本文转载自微信公众号「学习Java的小姐姐」,作者学习Java的小姐姐0618 。转载本文请联系学习Java的小姐姐公众号。
前言
hello,又见面了。不要问为什么,问就是勤劳。马上要开启爆更模式啦。
在Redis中链表List的应用非常广泛,但是Redis是采用C语言来写,底层采用双向链表实现(这边提一嘴,如果是科班出身或者大学有学过数据结构的同学,可以划走啦)。我们今天的重点就是双向链表。
API使用
先来使用一下API。如果之前有用过的同学,可以直接跳到下一小节。
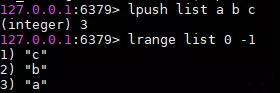
lpush左侧插入数据
使用lpush命令往list的左侧中插入a,b,c三个字符,这边注意顺序,查询出来的是c,b,a。下面会说为什么,先挖个坑。
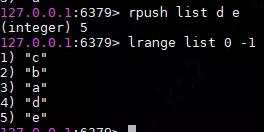
rpush右侧插入数据
使用rpush命令往list中插入d,e两个字符,查询出来的顺序是和我们想的一样,最后两位是d,e。
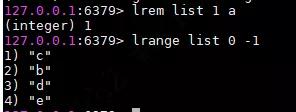
删除某个数据
使用lrem命令删除a字符,那么中间1代表什么意思呢?其为count,表示移除列表中与a相等的元素个数。即如果count>0,表示从表头开始向表尾搜索,移除count个与a相等的元素。如果count<0,表示从表尾开始向表头搜索,移除count个与a相等的元素。如果count=0,移除所有与a相等的元素,因为是移除所有,所以不管从表头还是表尾,结果是一样的。
修改某个数据
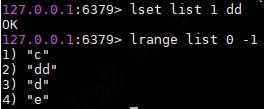
使用lset命令将mylist的下标为1的元素修改为dd,原来list为c ,b,d,e,修改后的结果为c,dd,d,e。
具体逻辑图
这边看不懂没关系,下面会针对每个模块详细说明。
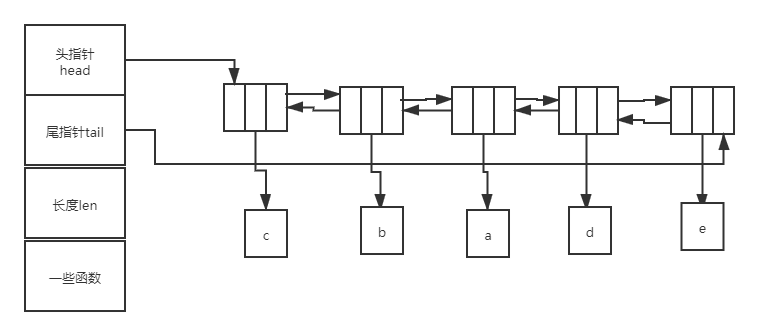
双向链表的定义
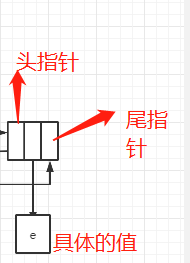
节点ListNode
包括头指针prev,尾指针next,当前的值value,如下图所示。每个节点都有两个指针,既能从表头根据尾指针找到表尾,又能从表尾根据头指针prev找到表头,如果将他们连起来,就构成了双向链表。
具体代码如下:
- //定义链表节点的结构体
- typedef struct listNode {
- //前面一个节点的指针
- struct listNode *prev;
- //后面一个节点的指针
- struct listNode *next;
- //当前节点的值的指针 ,因为值的类型不确定
- void *value;
- } listNode;
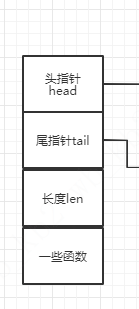
整体架构
包括头指针head,尾指针tail,整个链表长度len,一些函数(个人认为不重要,如果有知道的小伙伴欢迎评论),如下图所示。头指针head指向整个链表的第一个节点,尾指针tail指向整个链表的最后一个节点。
具体代码如下:
- //定义链表,对链表节点的再封装
- typedef struct list {
- listNode *head;//头指针
- listNode *tail;//尾指针
- void *(*dup)(void *ptr);//节点拷贝函数
- void (*free)(void *ptr);//释放节点值函数
- int (*match)(void *ptr, void *key);//判断两个节点是否相等函数
- unsigned long len;//链表长度
- } list;
双向链表的实现
创建表头
我们创建list表结构,首先需要判断当前是否有可分配的空间来创建,使用zmalloc方法来分配空间,如果分配不了,则返回NULL,如果可以分配,则继续。接着赋值list的头节点head和尾节点tail为NULL,len为0,赋值相关函数为NULL。最后返回结果list。
- //创建一个表头,返回值是链表结构的指针
- list *listCreate(void)
- {
- struct list *list;
- //尝试分配空间
- if ((list = zmalloc(sizeof(*list))) == NULL)
- return NULL;
- //相关属性赋值
- list->head = list->tail = NULL;
- list->len = 0;
- list->dup = NULL;
- list->free = NULL;
- list->match = NULL;
- //最终结果返回
- return list;
清空表
