在python中,我们经常用列表,字典等数据类型进行数据存储或者重新构造一个序列,同时它们之间也有着一些关联关系,接下来我们就对python中常用的几种数据类型进行一个整体性的梳理。
区别
相同点
- 都相当于一个容器,有存放数据的功能
- 都可以用for ... in 进行循环
不同点
- 序列存放的是不同类型的数据,迭代器中存放的是算法。
- 序列是将数据提前存放好,获取数据时通过循环或索引来取数据 ;而迭代器不需要存放数据,获取数据时通过算法获取下一个数据 。
- 序列中的每一个数据都要开辟内存空间;而迭代器并不需要,它每次只需要通过算法计算出下一个值即可。从这个角度来看,如果进行大数据量处理,使用迭代器更合适 。
- 序列可以通过索引或键名来获取某一个值,而迭代器只能使用next()获取下一个值。
变化趋势
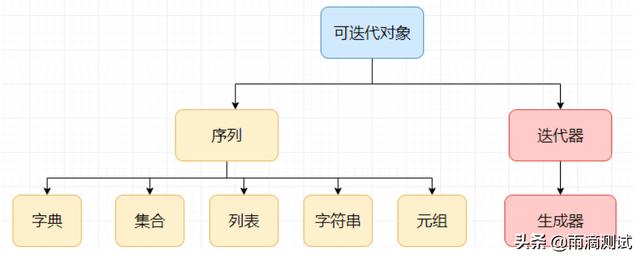
从左到右,可以试图找一些规律 。
- 从对数据的排序来看,从左到右可以看出是无序的,有序的,有规则(也可以定义成有序的)
- 从对数据的操作灵活度来看,左边的操作性更加灵活,可以进行增删改查 ;右边相对来说比较单一只能进行查询 (注意:定义后的字符串就只能进行查询,通过方法生成的字符串并不是原来的字符串了)。若想关注这些数据类型中的具体方法,可参考:python的5种数据结构,方法很多记不住吗?全在这里了.
- 从定义数据类型的符号来看,也是遵循汉字的大-中-小-引 来实现的,如字典|集合是大括号,列表是中括号,元组是小括号,字符串为双引号或单引号。
数据类型间的相互转化
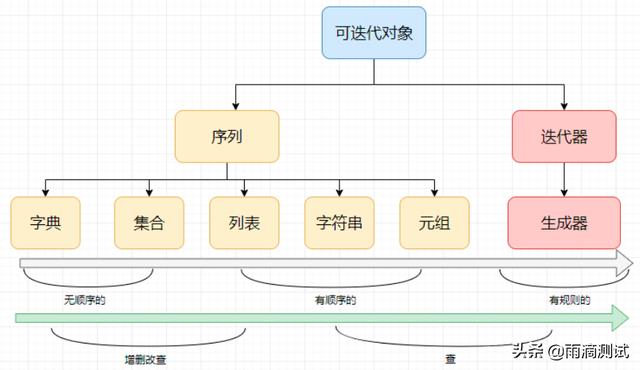
以上不同的数据类型,也可以实现两者之间的相互转化,转化时只需要通过调用对应函数即可,如下图
下图是每种数据类型间的相互转化及具体实例。
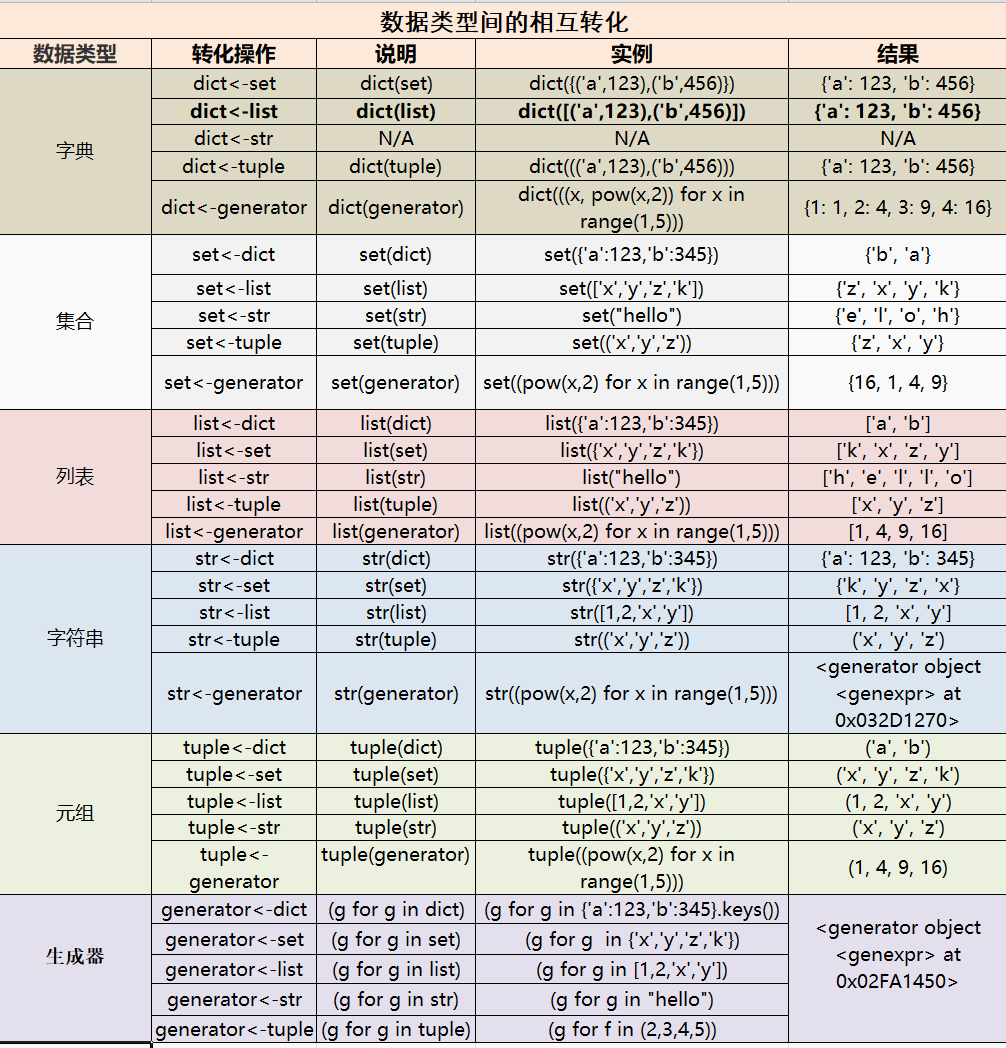
通过以上的表格可以看出,数据类型可以进行相互转化,总结有以下几点:
- 无论转化为什么数据类型,都是通过关键字将具体的数据类型括起来,如元组转化为列表:list(tuple)
