窗口函数对数据组进行操作,并为每个记录或组返回值
> Photo by Tom Blackout on Unsplash
在此博客文章中,我们将深入探讨Apache Spark窗口函数。 您可能也对我之前有关Apache Spark的帖子感兴趣。
- 使用Apache Spark开始您的旅程-第1部分
- 使用Apache Spark开始您的旅程-第2部分
- Apache Spark开始您的旅程-第3部分
- 深入研究Apache Spark DateTime函数
- 在Apache Spark中使用JSON
首先,让我们看看什么是窗口函数以及何时使用它们。 我们在Apache Spark中使用了各种功能,例如月份(从日期返回月份),四舍五入(舍入值)和地板(为给定的输入提供底值)等,这些功能将在每条记录上执行并返回一个值 每条记录。 然后,我们将对一组数据执行各种聚合函数,并为每个组返回一个值,例如sum,avg,min,max和count。 但是,如果我们想对一组数据执行该操作,并且希望对每个记录有一个单一的值/结果怎么办? 在这种情况下,我们可以使用窗口函数。 他们可以定义记录的排名,累积分布,移动平均值,或标识当前记录之前或之后的记录。
让我们使用一些Scala API示例来了解以下窗口函数:
- 汇总:min, max, avg, count, 和 sum.
- 排名:rank,dense_rank,percent_rank,row_num和ntile
- 分析性:cume_dist,lag和lead
- 自定义边界:rangeBetween和rowsBetween
为便于参考,GitHub上提供了一个以JSON文件格式导出的Zeppelin笔记本和一个Scala文件。
创建Spark DataFrame
现在,我们创建一个示例Spark DataFrame,我们将在整个博客中使用它。 首先,让我们加载所需的库。
- import org.apache.spark.sql.expressions.Window
- import org.apache.spark.sql.functions._
现在,我们将使用一些虚拟数据创建DataFrame,这些虚拟数据将用于讨论各种窗口函数。
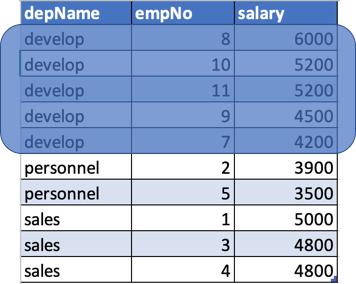
- case class Salary(depName: String, empNo: Long, salary: Long)
- val empsalary = Seq(
- Salary("sales", 1, 5000),
- Salary("personnel", 2, 3900),
- Salary("sales", 3, 4800),
- Salary("sales", 4, 4800),
- Salary("personnel", 5, 3500),
- Salary("develop", 7, 4200),
- Salary("develop", 8, 6000),
- Salary("develop", 9, 4500),
- Salary("develop", 10, 5200),
- Salary("develop", 11, 5200)).toDF()
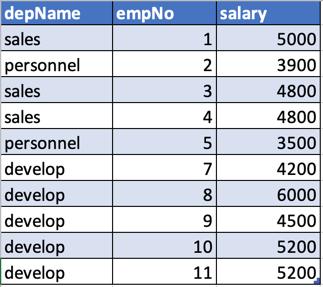
这是我们的DataFrame的样子:
窗口集合函数
让我们看一些聚合的窗口函数,看看它们如何工作。
首先,我们需要定义窗口的规范。 假设我们要根据部门获取汇总数据。 因此,在此示例中,我们将基于部门名称(列:depname)定义窗口。
为聚合函数创建窗口规范
- val byDepName = Window.partitionBy("depName")
在窗口上应用聚合函数
现在,在部门内(列:depname),我们可以应用各种聚合函数。 因此,让我们尝试查找每个部门的最高和最低工资。 在这里,我们仅选择了所需的列(depName,max_salary和min_salary),并删除了重复的记录。
- val agg_sal = empsalary
- .withColumn("max_salary", max("salary").over(byDepName))
- .withColumn("min_salary", min("salary").over(byDepName))
- agg_sal.select("depname", "max_salary", "min_salary")
- .dropDuplicates()
- .show()
输出:
- +---------+----------+----------+
- | depname|max_salary|min_salary|
- +---------+----------+----------+
- | develop| 6000| 4200|
- | sales| 5000| 4800|
- |personnel| 3900| 3500|
- +---------+----------+----------+
现在让我们看看它是如何工作的。 我们已经按部门名称对数据进行了分区:
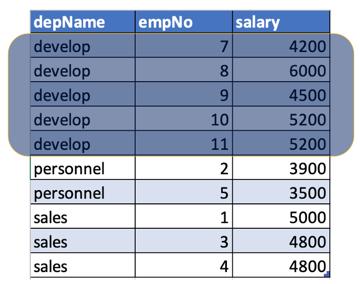
现在,当我们执行合计函数时,它将应用于每个分区并返回合计值(在本例中为min和max)。
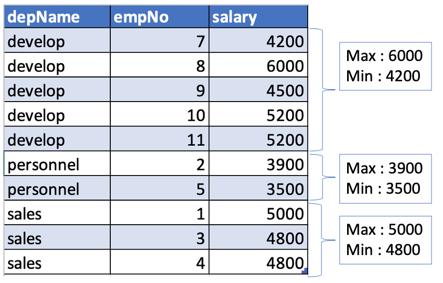