传入list的指针,首先定义当前节点current,使其指向头指针,定义len,使其等于list的长度。接着进行循环,每次len减一,定义新节点next,始终指向当前节点current的下一个节点,如果有值,则释放该节点,当前节点current后移,next节点同样后移。直到len为0,释放完所有节点,退出循环。最后赋值list的头节点head和尾节点tail为NULL,len为0。
注意:这边和SDS一样,清空并不是直接删除list,而是删除其数据,外层的list结构仍然存在。这其实上是惰性删除。
- void listEmpty(list *list)
- {
- unsigned long len;
- //定义两个节点指针current和next
- listNode *current, *next;
- //当前节点指针current指向list的头节点位置,即list的第一个数据
- current = list->head;
- //len为list的长度
- len = list->len;
- //开始循环,每次len减1
- while(len--) {
- //先让下一个指针指向下一个节点,因为底下直接释放当前节点,如果不在此处复制,底下就获取不到了
- next = current->next;
- //释放当前节点的值
- if (list->free) list->free(current->value);
- //释放当前节点
- zfree(current);
- //当前节点等于刚才的下一个节点next,即开始往后移,开始下一轮循环
- current = next;
- }
- //释放完给头指针head,尾指针tail赋值为NULL
- list->head = list->tail = NULL;
- //len赋值0
- list->len = 0;
- }
添加元素到表头
添加元素到表头,首先新建一个新节点node,判断是否有内存分配,如果有,则继续,如果没有,则返回NULL,退出方法。这边新节点是用来存在输入参数中的value的,所以需要内存。接着将新节点node的value值赋值为输入参数value。最后需要调整list的头指针,尾指针,原来第一个节点的指针情况(这边看下图,描述起来有点混乱,图片一目了然)。最最后,就是list的len加1,返回list。
举个例子,如果要在list中插入节点f,首先将节点的头指针赋值为空(对应步骤1),然后将新节点的尾指针next指向第一个节点(对应步骤2),将第一个节点的prev指向新节点(对应步骤3),最后将list的头指针head指向新节点(对应步骤4)。这边需要注意的是,步骤2和步骤3需要在步骤4前面,不然会找到第一个节点。
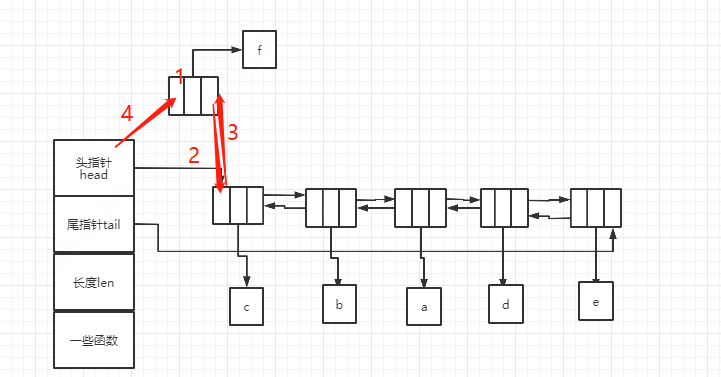
具体代码如下:
- //添加一个元素到表头
- list *listAddNodeHead(list *list, void *value)
- {
- listNode *node;
- if ((node = zmalloc(sizeof(*node))) == NULL)
- return NULL;
- node->value = value;//为当前节点赋值
- //如果当前list为空
- if (list->len == 0) {
- list->head = list->tail = node;//头尾指针都指向该节点
- node->prev = node->next = NULL;//当前节点的头尾指针都为null
- } else {//如果当前list不为空
- node->prev = NULL;//新节点的头指针为null
- node->next = list->head;//新节点的尾指针指向原来的尾指针
- list->head->prev = node;//原来的第一个节点的头指针指向新节点
- list->head = node;//链表的头指针指向新节点
- }
- list->len++;//list长度+1
- return list;
- }
添加元素到表尾
添加元素到表尾,首先新建一个新节点node,判断是否有内存分配,如果有,则继续,如果没有,则返回NULL,退出方法。这边新节点是用来存在输入参数中的value的,所以需要内存。接着将新节点node的value值赋值为输入参数value。最后需要调整list的头指针,尾指针,原来最后一个节点的指针情况(这边看下图,描述起来有点混乱,图片一目了然)。最最后,就是list的len加1,返回list。
举个例子,如果要在list中插入节点f,首先将节点的尾指针赋值为空(对应步骤1),然后将新节点的头指针指向最后一个节点(对应步骤2),将最后一个节点的next指向新节点(对应步骤3),最后将list的尾指针tail指向新节点(对应步骤4)。
