本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
数据增强技术已经是CV领域的标配,比如对图像的旋转、镜像、高斯白噪声等等。
但在NLP领域,针对文本的数据增强,却是不那么多见。
于是,就有一位机器学习T型工程师,在现有的文献中,汇总一些NLP数据增强技术。
妥妥干货,在此放送。
文本替代
文本替代主要是针对在不改变句子含义的情况下,替换文本中的单词,比如,同义词替换、词嵌入替换等等。
接着,我们就来好好介绍一下。
同义词替换
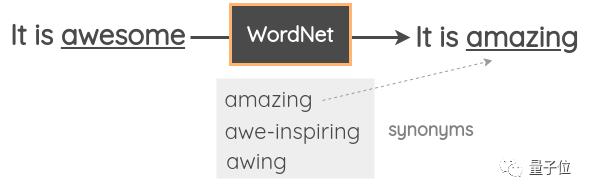
顾名思义,就是在文本中随机抽取一个单词,然后再同义词库里将其替换为同义词。
比如,使用WordNet数据库,将「awesome」替换为「amazing」。
这个技术比较常见,在以往的论文中有很多都使用了这个技术,比如,
Zhang et al.「Character-level Convolutional Networks for Text Classification」
论文链接:
https://arxiv.org/abs/1509.01626
Wei et al. 「EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks」
论文链接:
https://arxiv.org/abs/1901.11196
要实现这项技术,可通过NLTK对WordNet进行访问,还可以使用TextBlob API。
此外,还有一个PPDB数据库,包含着百万个单词的词库。
词嵌入替换
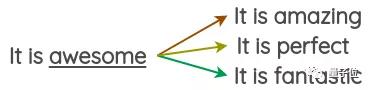
这种方法是,采取已经预训练好的单词嵌入,如Word2Vec、GloVe、FastText、Sent2Vec等,并将嵌入空间中最近的邻接词作为句子中某些单词的替换。
比如:

这样,就可以将单词替换成临近的3个单词,获得文本的3种变体形式。
掩码语言模型(MLM)
类似于BERT、ROBERTA、ALBERT,Transformer模型已经在大量的文本训练过,使用掩码语言模型的前置任务。
在这个任务中,模型必须依照上下文来预测掩码的单词。此外,还可以利用这一点,对文本进行扩容。

跟之前的方法相比,生成的文本在语法上会更加连贯。
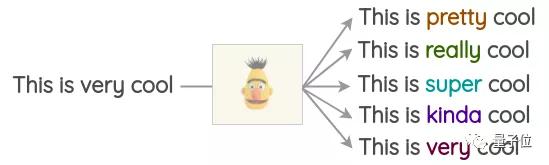
但是,需要注意的是,决定掩盖哪一个单词并非易事,它决定了效果的最终呈现。
基于TF-IDF的单词替换
这一方法最初是出现在Xie et al.「Unsupervised Data Augmentation for Consistency Training」。
论文链接:
https://arxiv.org/abs/1904.12848
基本思路在于TF-IDF得分低的单词是没有信息量的的词,因此可以替换,而不影响句子的原本含义。

通过计算整个文档中单词的 TF - IDF得分并取最低得分来选择替换原始单词的单词。
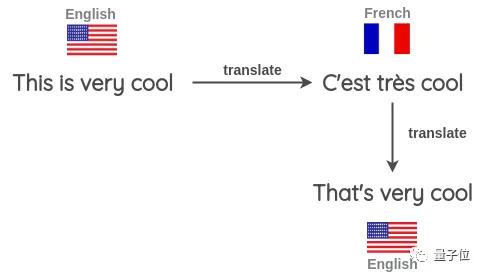
反向翻译
反向翻译,就是先将句子翻译成另一种语言,比如,英语翻译成法语。
然后再翻译回原来的语言,也就是将法语翻译回英语。
检查两个句子之间的不同之处,由此将新的句子作为增强文本。
还可以一次使用多种语言进行反向翻译,产生更多的变体。
比如,除了法语以外,再将其翻译为汉语和意大利语。
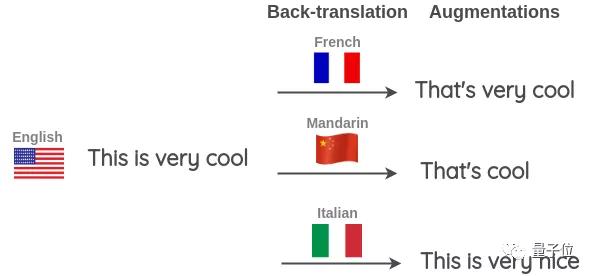
要实现反向翻译,可以使用TextBlob。另外,还可以使用Google Sheets,说明书已附文末。
文本形式转换
这一方法主要是利用正则表达式应用的的简单模式匹配转换,在Claude Coulombe的论文「Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs」中有详细介绍。
论文链接:
https://arxiv.org/abs/1812.04718
举个简单的例子,将原本形式转换为缩写,反之亦然。