- 转化为字典时需要注意的是,必须每两个数据为一组,用括号括起来,这样才能正确的生成字典的键值对,如果是一个元素转化时会报错 。
- 转化为字符串时需要注意的是,虽然通过str(data)可以转化为字符串,但很多情况并非是我们想要的,我们更想要的是将序列中的元素组合起来变成一个字符串 ,如果想实现这样的需求,就可以使用join()方法实现。
转化为字典时必须要求是两个元素组合成一个元组才能进行转化 。那为了简便我们可以使用zip()将两个序列组成一个新的字典更加方便。
# 通过zip将两个列表合并为一个序列,然后再转化为字典。
lst1 = ['x','y','z'] #可以是一个列表,元组,集合
lst2 = [123,234,345]
print(dict(zip(lst1,lst2)))
#输出:
{'x': 345, 'y': 234, 'z': 123}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
通过str()进行转化后的数据虽然变成了字符串,但是我们更想的是把序列中的元素结合起来变为字符串 。那么可以通过join()方法将其内的元素变为想要的字符串。
#语法:
"sep".join(seq)
#实例:
x = "".join({'a':123,'b':345})
print("x:",x)
y = ",".join(['java','python','c++'])
print("y:",y)
z = "_".join(("tuple","demo","01"))
#输出:
x: ab
y: java,python,c++
z: tuple_demo_01
#说明:
sep为分隔符,seq序列
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
便捷式写法-推导式
在以上的数据结构中,部分数据类型同样支持推导式,推导式是可以将一个可迭代对象构建成新的可迭代对象的表达式结构体 。通过推导式可以快速实现出一个新的序列或生成器 ,也可以让代码更加优雅和快捷 。
为了更加直观,我们可以一张图来总结不同数据类型所支持的推导式。我们只需要记住推导式的433.
