













1 哈希表
哈希表属于编程中比较常见的数据结构之一,基本上所有的语言都会实现数组和哈希表这两种结构,Hash table 的历史是比较悠远的,我们在编程时也是离不开的,这种数据结构的作用其实很简单,就是我们可以根据一个 key 可以查找到对应的 value,也就是说这种数据结构存储的是键值对的“列表”。
1.1 原理
首先哈希表中第一个点就是哈希函数,也就是我们需要一个函数,根据我们的 key 计算出一个值,然后根据这个值可以直接找到对应的 value。因为我们的哈希表的一个作用就是 O(1) 复杂度找到 key 对应的 value。
完美的哈希函数是可以做到将任何一个 key 值都可以计算出一个唯一且固定大小的值,不幸的是目前世界上还没有这种完美的哈希函数。因此我们需要解决的另外一个问题就是哈希冲突的解决。
1.1.1 哈希冲突
假如我们有两个不同的 key,通过哈希函数计算出的结果相同,那么我们是不能认为这两个 key 在 map 中是相同的,也就是如果出现了这种情况,我们的 map 结构是可以解决这个问题的。目前解决办法有很多,这里只说三个比较常见的解决方案:
开放地址法(Open Addressing):
- 写入时:假如 key Alice 与 Bob 通过哈希函数计算出结果冲突。当 map 中已经存在 key Alice,再写入 key 为 Bob时,发现哈希结果对应位置已经存在 Alice,此时在 Alice 位置之后再寻找位置,一直找到为空的位置,将 Bob 写入。
- 读取时:此时 map 中已存在 key Alice、Bob,且哈希结果相同,此时想查找 Bob 对应 value 时,先计算 Bob 哈希结果,再通过哈希结果在 map 中查找位置,此时由于和 Alice 哈希结果相同,并且 Alice 先于 Bob 存入 map,所以会直接找到 Alice 的位置,发现 key 是 Alice 不是 Bob,接着在 Alice 位置后面查找,直到找到 key Bob 或者找到空。
再哈希法(Re-Hashing):
- 设计多个哈希函数,假如 Alice 与 Bob 计算哈希结果相同,那么用另外一个哈希函数来计算 Bob 的哈希值,这种方式来解决哈希冲突。
- 链地址法(Separate Chaining):
- 此方法将同一个哈希结果对应的位置想象成一个桶,如果多个 key 对应哈希结果相同,那么都放到同一个桶中,并且桶中元素使用链表结构存储。
- 写入时:Alice 于 Bob 哈希结果相同,此时 map 已经有 Alice,再写入 Bob 时,发现对应哈希结果位置已经存在了 Alice,此时在当前桶中的 Alice 后链接一个 Bob,此时哈希结果对应的桶就存在了两个元素 Alice 与 Bob。
- 读取时:读取 Bob key 时,发现对应哈希结果的桶中第一个元素是 Alice,此时在桶中按链表顺序挨个查找,直到 key 相同或者空。
- 装载因子:此方案存在一个问题,当一个桶中元素过多时,其复杂度将增加,极端情况下就变成了链表。所以我们会限制在一个桶中元素的个数。这样在一个桶中元素过多时,需要生成新的桶。
- 装载因子 = 元素总量 / 桶总个数
在 Go 语言中,map 使用的是链地址法。
2 Go 中 map分析
2.1 map 数据结构
map 的源码位于 src/runtime/map.go 文件中,结构如下:
- type hmap struct {
- count int // 当前 map 中元素数量
- flags uint8
- B uint8 // 当前 buckets 数量,2^B 等于 buckets 个数
- noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
- hash0 uint32 // 哈希种子
- buckets unsafe.Pointer // buckets 数组指针
- oldbuckets unsafe.Pointer // 扩容时保存之前 buckets 数据。
- nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
- extra *mapextra // optional fields
- }
- // 每一个 bucket 的结构,即 hmap 中 buckets 指向的数据。
- type bmap struct {
- tophash [bucketCnt]uint8
- }
- // 编译期间重构此结构
- type bmap struct {
- topbits [8]uint8
- keys [8]keytype
- values [8]valuetype
- pad uintptr
- overflow uintptr
- }
关于 hmap 的结构这里已经将很多重要的字段列出来了,其中最重要的就是 buckets 这一部分,根据上面我们说过的链地址法可知,对同一类 key (哈希结果相同)放入相同的桶中。此时每一个桶还有另外一个字段 overflow,也就是当前桶装不下就会再创建新的桶。这就是 Go 中 map 的主要实现方法,更详细的部分我们接下来一点一点聊。
2.2 源码
map 的源码位于 src/runtime/map.go 文件中。关于 map 的操作的具体实现在这里都可以找到:
- 创建 map:func makemap(t *maptype, hint int, h *hmap) *hmap
- 访问某个 key:
- 返回结果只包括 value:func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
- 返回结果包括 bool 结果:func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
- 存入 key:func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
- 删除 key:func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)
本篇文章不会带大家将源码通读一遍,但是会将其实现过程以图或者文字形式分析出来,但是建议大家有时间可以根据本篇文章的内容再去自己读一遍源码,如果我这里将所有源码都解释一遍,估计朋友们很快就又忘记了,还不如记住实现流程。所以本文更多的是讲 map 每个操作的过程图,以及其中的部分要点,而不是将源码一行一行的解释出来。
3. 图解 map
3.1 创建map
我们已经知道 map 的数据结构,其实 map 的初始化也无非就是填充各个字段而已:
- 第一个就是 hash0 字段,此处会随机给一个种子,用在哈希函数计算时使用。关于哈希函数在运行时,Go 会检测 cpu 是否支持 aes,支持则使用 aes hash,否则使用 memhash。位于路径:src/runtime/alg.go 下的 alginit() 函数。
- 根据参数 hint计算需要的桶数。
- 根据桶的数量创建一个连续的空间来存储桶的数据。
大体上就是这么一个过程,关于源码中的一些检查项这里就不多废话了,并且源码注释也写的很清楚了。
下面这个图就是一个 map 的主要相关存储结构:
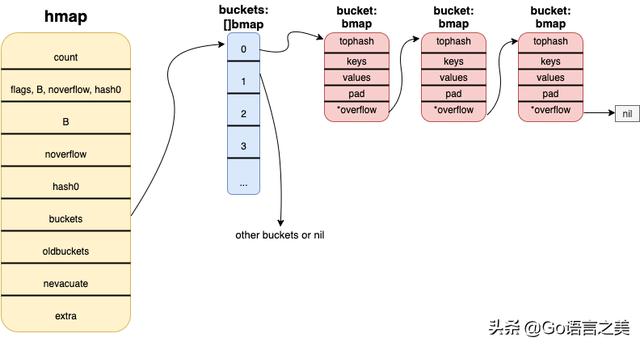
map 主要结构
3.2 定位 key
一个 map 初始化后基本的结构我们已经知道了,接下来就是我们在这个结构中如何添加一个 key 对应的 value。
我们再看一遍每一个桶的结构:
- type bmap struct {
- topbits [8]uint8
- keys [8]keytype
- values [8]valuetype
- pad uintptr
- overflow uintptr
- }
这里的 keys 与 values 字段就是存储 key 和 value 的真正内存的地方,我们可以看到这里每个都是长度为8的数组,也就是说一个桶内存了两个数组,一个存的是 key 列表,另一个是 value 列表,并且每个数据的大小都是8。那么当有第9个元素入桶时,我们就需要创建新的桶了,也就是 overflow 字段指向一个新的 bucket(bmap 结构)。
还有一个字段就是 topbits,也是一个长度为8的数组,其实看到这里我们应该想到,这三个数组长度都相同应该有对应关系了,也就是说 topbits 数组中第一个元素是一个8位大小,我们称之为 高8位,这是我们再回想一下哈希函数,我们的哈希函数的结果取高8位,然后存入 topbits 数组,然后其在数组的索引我们称之为i,那么我们就可以在 keys 和 values 数组的第i个位置存储数据了。
上面是在已知一个桶中添加或者修改元素,那么我们该如何查找这个桶呢?
我们知道在 hmap 中有 buckets 字段,其指向 []bmap 数组。那么我们就需要通过 key 找到对应的 bmap 在 []bmap 中的位置。关于此处的计算大家感兴趣的可以看一下源码,这里就不详细说每一个运算符都是怎么运算的,只说一下大致的流程:hmap 中有一个 B 字段,根据字段 B 的值,以及 key 的 hash 值,计算出目标桶在 []bmap 中的位置(其实就是取了 key 的哈希的后几位作为数组的下标即可)。
现在我们根据一个 key 可以在 hmap 中的 buckets 字段找到对应的 bmap 对象,同时在 bmap 中根据 key 哈希的高八位找到其在 keys 与 values 数组中的位置。这里我们还没有说如果有 overflow 的情况。其实不说想必大家也能猜到了,在我们定位到一个 bmap 时,是不知道其一共有多少个溢出桶的:假设我们有桶 A,A 的 overflow 字段指向桶 B,B 的 overflow 指向桶 C,假设我们此时根据 key 的哈希找到了桶 A,然后 for 循环遍历桶中的 topbits 数组,如果某个高8位的哈希与我们想找的 key 的哈希的高8位相同,就去对应位置的 keys 数组查找对应的 key1,假如 key1 与我们的目标 key 相等,那么直接返回其对应 values 数组中的 value 即可。如果key1 与我们的目标 key 不相等,接着变量桶中其他元素。假设桶中所有元素遍历后没有找到相同的 key,那么此时就要到 A 桶的溢出桶 B 再去遍历,如果 B 中依然找不到再去桶 C 中查找。此时大家可以思考一下如果是你,你会如何实现这部分代码呢?你实现的和 Go 的源码是否一样呢?
当我们知道了上面定位 key 的过程,对于 key 的增删改查过程也就不多说了,因为核心的我们已经掌握了,现在大家可以去看一下源码了,这时大家看源码必定事半功倍。
























