【51CTO.com原创稿件】
1.长尾效应?跟动物尾巴有关系?
上一篇讲完推荐系统的分类和功能后,在这我有必要对其中的一个名词“长尾效应”进行完整的解释。长尾效应在百度百科上解释为“从人们需求的角度来看,大多数的需求会集中在头部,而这部分我们可以称之为流行,而分布在尾部的需求是个性化的,零散的小量的需求。”但不要小瞧尾部的需求,因为流行的头部种类毕竟有限,而尾部的种类繁多,即使需求量小,但是汇集在一起,整体需求不一定低于流行头部的需求。这就好比千千万万的小溪流汇集在一起可能会胜过湖泊甚至大海。长尾效应在数学模型曲线上表示为一条正太曲线,如下图所示:(在这我举例表示:头部为大厂手机品牌公司,尾部为小厂品牌手机公司)
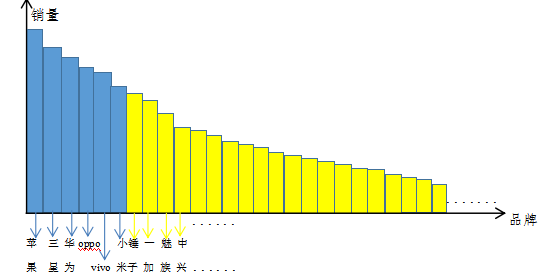
如上图所示,虽然大厂品牌(苹果、三星、华为等)的手机销售额各自都在前几名,但是总的销售额,也就是蓝色图形面积比黄色图形面积要小得多,而黄色图形则表示的都是小品牌商(锤子、一加、魅族、中兴等)的手机销售额总和,它们加在一起的销售额是非常可观的,也验证了一句话“人多力量大”的道理。因此,在设计推荐系统的时候,一边要保证大厂品牌的销售额,但是千万不能忽略小厂品牌。推荐的商品可以跟大厂品牌相关度更高,也要不断挖掘客户的潜在兴趣,推荐一些小厂品牌的手机种类,只有这样才能缓解甚至解决“长尾效应”。只有这样,才能使设计出的推荐系统更加智能化、人性化,增强用户的满意度和粘性。
2.推荐系统及算法发展历程和研究现状?
解释了“长尾效应”,接下来就要开始进入推荐系统真正的核心内容——推荐算法。首先看下推荐系统的发展历程和如今的研究现状:
在1995年3月,美国人工智能协会上提出了个性化导航系统,斯坦福大学的研究者们也在同一会议上推出了个性化推荐系统LIRA;之后的多年时间里,众多公司和大学研究所纷纷投入研究推荐系统,先后推出了个性化入口、基于协同过滤的个性化推荐系统以及个性化推荐电子商务平台;而我国开始研究推荐是在2009年之后,国内首个推荐系统科研团队成立百分点信息科技有限公司;随后在百度世界大会2011上,百度将推荐引擎与云计算、搜索引擎并列为互联网重要战略规划和方向。随着推荐引擎的出现,用户获取信息的方式也从简单的目标明确性数据搜索转换到了更加符合人们搜索习惯的信息查询。如今大部门电子商务或者社交网站的推荐引擎用到的工作原理是基于物品或者用户的相似集合进行推荐。而主流的推荐算法模型仍旧是基于协同过滤来完成推荐。因此,我将先从协同过滤算法来分析来一步步引出其他的推荐算法,从而来让读者有个循序渐进的理解过程,并能够基本把握每一种推荐算法的优缺点,真正做到区别分析每一个算法和使用环境。
3.推荐算法中的“老顽童”——协同过滤算法
协同过滤算法为什么称之为老顽童呢?想必大家应该知道“老顽童”的特性,首先他要年龄大,这也对应到协同过滤算法是最早用于推荐系统的算法,完全算得上是一个算法中的“老前辈”;其次“老顽童”得保持年轻的心态,紧跟时代潮流,并且跟年轻人玩到一块去,这也对应上协同过滤算法仍然是目前最为流行、使用最为广泛的推荐算法。可以这么说,目前市面上超过半成的推荐系统仍旧依靠的是协同过滤算法,并且整体推荐效果不亚于新研究出来的其他推荐算法,并且协同过推荐算法的性能最为稳定,只要提到推荐系统,第一个出现在我们脑海里的算法就是协同过滤。所以,不得不说协同过滤算法是经典的、不过时的,是推荐算法中的十足“老顽童”。下面就让我们来认识下这位“老顽童”。
