随着机器学习领域不断发展,对于处理机器学习的团队来说,在1台机器上训练1个模型已经有些难以为继,并且现在业界的共识是机器学习已经不仅仅是简单的模型训练。
在模型训练之前、过程中和之后,需要进行许多活动,对于要生成自己的ML模型的团队来说尤其如此。下图常常被引用来说明此类情况:
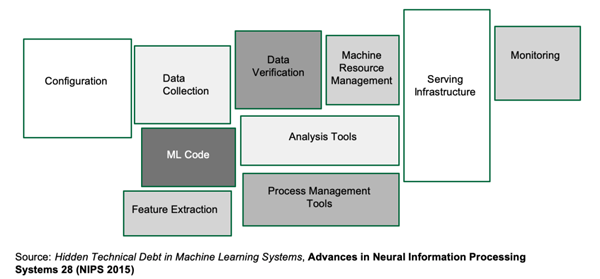
对于许多团队来说,将机器学习的模型从研究环境应用到生产环境这一过程困难重重,背负很大的压力。糟糕的是,市面上处理每类问题的工具都数量惊人,而这些海量工具都有望解决你所有的机器学习难题。
但是整个团队学习新工具通常很耗时,并且将这些工具集成到你当前的工作流程中也并不容易。这时,或许可以考虑Kubeflow,这是为需要建立机器学习流水线的团队而打造的一个机器学习平台,它包括许多其他工具,可以用于服务模型和调整超参数。Kubeflow尝试做的是将同类最好用的ML工具整合在一起,并将它们集成到一个平台中。
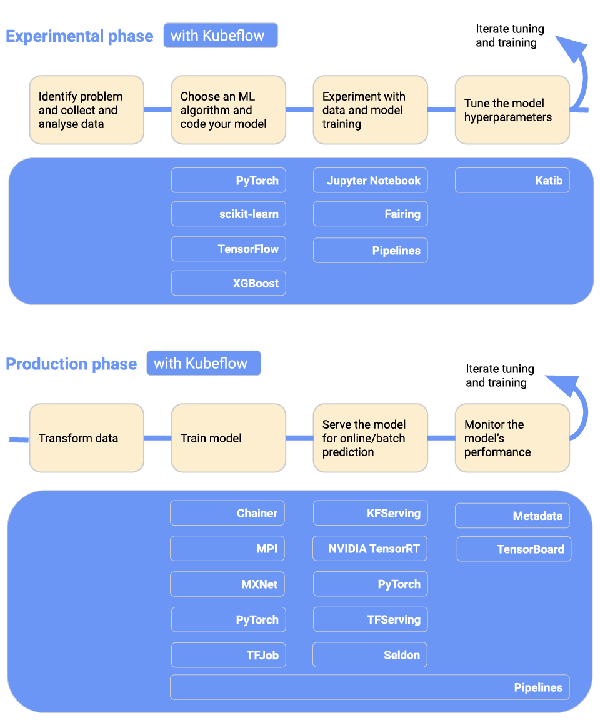
来源:https://www.kubeflow.org/docs/started/kubeflow-overview/
顾名思义,Kubeflow应该部署在Kubernetes上,既然你是通过Rancher的平台阅读到这篇文章,那么你大概率已经在某个地方部署了Kubernetes集群。
值得注意的是,Kubeflow中的“flow”并不是表示Tensorflow。Kubeflow也能够与PyTorch一起使用,甚至可以与任何ML框架一起使用(不过支持得最好的框架还是Tensorflow和PyTorch)。
在本文中,我将向你展示如何尽可能简单地安装Kubeflow。如果在你的集群上已经有GPU设置,则过程将更为简单。如果尚未设置,那么你需要执行一些额外的设置步骤,因为许多机器学习需要运行在NVIDIA GPU上。
在Kubeflow上设置GPU支持
假设你已经安装了Docker 19.x。
1、 安装NVIDIA 容器运行时
在所有带有GPU的节点上:
- % distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
- % curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
- % curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
- % sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
- % sudo apt-get install nvidia-container-runtime
现在,修改Docker守护进程(Daemon)运行时字段:
- % sudo vim /etc/docker/daemon.json
粘贴以下内容:
- {
- "default-runtime": "nvidia",
- "runtimes": {
- "nvidia": {
- "path": "/usr/bin/nvidia-container-runtime",
- "runtimeArgs": []
- }
- }
- }
现在重启Docker守护进程:
- % sudo systemctl restart docker
2、 安装NVIDIA设备插件
在master节点上,创建NVIDIA设备插件:
- % kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta/nvidia-device-plugin.yml
接下来,正式开始安装Kubeflow。
安装Kubeflow
注意:在撰写本文时,Kubeflow的最新版本是1.0。它与Kubernetes 1.14和1.15版本兼容。
Step0:设置动态Volume配置
在我们安装Kubeflow之前,我们需要设置动态配置。
一种方法是使用Rancher的local-path-provisioner,其中使用了基于hostPath的节点持久卷。设置非常简单:将其指向节点上的路径并部署YAML文件。缺点是无法控制volume容量限制。
另一种方法是使用网络文件系统(NFS),我将在下文展示具体步骤。
在Master节点上设置网络文件系统
假设你将大部分数据存储在本地,那么你需要设置NFS。在这里,我假设 NFS server位于master节点10.64.1.163上。
首先,为NFS安装依赖项:
- % sudo apt install -y nfs-common nfs-kernel-server
然后,创建一个根目录:
- % sudo mkdir /nfsroot
将以下条目添加到/etc/exports:
- /full/path/to/nfsroot 10.64.0.0/16(rw,no_root_squash,no_subtree_check)
请注意,10.64.0.0是节点的CIDR,而不是Kubernetes Pod CIDR。
接下来,通过以下命令将共享目录导出为sudo:
- % sudo exportfs -a
最后,要使所有配置生效,请按如下所示重新启动NFS内核服务器:
- % sudo systemctl restart nfs-kernel-server
另外,确保nfs-kernel-server在服务器(重新)启动时启动:
- % sudo update-rc.d nfs-kernel-server enable
在worker节点上设置NFS
为NFS安装依赖项:
- % sudo apt install -y nfs-common
安装NFS Client Provisioner
现在,我们可以安装NFS Client Provisioner——并且终于可以向你们安利我最爱的Rancher功能之一:应用商店!
