m为组数),得到其均方MSe和MSa,一种情况是处理没有作用,即各组样本均来自同一总体,MSa/MSe≈1。另一种情况是处理确实有作用,组间均方是由于误差与不同处理共同导致的结果,即各样本来自不同总体。那么,MSa>>MSe(远大于)。
MSa/MSe比值构成F分布。用F值与其临界值比较,推断各样本是否来自相同的总体。
然后,我们再说明一下数据集。
数据集非常简单,只有5组数值,每组数值有4个,共20个数字。分别命名为group1、group2、group3、group4和group5,数值都是随意设置的,没有什么要求,这里大家也可以根据自己的意愿设置数据。在这里,笔者专门将数据量设置得比较小,这样方便观察数据的之间的差异,我们的重点是方差分析的方法,而这里我们主要讲的是单因素方差分析法。
group1 = [29.6, 24.3, 28.5, 32.0]
group2 = [27.3, 32.6, 30.8, 34.8]
group3 = [5.8, 6.2,11.0, 8.3]
group4 = [21.6, 17.4, 18.3, 19.0]
group5 = [29.2, 32.8, 25.0, 24.2]
设u1、u2、u3、u4和u5分别是这5个样本所属总体的均值,我们用单因素方差分析来检验下面的假设。
H0:u1=u2=u3=u4=u5
H1:u1、u2、u3、u4和u5不全相等
为了能更直观了解这5组数据,我们首先手工计算一下这些数据的相关参数。这5组数据的总体情况如图1所示。
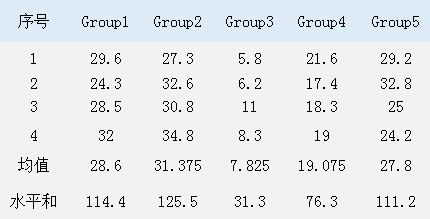
图1. 所用数据的基本情况
在图1中,每列数据就是一个水平,这是一个统计学用语,水平和就是每组4个数值的总和,每组数据平均值分别是a1=28.6,a2=31.375,a3=7.825,a4=19.075,a5=27.8,全部20个数据的平均值为A=(a1+a2+a3+a4+a5)/5=114.675/5=22.935。所以总偏差平方和为ST=1616.65,此值为20个数据中每个数据与A的差的平方的总和,误差平方和为SE=135.82,此值为每组数据中每个数据与这组数据的平均值的差的平方之和,效应平方和为SA=1480.83,此值为每组数据的平均值与A的差的平方之和,也等于ST减去SE的差。由此我们可以得出本例的方差分析表,如图2所示。
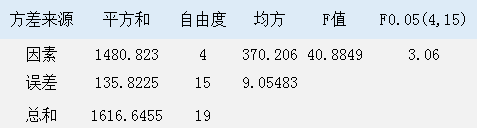
图2. 方差分析表
图2中的因素就是各组数据间的差异,这个可以是随机的,也可以是人为的,而误差就是每组数据的之间差异。我们可以看到本例中得到的F值为40.8848,远大于查表得到的F值F0.05(4,15),其值为3.06,至于F0.05(4,15)的值我们同样可以用python得出,后面会有讲解。
以上就是这个例子的手工计算过程,下面我们用python来计算一下该例。
方法1:scipy
方法1用的库是scipy,这是python中科学计算最常用的库,其代码如下,记得输入前面的5组数据。
- from scipy import stats
- F, p = stats.f_oneway(group1, group2, group3, group4, group5)
- F_test = stats.f.ppf((1-0.05), 4, 15)
- print('F值是%.2f,p值是%.9f' % (F,p))
- print('F_test的值是%.2f' % (F_test))
- if F>=F_test:
- print('拒绝原假设,u1、u2、u3、u4、u5不全相等')
- else:
- print('接受原假设,u1=u2=u3=u4=u5')
结果如图3所示。

图3. 方法1的计算结果