注意:可用的汇总函数为最大,最小,总和,平均和计数。
窗口排名功能
在本节中,我们将讨论几种类型的排名函数。
创建用于排序功能的窗口规范
现在,我们要根据员工在部门内的薪水进行排名。 薪水最高的员工将排名第一,薪水最低的员工将排名最后。 在这里,我们将基于部门(列:depname)对数据进行分区,并且在部门内,我们将根据薪水以降序对数据进行排序。
- val winSpec = Window.partitionBy("depName").orderBy("salary".desc)
对于每个部门,记录将根据薪水以降序排序。
1.等级功能:等级
此函数将返回分区中每个记录的等级,并跳过任何重复等级之后的后续等级:
- val rank_df = empsalary.withColumn("rank", rank().over(winSpec))
- rank_df.show()
输出:
- +---------+-----+------+----+
- | depName|empNo|salary|rank|
- +---------+-----+------+----+
- | develop| 8| 6000| 1|
- | develop| 11| 5200| 2|
- | develop| 10| 5200| 2|
- | develop| 9| 4500| 4|
- | develop| 7| 4200| 5|
- | sales| 1| 5000| 1|
- | sales| 4| 4800| 2|
- | sales| 3| 4800| 2|
- |personnel| 2| 3900| 1|
- |personnel| 5| 3500| 2|
- +---------+-----+------+----+
在这里我们可以看到某些等级重复,而有些等级丢失。 例如,在开发部门中,我们有2名等级= 2的员工,而没有等级= 3的员工,因为等级函数将为相同的值保留相同的等级,并相应地跳过下一个等级。
2.密集等级:densed_rank
此函数将返回分区中每个记录的等级,但不会跳过任何等级。
- val dense_rank_df = empsalary.withColumn("dense_rank", dense_rank().over(winSpec))
- dense_rank_df.show()
输出:
- +---------+-----+------+-----------+
- | depName|empNo|salary|desnse_rank|
- +---------+-----+------+-----------+
- | develop| 8| 6000| 1|
- | develop| 10| 5200| 2|
- | develop| 11| 5200| 2|
- | develop| 9| 4500| 3|
- | develop| 7| 4200| 4|
- | sales| 1| 5000| 1|
- | sales| 3| 4800| 2|
- | sales| 4| 4800| 2|
- |personnel| 2| 3900| 1|
- |personnel| 5| 3500| 2|
- +---------+-----+------+-----------+
在这里,我们可以看到某些等级是重复的,但是排名并没有像我们使用等级功能时那样丢失。 例如,在开发部门中,我们有2名员工,等级=2。density_rank函数将为相同的值保留相同的等级,但不会跳过下一个等级。
3.行号函数:row_number
此功能将在窗口内分配行号。 如果2行的排序列值相同,则不确定将哪个行号分配给具有相同值的每一行。
- val row_num_df = empsalary.withColumn("row_number", row_number().over(winSpec))
- row_num_df.show()
输出:
- +---------+-----+------+----------+
- | depName|empNo|salary|row_number|
- +---------+-----+------+----------+
- | develop| 8| 6000| 1|
- | develop| 10| 5200| 2|
- | develop| 11| 5200| 3|
- | develop| 9| 4500| 4|
- | develop| 7| 4200| 5|
- | sales| 1| 5000| 1|
- | sales| 3| 4800| 2|
- | sales| 4| 4800| 3|
- |personnel| 2| 3900| 1|
- |personnel| 5| 3500| 2|
- +---------+-----+------+----------+
4.百分比排名函数:percent_rank
此函数将返回分区中的相对(百分数)等级。
- val percent_rank_df = empsalary.withColumn("percent_rank", percent_rank().over(winSpec))
- percent_rank_df.show()
输出:
- +---------+-----+------+------------+
- | depName|empNo|salary|percent_rank|
