数据标注是大多数人工智能的基础,它决定了机器学习和深度学习模型的质量。今天的数据呈现指数级的爆发,比如仅在2018年,就产生了超过30 ZB的数据。而在在任何人工智能项目中,对于数据科学家而言,数据问题都是其中的症结所在。
什么是数据标注?
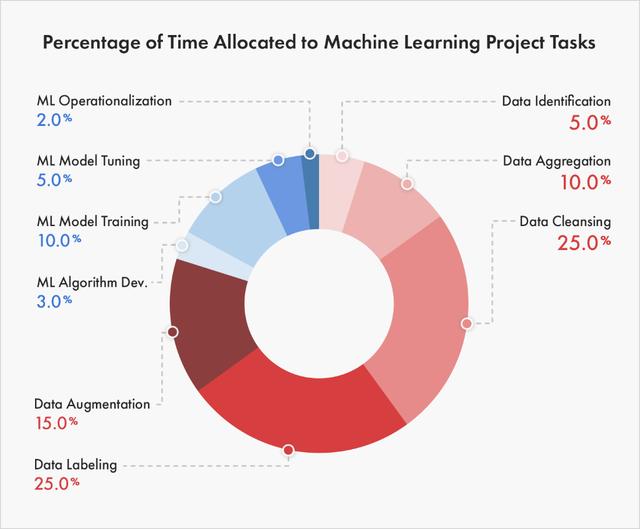
训练机器学习和深度学习模型,需要丰富的数据,以便将其用于部署,训练和调整模型。训练机器学习和深度学习模型需要大量经过仔细标注的数据。标注原始数据并准备将其应用于机器学习模型和其他AI工作流,被称为数据标注。根据相关统计,数据整理在AI项目中消耗了80%以上的时间。
数据如何标注?
如今,大多数数据都没有标注。带标签的数据,意味着标注或注释目标模型的数据,以便可以预测。通常,数据标注包括数据标注,注释,审核,分类,转录和处理。
标注的数据突出显示某些特征,并根据这些特征对其进行分类,可以通过模型分析其模式以预测新的目标。例如,对于自动驾驶汽车中的计算机视觉,AI专业人员或数据标注者可以使用视频标注工具来指示路牌的位置,并通过行人和其他车辆的位置来训练模型。
数据标注中包含的一系列任务:
- 丰富数据的工具
- 质量保证
- 流程迭代
- 管理数据标签
- 培训新的数据标签
- 项目计划
- 成功指标
- 流程运作
AI专业人员的数据标签挑战?
在典型的AI项目中,专业人员在进行数据标注时会遇到以下几个方面的挑战。
- 数据标签质量低下。数据标签质量低可能有很多原因。其中最突出的原因之一是任何企业或工作流程确实三个决定因素:人员,流程和技术。
- 无法扩展数据标注操作。当数据量不断增长并且业务或项目需要扩展其容量时,由于大多数企业都在内部标记数据,因此它们通常也难以扩展其数据标注任务。
- 难以承受的成本和不存在的结果。企业和AI项目经理通常雇用高薪数据科学家和AI专业人士或一组业余人员来处理数据标签,而企业需要承担高昂的人工成本,当然企业也会面临数据标签不确定所带来的问题,所以合适的专业人员至关重要。
- 质量保证。进行质量检查可以为数据标注过程提供重要价值,尤其是在机器学习模型测试和验证的迭代阶段。
谁来标注数据?
相关调查显示,2019年,企业在数据标签上的支出超过17亿美元。到2024年,这一数字将达到41亿美元。进行数据标注工作,除了雇佣专业的数据科学家和AI专家之外,还可以考虑通过其他方式。
雇员。这包括雇用包括AI专业人员在内的全职或兼职员工,参与AI项目的各个方面,其中之一是数据标注。
托管团队。他们是经验丰富,且训练有素的数据标签团队。
承包商。他们包括自由职业者和临时工。
众包。企业可以使用第三方平台一次性寻找数据标注团队。