协同过滤(CF,Collaborative Filtering)的主要思想就是利用与当前用户具有相同兴趣或者历史行为的其他用户群,通过分析这些用户群目前的喜好或者行为信息来预测当前用户可能喜欢的东西或者可能产生的行为,说白了就是一句短语:“物以类聚,人以群分”。举个例子,A用户喜欢看喜剧类的电影如喜剧之王、西红柿首富、疯狂的石头等,并且在近期都看过,而B用户和C用户也喜欢看喜剧类电影且近期也看过上面三部影片,这时候B和C可以划分为与A具有相似兴趣的用户群,通过B和C接下来看的影片或者已经看过而A没看过的影片就可以作为A用户的推荐预测影片。这种推荐算法很直接也很简单,在实际运用中往往能取得不错的推荐效果。这类推荐算法主要运用场景是在线零售系统,我之前工作的互联网零售公司就是运用这个算法,它的目的是进行商品促销和提高物品销售额。
这类算法输入的是一个用户—物品评分矩阵,而输出的数据可分为两类:一类是当前用户对物品喜欢成都的预测数值,一类是前N项的推荐物品列表,当然,这个列表不能包含当前用户已经购买过的物品。而协同过滤算法最主要也是最基础的实现方式有两种:基于用户的最近邻推荐和基于物品的最近邻推荐。原理就是根据用户对物品或者信息的偏好,发现物品本身的相关性或者发现用户之间的相关性,再基于相关性按程度得分进行排序推荐。
4.CF-基于用户的最近邻推荐
4.1 基于用户最近邻推荐的主要思想
基于用户的最近邻推荐(user-based nearest neighbor recommendation)主要思想是:
(1)将输入的评分数据集和当前用户ID作为输入,使用皮尔逊相关系数来表示两个用户之间的相关性,找出与当前用户过去行为历史具有相似行为或者偏好的K个其他用户,这些用户也叫对等用户或者叫最近邻;
(2)计算出当前用户和其他用户的相关性后,对当前用户未购买或者未见过的每个物品,利用用户的K个近邻对物品的评分进行预测,形成物品评分排序表;
(3)选择所需数量且物品评分最高的几个物品推荐给当前用户。
当然基于用户的最近邻推荐算法也有自己使用的前提,那就是如果用户过去有相似的偏好,那么该用户在未来还得会有相似的偏好,也就是用户的偏好不会随着时间变化。在这样的前提下,使用基于用户的最近邻推荐最为合理,推荐效果也会较为满意。
4.2 皮尔逊相关系数
在获取当前用户最近邻的时候不得不涉及到前面提到的皮尔逊相关系数,这个系数是用来求解用户之间相关性的公式,如下所示:
皮尔逊系数(Pearson Correlation Coefficient)表示两个用户之间相关性时,取值范围为[-1,+1],其中-1强负相关,+1表示强正相关,0表示不相关。公式为:

使用皮尔逊相关系数要求两个变量之间的标准差都不能为0,只有这样,该相关系数才有定义。该系数通常使用在以下的变量环境:
(1)两个变量之间是线性关系,并且都是连续的;
(2)两个变量的总体是正太分布的或者是单峰分布;
(3)两个变量的观察值是成对的且每对观测值是相互对立的。
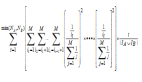
当计算出用户的相关性后,就可以选择出最相似的N个近邻用户计算对物品的评分预测值,也就是说N个近邻用户对物品均有评分值,评分预测公式如下:
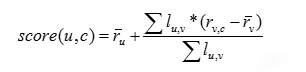
4.3基于用户最近邻推荐案例
最终得到用户对于物品的预测评分为 ,对于该部分公式,通过举例来帮助广大读者便于理解:
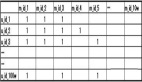
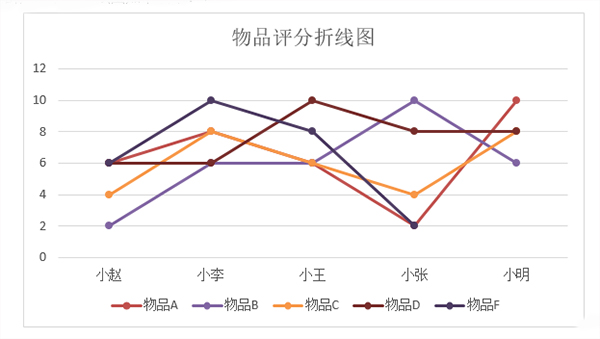
例如用户—评分矩阵如下表所示,我们来基于这个评分矩阵计算出小明对于物品F的评分:
|
物品 用户 |
A |
B |
C |
D |
F |
|
小赵 |
6 |
2 |
4 |
6 |
6 |
|
小李 |
8 |
6 |
8 |
6 |
10 |
|
小王 |
6 |
6 |
6 |
10 |
8 |
|
小张 |
2 |
10 |
4 |
8 |
2 |
|
小明 |
10 |
6 |
8 |
8 |
????? |
(1)首先通过皮尔逊相关系数计算出小明与其他四位用户的相似度数值,由于计算过程是一样的,在这我仅计算小明与小赵之间的相似度,读者感兴趣可自行模仿过程计算小明和其他用户的相似度。
(2)小明的评分均值为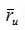 =(10+6+8+8)/4 =8,小赵的评分均值
=(10+6+8+8)/4 =8,小赵的评分均值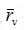 =(6+2+4+6+6)/5 =4.8,可得:
=(6+2+4+6+6)/5 =4.8,可得:
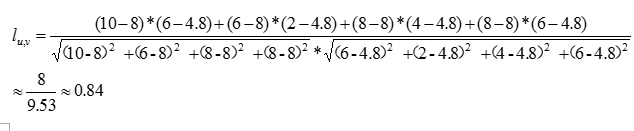
同理可得小明和小李、小王、小张之间的相似度分别为0.71,0.00,-0.89。假设选定N的参数为2,则由相似度数值可知与小明相似度最高的两位分别是小赵和小李,同样可以从折线图中比较直观地观察出相似度情况,折线图如下所示:
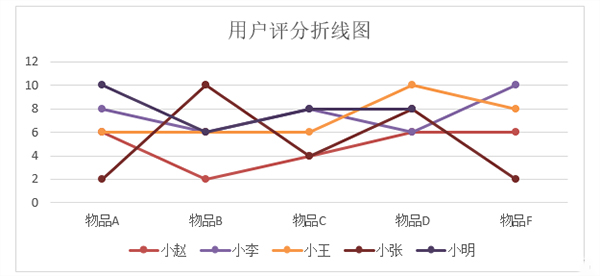
因此选取小赵和小李对物品F的评分来预测小明对于物品F的评分值,可得:
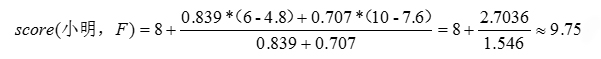
所以预测小明对于物品F的评分为9.75。
5.CF—基于物品最近邻推荐
5.1 基于物品最近邻推荐思想
基于物品的最近邻推荐(item-based nearest neighbor recommendation)的思想是基于物品之间的相似度,而不是基于用户之间的相似度来进行评分值预测。
5.2 余弦相似度
在基于物品的最近邻推荐算法中通常采用余弦相似度来计算两个物品之间的相似度,相似度取值范围为[0,1],值越接近1,相似度也就越高。当然也可以采用皮尔逊相关系数来计算物品之间的相似度,这就需要将上面用到的皮尔逊相关系数公式里的用户评分均值改为物品评分均值了,计算过程仍是一样的,在这就不赘述了。为考虑用户评分平均值之间的差异性,一般都使用改进余弦相似度公式来计算相似度,通过改进余弦相似度来在评分值中减去平均值,这样使得最终的取值范围跟皮尔逊相关系数的取值范围一致,也为[-1,+1]。改进余弦相似度公式如下:
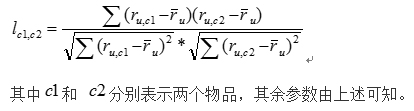
同样地,在计算出物品之间相似度后,选择出最为相似的前N个物品,用下面公式来预测用户对物品的评分为:
5.3 基于物品最近邻推荐案例
同样用之前的案例评分矩阵进行计算,为了计算方便,将上述的用户—物品评分矩阵调整成均各自减去均值的评分矩阵,这样就省略一些不必要的计算,便于下面公式的计算,采用均值调整后的用户—评分矩阵如下表所示:
|
物品 用户 |
A |
B |
C |
D |
F |
均值 |
|
小赵 |
1.2 |
-2.8 |
-0.8 |
1.2 |
1.2 |
4.8 |
|
小李 |
0.4 |
-1.6 |
0.4 |
-1.6 |
2.4 |
7.6 |
|
小王 |
-1.2 |
-1.2 |
-1.2 |
2.8 |
0.8 |
7.2 |
|
小张 |
-3.2 |
4.8 |