- +---------+-----+------+------------+
- | develop| 8| 6000| 0.0|
- | develop| 10| 5200| 0.25|
- | develop| 11| 5200| 0.25|
- | develop| 9| 4500| 0.75|
- | develop| 7| 4200| 1.0|
- | sales| 1| 5000| 0.0|
- | sales| 3| 4800| 0.5|
- | sales| 4| 4800| 0.5|
- |personnel| 2| 3900| 0.0|
- |personnel| 5| 3500| 1.0|
- +---------+-----+------+------------+
5. N-tile功能:ntile
此功能可以根据窗口规格或分区将窗口进一步细分为n个组。 例如,如果需要将部门进一步划分为三类,则可以将ntile指定为3。
- val ntile_df = empsalary.withColumn("ntile", ntile(3).over(winSpec))
- ntile_df.show()
输出:
- +---------+-----+------+-----+
- | depName|empNo|salary|ntile|
- +---------+-----+------+-----+
- | develop| 8| 6000| 1|
- | develop| 10| 5200| 1|
- | develop| 11| 5200| 2|
- | develop| 9| 4500| 2|
- | develop| 7| 4200| 3|
- | sales| 1| 5000| 1|
- | sales| 3| 4800| 2|
- | sales| 4| 4800| 3|
- |personnel| 2| 3900| 1|
- |personnel| 5| 3500| 2|
- +---------+-----+------+-----+
窗口分析功能
接下来,我们将讨论诸如累积分布,滞后和超前的分析功能。
1.累积分布函数:cume_dist
此函数提供窗口/分区的值的累积分布。
- val winSpec = Window.partitionBy("depName").orderBy("salary")
- val cume_dist_df =
- empsalary.withColumn("cume_dist",cume_dist().over(winSpec))
- cume_dist_df.show()
定义窗口规范并应用cume_dist函数以获取累积分布。
输出:
- +---------+-----+------+------------------+
- | depName|empNo|salary| cume_dist|
- +---------+-----+------+------------------+
- | develop| 7| 4200| 0.2|
- | develop| 9| 4500| 0.4|
- | develop| 10| 5200| 0.8|
- | develop| 11| 5200| 0.8|
- | develop| 8| 6000| 1.0|
- | sales| 4| 4800|0.6666666666666666|
- | sales| 3| 4800|0.6666666666666666|
- | sales| 1| 5000| 1.0|
- |personnel| 5| 3500| 0.5
- |personnel| 2| 3900| 1.0|
- +---------+-----+------+------------------+
2.滞后功能:滞后
此函数将在从DataFrame偏移行之前返回该值。
lag函数采用3个参数(lag(col,count = 1,默认= None)),col:定义需要在其上应用函数的列。 count:需要回顾多少行。 default:定义默认值。
- val winSpec = Window.partitionBy("depName").orderBy("salary")
- val lag_df =
- empsalary.withColumn("lag", lag("salary", 2).over(winSpec))
- lag_df.show()
输出:
- +---------+-----+------+----+
- | depName|empNo|salary| lag|
- +---------+-----+------+----+
- | develop| 7| 4200|null|
- | develop| 9| 4500|null|
- | develop| 10| 5200|4200|
- | develop| 11| 5200|4500|
- | develop| 8| 6000|5200|
- | sales| 4| 4800|null|
- | sales| 3| 4800|null|
- | sales| 1| 5000|4800|
- |personnel| 5| 3500|null|
- |personnel| 2| 3900|null|
- +---------+-----+------+----+
例如,让我们在当前行之前查找薪水2行。