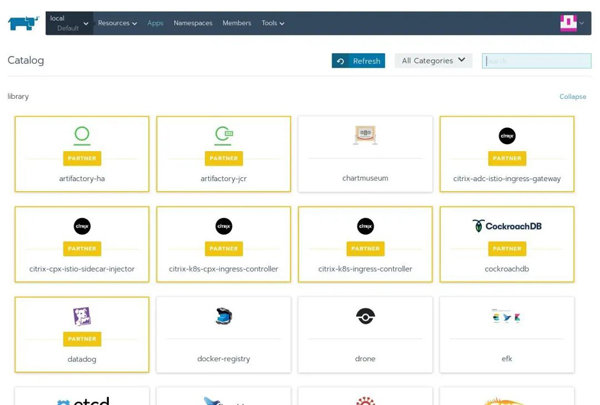
默认情况下,Rancher自带了许多已经经过测试的应用程序。此外,我们还可以自行添加整个Helm Chart到应用商店里。
点击Apps,然后点击【Manage Catalogs】
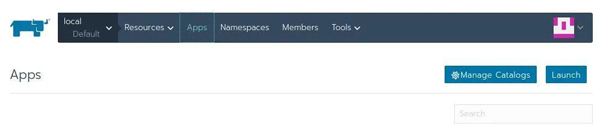
然后选择【Add Catalog】:

填写以下值:

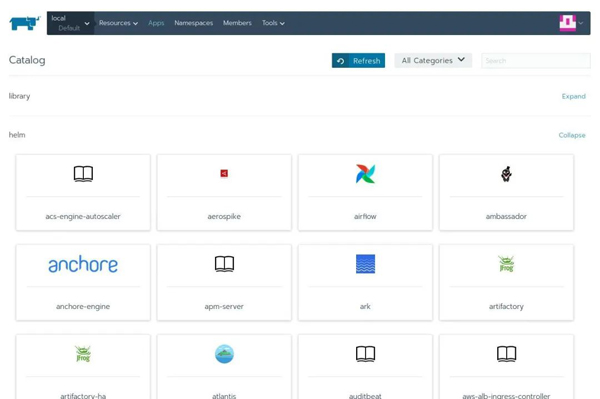
点击【Create】,回到【Apps】页面。稍微等待一会儿,你将看到helm部分有了许多应用程序。你可以点击【Refresh】来查看进程:
现在,在搜索框内输入nfs,然后你将看到2个条目:
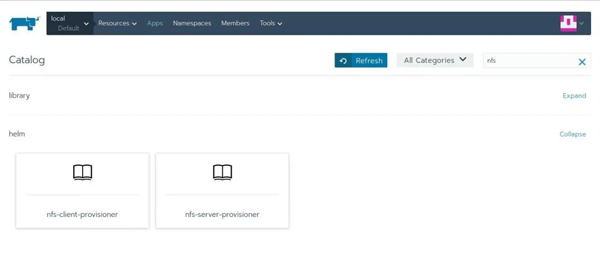
其中一个正是我们要找的:nfs-client-provisioner。点击它,然后你将看到:
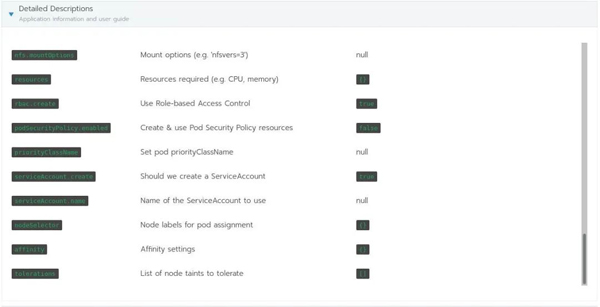
这是可用于nfs-client-provisioner的chart的所有选项,你将需要使用它们来填写以下内容:
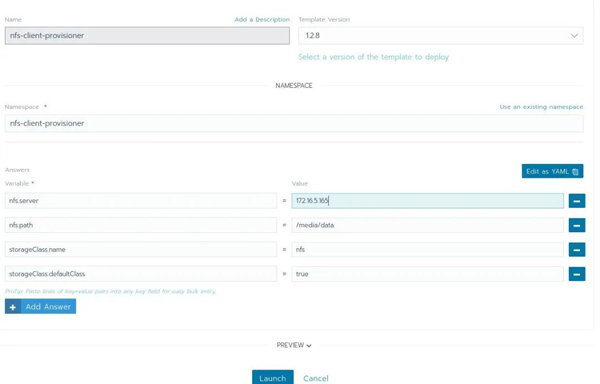
填写完毕后,你可以点击【Launch】按钮。等待一会儿,让Kubernetes下载Docker镜像,并将一切设置完毕。所有操作都完成后,你将看到以下页面:
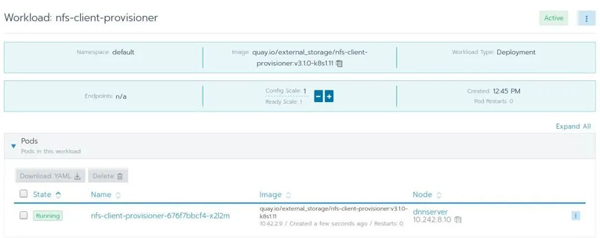
我真的太喜欢应用商店这个功能了,它是我最喜欢的功能之一,因为它的存在,使得在集群上安装和监控应用程序变得简单和方便。
Step1:下载并安装kfctl
这是Kubeflow的控制工具,与kubectl类似。你可以从Kubeflow的release页面下载它:
https://github.com/kubeflow/kfctl/releases/tag/v1.0.2
然后,解压文件并将二进制文件放入你的$PATH中。
Step2:安装Kubeflow
首先,指定一个文件夹存储所有的Kubeflow YAML文件。
- $ export KFAPP=~/kfapp
下载kfctl配置文件:
- wget https://raw.githubusercontent.com/kubeflow/manifests/v1.0-branch/kfdef/kfctl_k8s_istio.v1.0.2.yaml