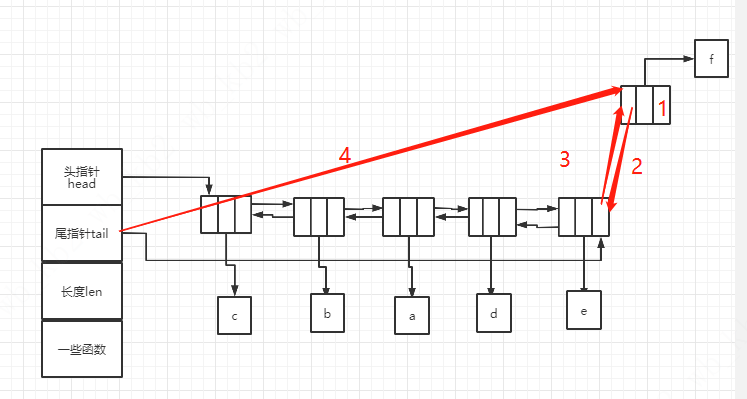
步骤如下:
- //添加元素到表尾
- list *listAddNodeTail(list *list, void *value)
- {
- //新建节点node
- listNode *node;
- //尝试分配内存
- if ((node = zmalloc(sizeof(*node))) == NULL)
- return NULL;
- //为新节点node赋值
- node->value = value;
- //调整指针
- if (list->len == 0) {
- list->head = list->tail = node;
- node->prev = node->next = NULL;
- } else {
- node->prev = list->tail;
- node->next = NULL;
- list->tail->next = node;
- list->tail = node;
- }
- //len加1
- list->len++;
- return list;
- }
插入
为list的某个节点old_node的after(大于0为前面新增,小于0为后面新增)新增新值value,首先新建一个新节点node,判断是否有内存分配,如果有,则继续,如果没有,则返回NULL,退出方法。这边新节点是用来存在输入参数中的value的,所以需要内存。接着根据after的值确定是在节点old_node的前面新增数据,还是在节点old_node的后面新增数据,具体的是指针的调整。最后len加1,返回list。
- //在list的某个位置old_node的after(前后)插入value值
- list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
- listNode *node;
- if ((node = zmalloc(sizeof(*node))) == NULL)
- return NULL;
- node->value = value;
- if (after) {//大于0
- node->prev = old_node;
- node->next = old_node->next;
- if (list->tail == old_node) {
- list->tail = node;
- }
- } else {//小于0
- node->next = old_node;
- node->prev = old_node->prev;
- if (list->head == old_node) {
- list->head = node;
- }
- }
- if (node->prev != NULL) {
- node->prev->next = node;
- }
- if (node->next != NULL) {
- node->next->prev = node;
- }
- list->len++;
- return list;
- }
删除
从list中删除节点node,如果该节点的前面存在节点,使其前面一个节点的next指针指向node后面一个节点的地址,其实就是跳过了node节点,如果该节点的前面不存在节点,则将list的头指针指向node的下一节点地址。同样的,如果该节点的后面存在节点,逻辑一样的。最后释放要删除的节点node内存,len减1。
- //从链表list中删除某个节点node
- void listDelNode(list *list, listNode *node)
- {
- //如果该节点的前面存在节点
- if (node->prev)
- node->prev->next = node->next;
- else
- list->head = node->next;
- //如果该节点的前面存在节点
- if (node->next)
- node->next->prev = node->prev;
- else
- list->tail = node->prev;
- //释放当前节点node的值
- if (list->free) list->free(node->value);
- //释放内存
- zfree(node);
- //len-1
- list->len--;
- }
总结
该篇主要讲了Redis的list数据类型的底层实现双向链表adlist,先从list的一些API使用,引出双向链表数据结构,进而结合源码对双向链表进行描述,包括节点listNode和list的头指针和尾指针,最后针对list的往表头插入元素,往表尾插入元素,删除,修改等方法进行源码解析,使其对双向链表有更清晰的认识。
如果觉得写得还行,麻烦给个赞👍,您的认可才是我写作的动力!