- 对于depname = develop,salary = 4500。没有这样的行,该行在该行之前2行。 因此它将为空。
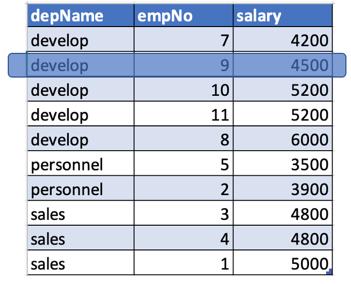
- 对于部门名称=发展,薪水= 6000(以蓝色突出显示)。 如果我们提前两排,我们将获得5200的薪水(以绿色突出显示)。
3.导联功能:导联
此函数将返回DataFrame的偏移行之后的值。
- val winSpec = Window.partitionBy("depName").orderBy("salary")
- val lead_df =
- empsalary.withColumn("lead", lead("salary", 2).over(winSpec))
- lead_df.show()
lead函数采用3个参数(lead(col,count = 1,默认= None))col:定义需要在其上应用函数的列。 count:对于当前行,我们需要向前/向后查找多少行。 default:定义默认值。
输出:
- +---------+-----+------+----+
- | depName|empNo|salary| lag|
- +---------+-----+------+----+
- | develop| 7| 4200|5200|
- | develop| 9| 4500|5200|
- | develop| 10| 5200|6000|
- | develop| 11| 5200|null|
- | develop| 8| 6000|null|
- | sales| 3| 4800|5000|
- | sales| 4| 4800|null|
- | sales| 1| 5000|null|
- |personnel| 5| 3500|null|
- |personnel| 2| 3900|null|
- +---------+-----+------+----+
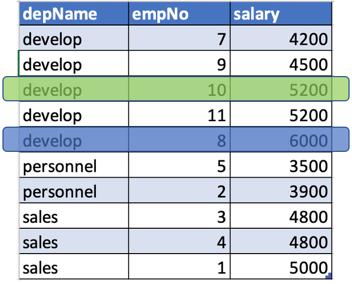
让我们尝试从当前行中查找前进/后两行的薪水。
- 对于depname =开发人员,薪水= 4500(以蓝色突出显示)。 如果我们在前进/后退两行,我们将获得5200的薪水(以绿色突出显示)。
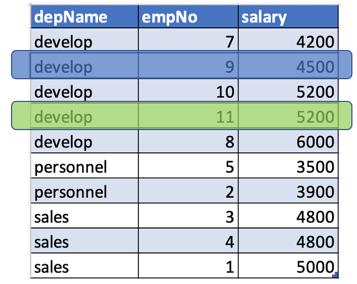
- 对于depname =人员,薪水=3500。在此分区中,没有此行向前2行/在该行之后。 因此我们将获得空值。
自定义窗口定义
默认情况下,窗口的边界由分区列定义,我们可以通过窗口规范指定顺序。 例如,对于开发部门,窗口的开始是工资的最小值,窗口的结束是工资的最大值。
但是,如果我们想更改窗口的边界怎么办? 以下功能可用于定义每个分区内的窗口。
1. rangeBetween
使用rangeBetween函数,我们可以显式定义边界。例如,从当前薪水开始,将其定义为100,然后将其定义为300,并查看其含义。 从100开始表示窗口将从100个单位开始,从当前值开始以300个值结束(包括开始值和结束值)。
- val winSpec = Window.partitionBy("depName")
- .orderBy("salary")
- .rangeBetween(100L, 300L)
定义窗口规格
起始值和结束值后的L表示该值是Scala Long类型。
- val range_between_df = empsalary.withColumn("max_salary", max("salary").over(winSpec))
- range_between_df.show()
应用自定义窗口规范
输出:
- +---------+-----+------+----------+
- | depName|empNo|salary|max_salary|
- +---------+-----+------+----------+
- | develop| 7| 4200| 4500|
- | develop| 9| 4500| null|
- | develop| 10| 5200| null|
- | develop| 11| 5200| null|
- | develop| 8| 6000| null|
- | sales| 3| 4800| 5000|
- | sales| 4| 4800| 5000|
- | sales| 1| 5000| null|
- |personnel| 5| 3500| null|
- |personnel| 2| 3900| null|
- +---------+-----+------+----------+
现在,让我们尝试了解输出。
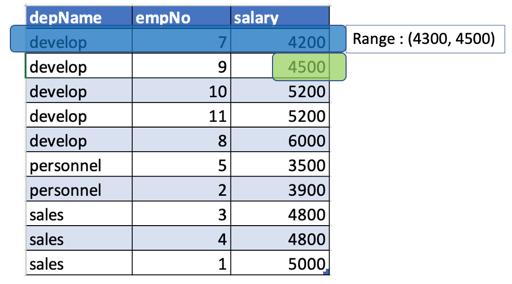
- 对于depname = developer,salary = 4200,窗口的开始将是(当前值+开始),即4200 + 100 =4300。窗口的结束将是(当前值+结束),即4200 + 300 = 4500。
由于只有一个薪水值在4300到4500之间,包括开发部门的4500,所以我们将4500作为max_salary作为4200(上面的检查输出)。
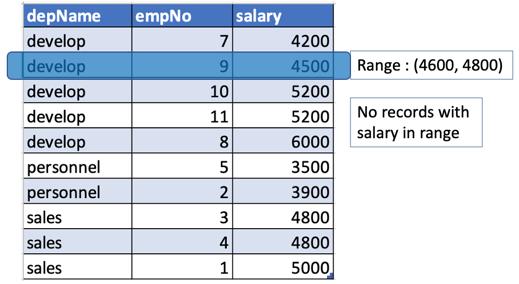
- 同样,对于depname = develop,salary = 4500,窗口将为(开始:4500 + 100 = 4600,结束:4500 + 300 = 4800)。 但是开发部门没有薪水值在4600到4800之间,因此最大值不会为空(上面的检查输出)。
