本文转载自微信公众号「咖啡拿铁」,作者咖啡拿铁 。转载本文请联系 咖啡拿铁公众号。
1.背景
这篇文章是我一直想写的一篇,因为“计算和存储分离”最近几年在大家的视野中出现得越来越多,但其实很多对于其到底代表着什么也是模糊不清,这里我查阅了很多的资料再结合平时自己的理解,聊聊到底什么是“计算和存储分离”
2.何为计算?何为存储?
要了解计算和存储分离到底是什么,那么我们就需要理解什么是计算,什么是存储。
计算这个单词有运算之义,和数学的关系密不可分。大家回想一下以前数学考试的时候,那一道道的数学题怎么得出结果的,这一过程其实称之为计算。那我们这里谈论的其实是计算机计算,所以我们可以得出通过计算机得到问题的结果这个就叫做计算机计算,也就是我们这里所谈论的"计算"。
对于存储来说,这个概念比较难以定义,很多人都简单的认为这个是硬盘,U盘等。但其实在我们的计算机计算过程中和存储是密不可分的,我们知道CPU是由控制器、运算器和寄存器组成的,我们在运行一段程序的时候我们的指令是存储在我们的存储器的,我们所执行的每一个步骤都和存储分离不开。比如我们以前考试的时候选择题,大家关心的只是你选择是否正确,不会关心你的运算过程,你的运算结果可以看做是硬盘,需要持久化给评卷人看,而你的计算过程类似草稿纸,虽然不需要给评卷人看,但是一样的是实实在在的写在了纸上。
上面我们说了在计算机中计算和存储其实是分离不开的,我们想想如果将计算和存储分离开来,通过高速网络进行交互,那么我们的CPU的每一条指令都需要通过网络传输,而我们的网络传输和我们当前的CPU速度完全不匹配,所以我们的计算和存储分离其实是一个伪需求,当然在未来的某一天如果我们的网络传输的时间可以忽略不计,计算和存储分离也就能真正的实现了。
计算和存储分离既然是一个伪需求,那为什么这么多人还在提及呢?那就需要重新再定义一下他们的含义,我们将计算过程中的存储归纳为计算,只关注问题和结果,这就是我们新的“存储”的定义,就类似我们考试的时候草稿纸不需要存放,可以任意撕毁一样。
那这里我们来做一个最终的定义,我们后面所讲的“存储”都是需要持久化的,可以是U盘,硬盘,网盘等等,我们所讲的“计算”其实就是我们的计算过程所需要的CPU和内存等。
3.为何需要计算和存储分离
计算和存储分离并不是现在才出现的一个新名词,在20年前就有NAS-网络附加存储这个东西,本质上也就是使用TCP/IP协议的以太网文件服务器。当时如果想要大规模的存储,就会让服务器将数据保存到NAS这个上面,但是NAS价格及其昂贵,并且扩展比较困难,NAS也就不适用于高速发展的互联网应用。
