













本篇文章很短,但信息量很大,是关于redis的zset。我来分享一点遇到过的线上数据,或许对你的决策有帮助。
redis支持一个数据结构,叫做 zset,也就是有序的列表。当然redis也不能滥用,可以看我以前的规范文章:《这可能是最中肯的Redis规范了》
忘了zset是个啥的同学可以看这张gif图。
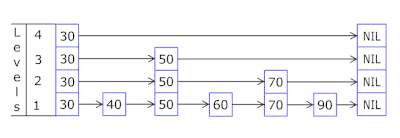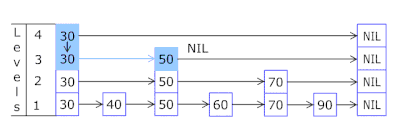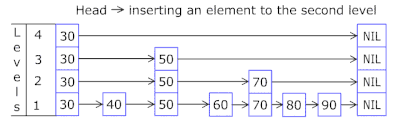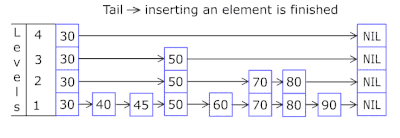
通过它,可以实现游戏排行榜一类的功能,或者实现Topx这样的需求,也能精准的让用户在海量数据中找到自己的位置。
zset的底层结构是跳跃表,而与之类似的Java中的有序Set是TreeSet,使用红黑树实现的。
concurrent包里面,还有一个类叫做ConcurrentSkipListMap,从它的名字就可以看出来,也是用跳跃表实现的,这个和zset最像。
好了,这是前提。广度面试的时候我也会这么问。
我们的问题是:zset中能存放多少条记录?线上有没有有说服力的数据?
先笼统的回答一下,zset理论上支持的元素最多是2^32-1个,约42亿,如果你的内存够大,放下国人绰绰有余。
使用redis-benchmark去测这个效果,不是很可信,测试用例写起来也比较费劲。测完了也不一定信,那就让线上流量去冲击吧。
为了应付产品的需求,我把用户按照省市进行了划分(geohash),结果,用户分布最大的就是广东省,非常棒。
在广东省的zset里,存放了接近6千万的数据,我们就要算在这6千万内任何人的排行。zcard、zrank等一系列操作,easy实现。
运行一段时间后,内存直接飙升到了8G左右。这是由于跳表的特殊结构所引起的,额外的辅助信息会占用更多的内存。
以下是经验值:
- 最高TPS写入量1k/秒。
- 同时最高QPS查询量5k/秒。
- 平均耗时5ms左右。
- 百分之95的请求都在10ms以内返回。
- 长尾请求超过100ms的不超过100条。
也就是说,在保持高写入和高查询的同时,zset能够保证较低的响应耗时。
你要说再多,我就不知道了,看这些数据,或许还能够再升一把。但要让服务要尽量的稳,压力尽量的分散,就不能太过苛刻,对这个数据我已经很满意了。
这只是一个省份的数据。如果综合起来,上层的业务,就需要承载10w/s的请求。这是非常容易的,但也没有意义,许多高并发经验都是这么吹上去的,要不要去改改简历?
复杂业务高并发才有价值,10w/s请求,给我两台redis就够了,没必要拿来吹。
但也是被zset的性能震惊了一把。跳表的结构,也了解一些,没想到在高并发大数据量场景下,能这么快。
测试数据?没有。本文只是分享一个经验值。对了,redis几乎不占用CPU,你只需要一台2core16gb的服务器就可以了。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
