scipy的单因素方差分析比较简单,只要调用stats模块的f_oneway方法即可,在f_oneway中输入各组数据,然后会自动返回两个数值F与p,第一个数值F就表示我们算出的F值,和图2中的F值一样,而第二个值p就是这个F值所对应的概率,也就是假设检验问题中,由检验统计量的样本观察值得出的原假设可被拒绝的最小显著性水平。在这里我们既可以通过F值来判断,也可以通过p值来判断,因为F大于F_test,落入了拒绝域,所以拒绝原假设,而p值也远小于α分位数(这里为0.05),所以也拒绝原假设。而这里的F_test就是图2中的F0.05(4,15),计算方法就是用stats.f.ppf((1-0.05), 4, 15),这里ppf的意思是Percent point function,也就是百分点函数,它是Cumulative distribution function(累积分布函数)的逆运算,这里需要注意的是ppf的第一个参数要输入1-0.05,0.05也就是我们设定的显著性水平α,其值通常取0.05,而第二个和第三个参数是两个自由度,这两个自由度分别是4和15,其求法在前面原理部分已经讲过。
方法2:statsmodels
方法2用的是python的另一个统计学库statsmodels,其代码如下。
- import statsmodels.api as sm
- import pandas as pd
- from statsmodels.formula.api import ols
- num = sorted(['g1', 'g2', 'g3','g4', 'g5']*4)
- data = group1 + group2 + group3 + group4 + group5
- df = pd.DataFrame({'num':num, 'data': data})
- mod = ols('data ~ num', data=df).fit()
- ano_table = sm.stats.anova_lm(mod, typ=2)
- print(ano_table)
结果如图4所示。

图4. 方法2的计算结果
从图4中我们可以看到,得出的结果和前面手算以及scipy的结果一样(部分小数精度问题可以忽略不计),图中sum_sq列就表示平方和,df列就代表了自由度,这里还给出了p值就是PR(>F)列,信息比scipy要丰富一些。
从代码上来看,statsmodels也同样很简单,只比scipy稍微复杂了一点,但却提供了更多的信息。这里有几点要注意的。一是我们生成了一个名为num的变量和一个名为data的变量,这两个都是list类型,又用二者生成了名为df的pandas.DataFrame变量,这样做的原因是statsmodels中普遍使用DataFrame数据格式,如果使用list类型会更麻烦一些。而data是把前面group1到group5中的数据放在了一个list中,num则是存放每个数据所对应的数据组信息,g1就代表这个数值属于group1,g2则是对应group2,以此类推。这里还有一点要注意,就是num中数据格式最好是字符格式的,比如’a1’、‘num3’这样的,不要是数字格式的,比如1、3、6.9这样的,因为数字格式的数据很有可能会参与计算,最终的结果可能会出错。第二点是mod = ols('data ~ num', data=df).fit()中的公式data ~ num,很多人对这一点很困惑,这种公式的使用方法来自于python的另一个库patsy,其主要用于描述统计模型(尤其是线性模型),符号~前面的部分代表了y轴数据,后面的部分代表了x轴数据,根据这二者生成一个线性模型,ols中第二个参数data则是要输入的数据源,一般是DataFrame格式,前面公式中符号~前后的名称都要是data中的列名,这种方法确实有些奇怪,部分原因是patsy借鉴了R语言的一些用法。第三点是ano_table = sm.stats.anova_lm(mod, typ=2)中,typ=2的意思是DataFrame,typ共有3个值,分别是1、2和3,其中2代表了DataFrame格式。
总结
对比scipy和statsmodels这两种方法,可以说是各有优势。scipy是一个通用型库,其包含了科学计算的多种模块,统计分析只是其中一部分,而statsmodels是一个专门进行统计分析的库,二者在功能上有一些差别,statsmodels在统计分析上更专业一些。而scipy的语法更符合python常用的语法,statsmodels的语法有些接近于R语言,对初学者可能有些陌生。所以大家可以根据自己的需要来选择合适的方法。