这个时候谷歌摒弃了之前的观念“移动存储到计算”,采取了“移动计算到存储的观念”,将计算和存储耦合了,因为当时的网络速度对比现在来说慢了几百倍,网络速度跟不上我们的需要。在在典型的MapReduce部署中计算和存储都在同一个集群中进行,比如后续的hadoop。这里其实也就是用本地IO速度来替换网络传输速度。
随着技术的进步,我们的网络速度也越来越快,我们的瓶颈不再是网络速度,但是我们的磁盘I/O速度却没有明显的速度增长,计算和存储融合的架构缺点也再逐渐暴露:
- 机器的浪费:业务是计算先达到瓶颈的,还是存储先达到瓶颈的。这两种情况往往是不一样的,往往时间点也是不一样的。在架构里就存在一定的浪费。如果说计算不够,也是加一台机器;存储不够,还是加一台机器。所以这里就会存在很多浪费。
- 机器配比需要频繁更新:一般来说在一个公司内机器的配型比较固定比如提供好几种多少核,多少内存,多少存储空间等等。但是由于业务在不断的发展,那么我们的机器配型也需要不断的更新。
- 扩展不容易:如果我们存储不够了通常需要扩展,计算和存储耦合的模式下如果扩展就需要存在迁移大量数据。
由于计算和存储耦合的缺点越来越多,并且网络速度越来越快,现在架构又在重新向计算和存储分离这一方向重新开始发展。
4.谁在使用计算和存储分离
上面我们讲了很多理论相关的知识,相信大家已经对“计算和存储分离”已经有一定的认识了,那么其到底在哪些地方做了使用呢?其影响比较大的有两块,一个是数据库,另外一个是消息队列,接下来我会具体讲下这两块到底是怎么利用“计算和存储分离”的。
4.1 数据库
一谈到数据库我们不得不想到MySql,这个应该也是大家最熟悉的数据库,下面是Mysql的一个主从架构图:
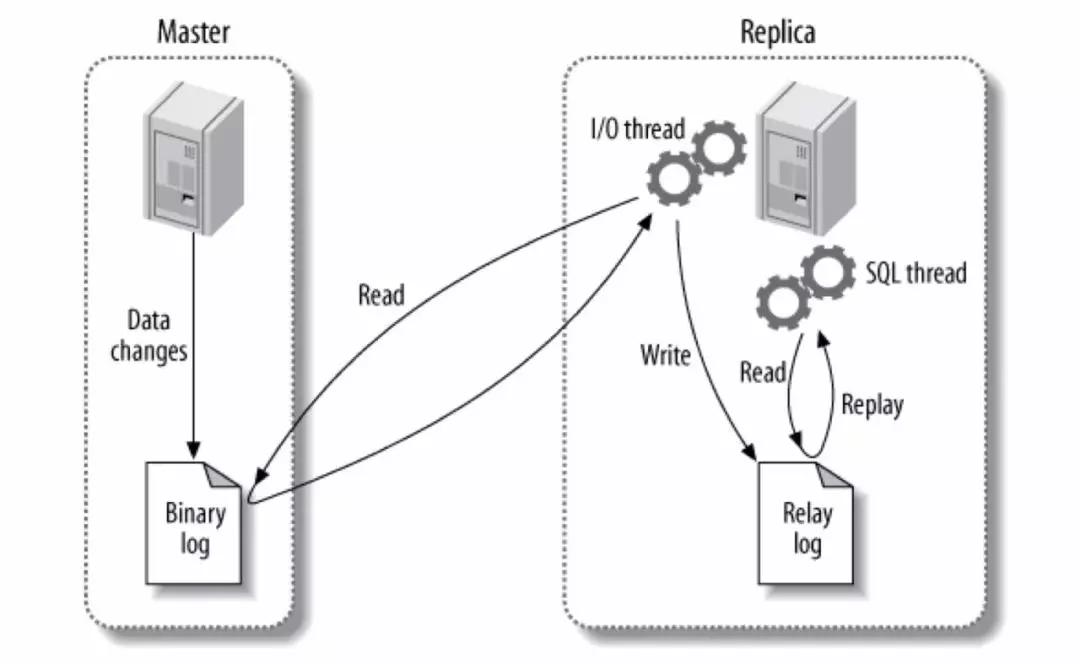
可以看见我们的master接收数据的变更,我们的从数据库读取binlog信息,重放binlog从而达到数据复制。
在Mysql的主从架构中有很多问题:
- 主库的写入压力比较大的时候,主从复制的延迟会变得比较高,由于我们其复制的是binlog,他会走完所有的事务。
- 增加从节点速度慢,由于我们需要将数据全量的复制到从节点,如果主节点此时存量的数据已经很多,那么扩展一个从节点速度就会很慢高。
- 对于数据量比较大的数据库,备份的速度很慢。
- 成本变高,如果我们的数据库的容量比较大,那么我们相应的所有从节点的容量都需要和猪数据库一样大,我们的成本将会随着我们所需要从数据库的数量进行线性增加。