请注意:如果你已经安装了Istio,则需要编辑kfctl_k8s_istio.v1.0.2.yaml并删除istio-crds和istio-install应用程序条目。
然后,导出CONFIG_URI:
- $ export CONFIG_URI="/path/to/kfctl_k8s_istio.v1.0.2.yaml"
接下来,你需要指定一堆环境变量,这些环境变量将指示Kubeflow配置文件下载到的位置:
- export KF_NAME=kubeflow-deployment
- export BASE_DIR=/opt
- export KF_DIR=${BASE_DIR}/${KF_NAME}
安装Kubeflow:
- % mkdir -p ${KF_DIR}
- % cd ${KF_DIR}
- % kfctl apply -V -f ${CONFIG_URI}
你需要一些时间等待一切都设置完毕。
访问Kubeflow UI
要访问UI,我们需要知道Web UI所在的端口:
- % kubectl -n istio-system get svc istio-ingressgateway
返回以下内容:
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- istio-ingressgateway NodePort 10.43.197.63 <none> 15020:30585/TCP,**80:31380/TCP**,443:31390/TCP,31400:31400/TCP,15029:32613/TCP,15030:32445/TCP,15031:30765/TCP,15032:32496/TCP,15443:30576/TCP 61m
在本例中,它是80:31380,这意味着你可以通过http://localhost:31380访问Kubeflow UI:
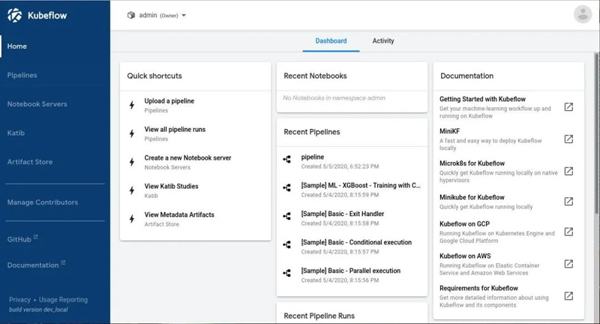
如果你成功地看到了这个页面,那么恭喜你,你已经成功设置Kubeflow🎉
结 论
在本文中,我们首先探讨了为什么需要诸如Kubeflow这类工具——以控制机器学习本身的复杂性。接下来,我们按照步骤为集群进行机器学习工作做好了准备,尤其需要确保该集群可以利用可用的NVIDIA GPU。
在设置NFS时,我们探索了Rancher的应用商店,并将Helm Chart添加到应用商店中。它为我们提供了在Kubernetes集群上可以安装的所有Kubernetes应用程序。最后,我们完成了在集群上安装Kubeflow的步骤。