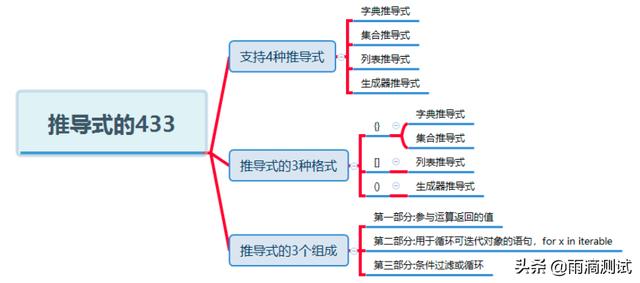
字典推导式
#语法:
{<operation_key:operation_value> for key,value in dict condition }
#实例:
d = {'chinese': 88, 'math': 92, 'english': 93, 'history': 84}
print("成绩大于90分的科目:", {k: '优秀' for k, v in d.items() if v >= 90})
#输出
成绩大于90分的科目: {'math': '优秀', 'english': '优秀'}
#说明:
for循环后的表达式可以是条件表达式或者循环表达式,主要是进行筛选或嵌套循环
返回结果是一个根据表达式运算后生成出来的新字典 。
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
集合推导式:
#语法:
{<operation_key:x> for x in set condition }
#实例
s = {x**2 for x in [1, 2, 3]}
print("集合s:",s)
#输出:
集合s: {1, 4, 9}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
列表推导式
#语法:
[ operation(x) for x in list condition ]
#实例
print([random.randint(1,10)+x for x in range(0,10) if x % 2 == 0])
#结果:
[3, 3, 14, 15, 12]
#说明:
#对列表推导式常使用的几种用法
用法1:[x for x in iterable ] #循环后直接打印
用法2:[x for x in iterable if condition(x) ] #对x的条件判断
用法3:[operation(x) for x iterable if condition(x)] #对x条件判断后,再对x进行运算
用法4: [operation(x,y) for x in iterable for y in iterable1] #嵌套循环,对x,y进行运算
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
生成器推导式
#语法:
( operation(x) for x in iterable condition )
#实例
print((random.randint(1,10)+x for x in range(0,10) if x % 2 == 0))
#结果:
<generator object <genexpr> at 0x02FDC420>
#说明:
新生成的生成器可以使用for循环,也可以next()获取其下一个值
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
组合用法
以上数据结构除了可以作为容器使用,也可以它们结合起来使用,以用作其它用途 。比如可以用作条件语句。为了直观,我们先写一个简单的if语句。
score = 92
if score >= 90:
print('优秀')
else:
print('良好')
#输出:优秀
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
接下来,我们就通过以下这三种方式来重新定义条件语句。
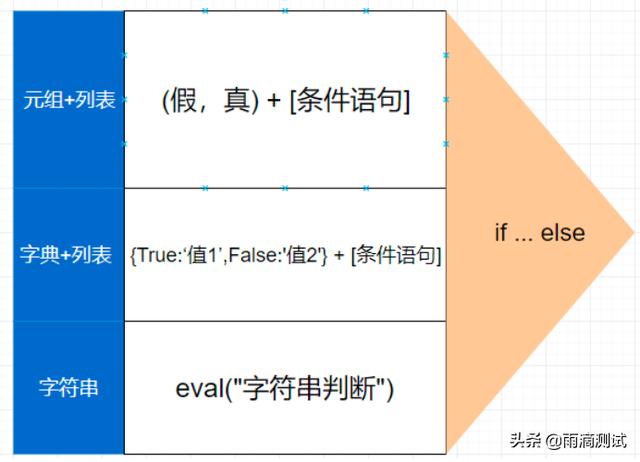
第一种,使用()+[]来实现条件判断
#语法:
(<return_false>, <return_true>)[condition_expression]
#实例:
score = 92
print(('良好','优秀')[ score >= 90 ])
#结果:
优秀
#说明:
在[]中写条件语句,在()中写返回为真和返回为假的值。一定要注意顺序,()在前,[]在后
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
第二种,使用{}+[]来实现条件判断
#语法:
{True: <return_true>, False: <return_false>}[<condition_expression>]
#实例:
score = 92
print({True:'优秀',False:'良好'}[ score >= 90 ])
#结果:
优秀
#说明:
在[]中写条件语句,在()中写返回为真和返回为假的值,一定要注意顺序
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
第三种,对字符串进行条件判断 ,需要用到eval方法。
#语法:
eval("字符串判断语句")
#实例
print('优秀' if eval("score >= 90") else '良好')
#结果
优秀
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.