这一切的问题好像都在指引着我们走向计算和存储分离的道路,让所有的节点都共享一个存储。在2014年,在AWS大会上,AWS就宣布推出Aurora。这是一个面向亚马逊关系数据库服务(RDS)的兼容MySQL的数据库引擎,Aurora完美契合了企业级数据库系统对高可用性、性能和扩展性、云服务托管的需求。目前的Aurora可跨3个可用区的6-路复制、30秒内便可完成故障转移、同时具备快速的crash recovery能力。在性能方面,Aurora现在比RDS MySQL5.6和5.7版本快5倍。
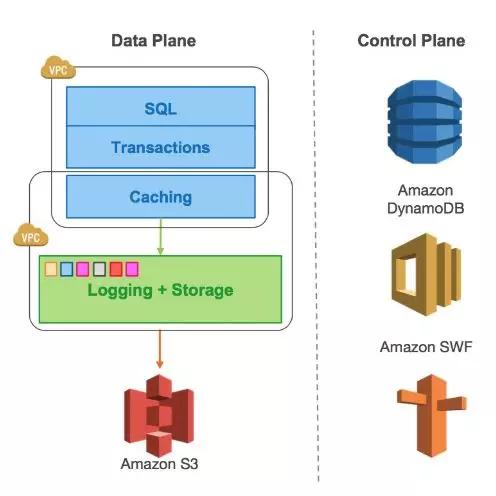
Aurora将MySQL存储层变为为独立的存储节点,在Aurora中认为日志即数据,将日志彻底从Mysql计算节点中抽离出来,都由存储节点进行保存,并且也取消了undolog用于减小计算存储之间的交互和传输数据带宽。
同样的在阿里的团队中,也借鉴了Aurora的思想,并在其上面做了很多优化,由于Aurora对于Mysql-Innodb的存储引擎修改较大,后续的Mysql的更新,必然成本很大,所以阿里的团队在保有了原有的MySQL IO路径的基础之上推出了PolarDB。其设计架构图如下:
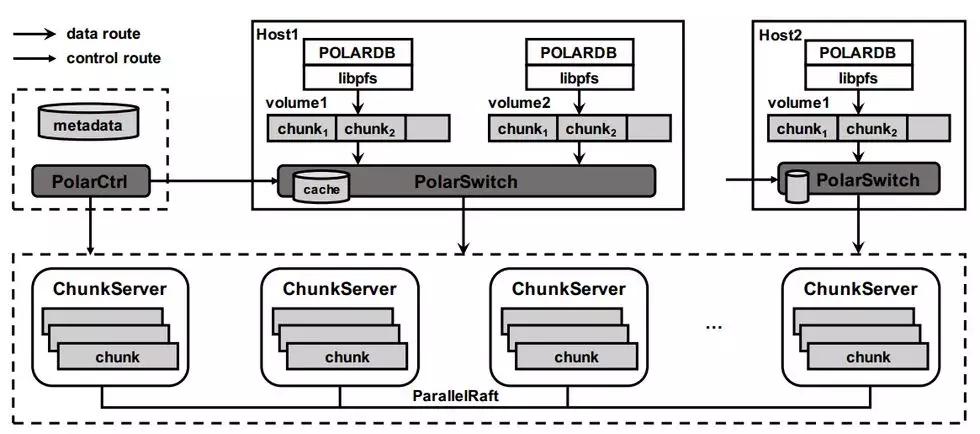
这里我们需要关注下面几个东西:
- libfis:这是一个文件系统库,提供了供计算节点访问底层存储的API接口,进行文件读写和元数据更新等操作,有了这个之后计算节点就不需要关心存储的数据到底在哪。
- ChunkServer可以认为是一个独立的存储子节点,每个ChunkServer管理着一块SSD硬盘,多个ChunkServer组成Polardb存储节点,对于计算节点来说只需要认为其是一个大的存储节点就好。
- PolarSwitch:是部署在计算节点的Daemon,它负责接收libpfs发送而来的文件IO请求,PolarSwitch将其划分为对应的一到多个Chunk,并将请求发往Chunk所属的ChunkServer完成访问。
当然PolarDB还有很多其他的细节,大家有兴趣可以阅读阿里云的官方文档,通过这种共享存储的方式,我们就可以根据自己的业务来进行不同的配置申请,比如我们的对并发要求不高,对数据量要求很大,那么我们就可以申请大量的存储空间,计算资源相对来说就可以较小,如果我们对并发要求很高,尤其是读请求,那么我们就可以申请多台读机器直到满足我们要求为止。
其实不止是这些,现在很多的数据库都在逐渐向“计算和存储分离”靠拢,包括现在的OceanBase,TiDB等等。所以“计算和存储分离”应该是未来数据库的主要发展方向。