-1.2 |
2.8 |
-3.2 |
5.2 |
|
小明 |
2 |
-2 |
0 |
0 |
????? |
8 |
由改进余弦相似度公式可计算物品A和物品F之间的相似度为:
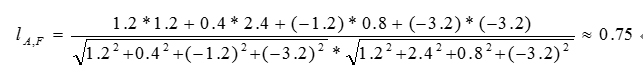
同理可计算出物品F与物品B、物品C、物品D之间的相似度分别为:-0.94,0.35,-0.48。
同样地假设选定参数N为2,则由物品F与各物品之间的相似度数值可知:与物品F相似度最高的两位分别是物品A和物品C,同样可以从折线图中比较直观地观察这几个物品的
相似度情况,折线图如下所示:
因此选取物品A和物品C评分来预测小明对物品F的评分值,可得:
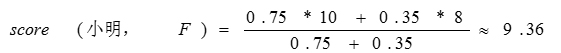
所以可预测出小明对于物品F的评分为9.36。
5.4 一个小问题?
由上可知,由物品评分矩阵可计算各个物品之间的相似度,从而可得到各个物品之间的相似度矩阵。这是离线计算出每一个物品之间的相似度,但是实际运用中涉及到的物品是数以亿计的,而得到的评分矩阵或者相似度矩阵则是亿级*亿级的矩阵。如果采用离线计算,则需要几百G的内存去存储离线计算的结果。并且如果是实时计算的话,计算过程基本已经满足不了实时的要求了。因此必须考虑这个问题,所以在实际运用中通常是提前计算出各个评分矩阵的相似度,将各个物品和相似度数值以的格式存储到redis中去,然后实时调用即可。当然如果存放到关系型数据库也是可以的,这样简便的就可以用SQL语句来查询修改数据了。至于采取什么方式存储,就需要根据实际运用场景来考量了。
基于物品的最近邻推荐是可以采用离线数据预计算的,原理就是先构建一个物品相似矩阵用来描述两个物品之间的相似度。等到线上运行时,通过确定与物品最相似的其他物品来计算用户对这些近邻物品评分的加权总和从而得到用户对当前物品的预测评分;近邻物品的数量可以先剔除无用户评分的物品,所以受限于用户有评分的物品个数,使得计算预测值的过程在线上交互过程可以短时间完成。当然,这种离线数据预处理的方式也适用于基于用户的最近邻推荐,但是在实际情况中,两个用户重叠评分的情况很少,以至于其他的【评分值就会影响到最终用户间的相似度计算。也就是说,基于物品之间相似度比基于用户之间的相似度更加稳定,这种方式就不会改变物品之间的相似度。
6.近邻推荐方法的优势
协同过滤算法是基于用户还是基于物品,都是采用近邻方法完成推荐,这种基于近邻方法推荐的优势有以下几个:
(1)简单性:算法实现过程简单,并且在计算过程中只有一个近邻数参数进行调整,容易进行修改调整;
(2)稳定性:当构建完相似度矩阵之后,如果有一个新用户或者新物品具有评分的话,只需要计算这个新用户或者新物品与其他用户或者物品之间的相似度就可以完成相似度矩阵的更新操作,不至于影响到其他用户或者物品之间的相似度数值;
合理性:这种预测方法解释性较强,对于预测推荐提供了简洁直观的理由;
(3)高效性:基于近邻方法的推荐效果相对较高,因为可以进行离线数据预处理,提前构建出相似度矩阵,从而在实际运用过程中提供近似于实时的推荐结果,具有良好的实时性能。
当然,除了近邻推荐方法的优势以外,肯定有它的局限性或者说是劣势,在某些情况下产生的推荐效果非常差或者说无法完成推荐。这些局限性和劣势我放在后续文稿中说明来引出其他推荐算法,因为这样才能比较清晰明了的掌握每个推荐算法的由来以及它的用处,因为任何一个推荐算法研究出来肯定是需要处理一个问题或者填补上其他一些算法的漏洞,来让自己的优势更加突出。所以在这里就不赘述基于近邻推荐方法的劣势了。
7.谈谈评分矩阵和评分?