但是也会出现一些歧义,比如:
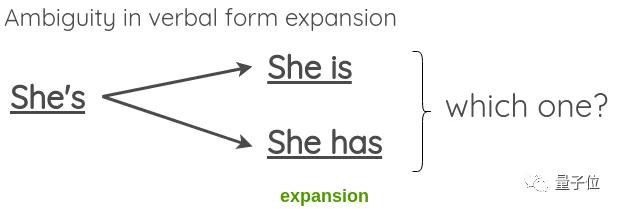
在此,选择允许歧义的收缩,但不允许扩展。
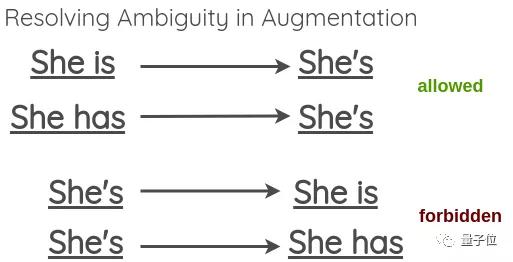
Python的收缩库已附文末。
随机噪声注入
顾名思义,也就是在文本中注入噪声,来训练模型对扰动的鲁棒性。
比如,拼写错误。

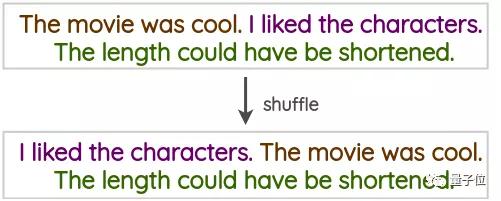
句子改组。
空白噪声。

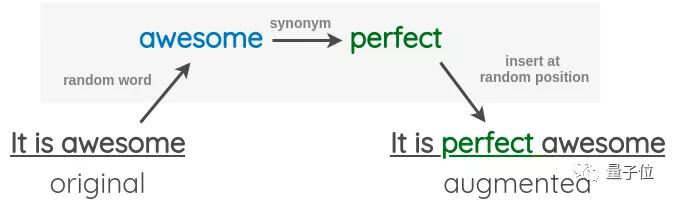
随机插入。
随机交换。

随机删除。

语法树
这一方法也出现在了Claude Coulombe的论文「Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs」中。
论文链接:
https://arxiv.org/abs/1812.04718
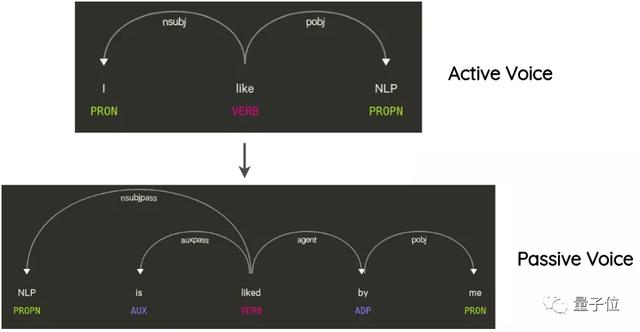
其思路是解析并生成原句的从属树,利用规则进行转换,生成新句子。
比如,将句子的主动语气转换为被动语气,反之亦然。
文本混合
这项技术的想法源于一项名为“Mixup”的图像增强技术。

Guo et al.在此基础上进行了修改,将其应用到NLP。
「Augmenting Data with Mixup for Sentence Classification: An Empirical Study」
论文链接:
https://arxiv.org/abs/1905.08941
主要有两种方法。
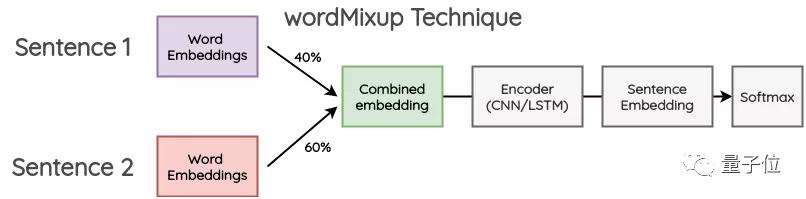
wordMixup
这个方法在于,抽取两个随机的句子,将它们进行零填充,使其长度相同。然后,按一定比例组合在一起。
所得到的单词嵌入通过CNN/LSTM编码器传递到句子嵌入中,随后计算交叉熵损失。
sentMixup
可以看到这一方法,与上述方法类似,只不过在具体步骤上有所调整。
好了,NLP的数据增强技术就介绍到这里,希望能够对你有所帮助。
传送门
博客地址:
https://amitness.com/2020/05/data-augmentation-for-nlp/
WordNet数据集:
https://www.nltk.org/howto/wordnet.html
TextBlob API:https://textblob.readthedocs.io/en/dev/quickstart.html#wordnet-integration
PPDB数据集:http://paraphrase.org/#/download
YF-IDF代码:
https://github.com/google-research/uda/blob/master/text/augmentation/word_level_augment.py
使用Google Sheets实现反向翻译:
https://amitness.com/2020/02/back-translation-in-google-sheets/
Python收缩库:
https://github.com/kootenpv/contractions