这里有一些特殊的边界值可以使用。
- Window.currentRow:指定一行中的当前值。
- Window.unboundedPreceding:这可以用于使窗口无限制地开始。
- Window.unbounded以下:此方法可用于使窗口具有无限的末端。
例如,我们需要从员工工资中找到最高工资,该最高工资大于300。 因此,我们将起始值定义为300L,将结束值定义为Window.unboundedFollowing:
- val winSpec = Window.partitionBy("depName").orderBy("salary")
- .rangeBetween(300L, Window.unboundedFollowing)
- val range_unbounded_df = empsalary.withColumn("max_salary", max("salary").over(winSpec))
- range_unbounded_df.show()
输出:
- +---------+-----+------+----------+
- | depName|empNo|salary|max_salary|
- +---------+-----+------+----------+
- | develop| 7| 4200| 6000|
- | develop| 9| 4500| 6000|
- | develop| 10| 5200| 6000|
- | develop| 11| 5200| 6000|
- | develop| 8| 6000| null|
- | sales| 3| 4800| null|
- | sales| 4| 4800| null|
- | sales| 1| 5000| null|
- |personnel| 5| 3500| 3900|
- |personnel| 2| 3900| null|
- +---------+-----+------+----------+
因此,对于depname =人员,薪水=3500。窗口将是(开始:3500 + 300 = 3800,结束:无边界)。 因此,此范围内的最大值为3900(检查上面的输出)。
同样,对于depname = sales,salary = 4800,窗口将为(开始:4800 + 300、5100,结束:无边界)。 由于销售部门的值不大于5100,因此结果为空。
2.rowsBetween
通过rangeBetween,我们使用排序列的值定义了窗口的开始和结束。 但是,我们也可以使用相对行位置定义窗口的开始和结束。
例如,我们要创建一个窗口,其中窗口的开始是当前行之前的一行,结束是当前行之后的一行。
定义自定义窗口规范
- val winSpec = Window.partitionBy("depName")
- .orderBy("salary").rowsBetween(-1, 1)
应用自定义窗口规范
- val rows_between_df = empsalary.withColumn("max_salary", max("salary").over(winSpec))
- rows_between_df.show()
输出:
- +---------+-----+------+----------+
- | depName|empNo|salary|max_salary|
- +---------+-----+------+----------+
- | develop| 7| 4200| 4500|
- | develop| 9| 4500| 5200|
- | develop| 10| 5200| 5200|
- | develop| 11| 5200| 6000|
- | develop| 8| 6000| 6000|
- | sales| 3| 4800| 4800|
- | sales| 4| 4800| 5000|
- | sales| 1| 5000| 5000|
- |personnel| 5| 3500| 3900|
- |personnel| 2| 3900| 3900|
- +---------+-----+------+----------+
现在,让我们尝试了解输出。
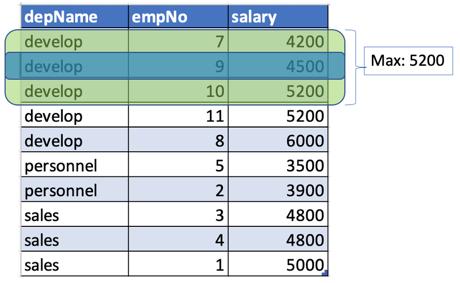
- 对于depname =开发,salary = 4500,将定义一个窗口,该窗口在当前行之前和之后一行(以绿色突出显示)。 因此窗口内的薪水为(4200、4500、5200),最高为5200(上面的检查输出)。
- 同样,对于depname = sales,salary = 5000,将在当前行的前后定义一个窗口。 由于此行之后没有行,因此该窗口将只有2行(以绿色突出显示),其薪水分别为(4800,5000)和max为5000(上面的检查输出)。
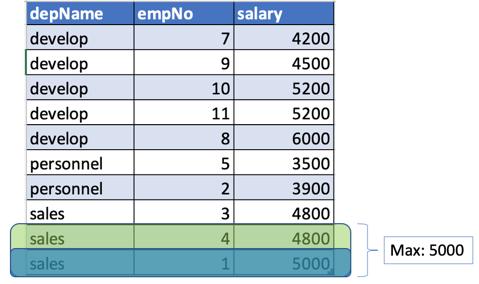
我们还可以像以前使用rangeBetween一样使用特殊边界Window.unboundedPreceding,Window.unboundedFollowing和Window.currentRow。
注意:rowsBetween不需要排序,但是我使用它来使每次运行的结果保持一致。