说完基于协同过滤算法或者说基于近邻推荐算法,不知道读者有没有发现上述过程中有一个最基本的计算前提,那就是用户评分矩阵和物品评分矩阵。那么评分从哪里来,有了众多评分,构建评分矩阵就不是问题了。所以在这我需要额外说明下评分的由来,答复一些读者的疑虑。
在协同过滤(CF)算法中,输入的是用户—物品评分矩阵,所以构建用户—物品评分矩阵是协同过滤算法的一个重点。评分一般在计算中采用两分制、五分制、七分制和十分制四种。收集用户对物品评分的方式主要是以下两种:
(1)显式评分:也就是直接可以看到的、直观的数值评分,它是通过问卷调查形式来收集用户对某些商品的评分,例如你浏览一个商品或者登陆一个浏览器时通常会弹出一个界面,让你某个商品或者某个网站内容进行打分,这就是在获取你对于这个商品或者网站的评分。这种评分会被记录下来用于之后网站向你推荐相关评分较高的内容或者商品。这种显式评分的数据是比较准确的,缺点就是很难获取到,因为大多数用户是看不到对自己有益的事情,一般不会去浪费自己时间去提供评分;
(2)隐式评分:这个就是记录用户购买或者浏览历史行为,来完成数值不等的评分计算。当用户购买一个商品或者浏览一个商品时,就可以认为该用户对这个商品是感兴趣的,并且可以通过用户在该商品的浏览停留时间来判定用户的感兴趣度,停留时间越长,感兴趣度越强,评分也就越高;相反,停留时间越短,感兴趣度就越弱,评分就越低甚至为0。这是一个正向评分或者正向意图,根据既定的规则来将其转换成评分值。这种方式的优点就是能够收集到足够多的评分数据,来丰富用户—物品评分矩阵;缺点就是很难保证得到的用户评分的准确性,并且会遭受到恶意用户的浏览行为,以至于获取到的评分并不能很好的代表用户意图或者兴趣度。
8.总结
基于协同过滤算法来完成推荐的主要方法就是采用最近邻推荐,最近邻的选择包括最近邻用户(对等用户)和最近邻物品(对等物品),这种方法是最经典、效果是较为稳定的、市面上较为普遍使用的推荐方法。所以,设计任何一个推荐系统都必须要先了解协同过滤算法。至于是基于用户最近邻推荐还是物品最近邻推荐就要看读者使用场景了,主要取决于评分矩阵的稀疏度,选择的评分矩阵越丰富,得到的推荐效果普遍较好。
9.几点思考?
有了上述文章的铺垫,不知道读者有没有考虑到协同过滤算法的劣势在哪?或者说有没有协同过滤算法使用无效的场景?并且上面提到的评分矩阵问题,当用户对物品评分较少或者说几乎不评分所导致的评分矩阵过于稀疏时,该如何对评分矩阵进行处理来完成推荐?同时,在评分矩阵稠密时,虽然可以用上述讲到的Redis的键值对来存储离线预处理相似度数值,这样可以解决了存储问题,但是实际需要实时计算的数据仍然是数以亿计的,这就导致算法的时间复杂度不太乐观,有没有什么办法可以解决这个问题,既保证了推荐效果,又能更大的降低该算法的时间复杂度?这些思考都是我们在设计推荐系统需要考量的,我将会在后续文稿中进行阐述,介绍其他的推荐算法,来一一解决以上几个问题。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】