4.2 消息队列
我在之前写过很多关于消息队列的文章,有Kafka的,也有RocketMQ的,不论是Kafka还是RocketMQ其设计思想都是利用本地机器的磁盘来进行保存消息队列,这样其实是有一定的弊端的:
- 数据有限,使用者两个消息队列的同学应该深有感触,一般会服务器保存最近几天的消息,这样的目的是节约存储空间,但是就会导致我们要追溯一些历史数据的时候就会导致无法查询。
- 扩展成本高,在数据库中的弊端在这里同样也会展现。
针对这些问题ApachePulsar出现了,pulsar最初由Yahoo开发,在18年的时候一举将kafka连续两年InfoWorld最佳开源数据平台奖夺了过来。
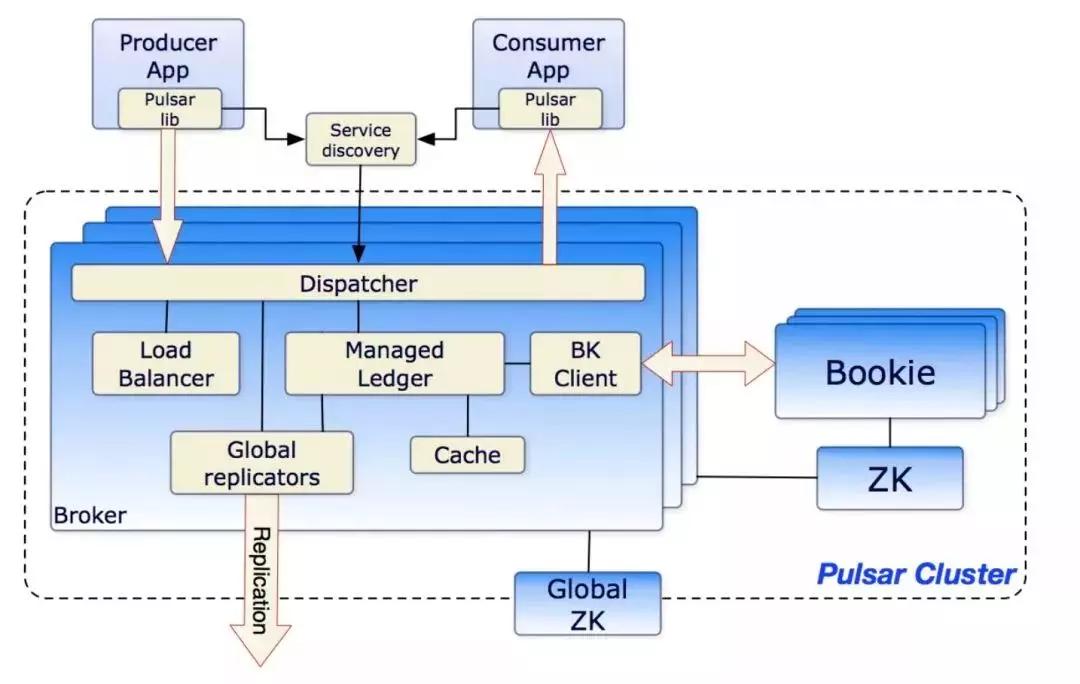
在Pulsar的架构中,数据计算和数据存储是单独的两个结构:
- 数据计算也就是Broker,其作用和Kafka的Broker类似,用于负载均衡,处理consumer和producer等,如果业务上consumer和producer特别的多,我们可以单独扩展这一层。
- 数据存储也就是Bookie,pulsar使用了Apache Bookkeeper存储系统,并没有过多的关心存储细节,这一点其实我们也可以借鉴参考,当设计这样的一个系统的时候,计算服务的细节我们需要自己多去思考设计,而存储系统可以使用比较成熟的开源方案。
Pulsar理论上来说存储是无限的,我们的消息可以永久保存,有人会说难道硬盘不要钱吗?当然不是我们依然要钱,在Pulsar可以进行分层存储,我们将旧的消息移到便宜的存储方案中,比如AWS的s3存储,而我们当前最新的消息依然在我们比较贵的SSD上。在这个模式下不仅是存储是无限,我们的计算资源扩展也是无限的,因为我们的计算资源基本上是无状态的,扩展是没有任何成本的,所以Pulsar也搞出了一个多租户的功能,而不用每个团队单独去建立一个集群,之前在美团的确也是这样的,比较重要的BG基本上都有自己的Mafka集群,防止互相影响。
Kafka最新的一些提议,也在向这些方面靠拢,比如也在讨论是否支持分层存储,当然是否采用“计算和存储分离”架构这个也是不一定的,但是我认为“计算和存储分离”的方向也是消息队列未来发展的主要方向。
总结
“计算和存储分离”随着云原生的发展,在各种系统中出现的次数越来越多,希望大家读完这篇文章能对其有个简单的认识。同时如果大家未来在设计系统的时候,这个方案也可以作为选择方案之一进行考虑。