自监督表征学习发展迅速,但也存在诸多问题。近日,香港中文大学多媒体实验室(MMLab)和南洋理工大学的研究者开源了一套统一的自监督学习代码库 OpenSelfSup。
前言
近几个月来自监督表征学习领域获得了显著突破,特别是随着 Rotation Prediction、DeepCluster、MoCo、SimCLR 等简单有效的方法的诞生,自监督表征学习大有超越有监督表征学习的趋势。
然而,做这个领域的研究者都深有感触:1)自监督任务复杂而多样,不同方法各有各的专用训练代码,难以结合、复用和改进;2)评价方案不统一,不同的方法难以在公平环境下对比;3)动辄百万千万的训练数据量,训练效率是个大问题。
针对这些问题,香港中文大学多媒体实验室(MMLab)和南洋理工大学的研究者最近开源了一套统一的自监督学习代码库:OpenSelfSup。
开源地址:https://github.com/open-mmlab/OpenSelfSup
OpenSelfSup
统一的代码框架和模块化设计
OpenSelfSup 使用 PyTorch 实现,支持基于分类、重建、聚类、memory bank、contrastive learning 的多种自监督学习框架,目前收录了 Relative Location、Rotation Prediction、DeepCluster、OnlineDeepCluster、NPID、MoCo、SimCLR 等一系列表现较好的自监督表征学习方法,后续还将陆续跟进学术界最新算法。
在这个框架下,每个算法被拆解为 backbone、neck、head、memory_bank (optional)、hook (optional) 等多个可独立设计的模块,每个模块均提供多个可选方案,开发者也可以自行设计各个模块。
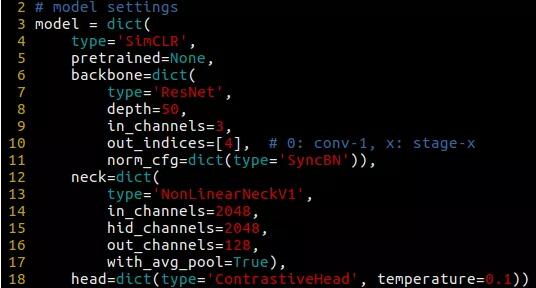
SimCLR 中的 backbone、neck 和 head 设计
标准化的评测方案
OpenSelfSup 目前支持 ImageNet/Place205 Linear Classification、ImageNet Semi-Supervised Classification、PASCAL VOC07 Linear SVM、PASCAL VOC / COCO Object Detection 等多个基准的评测方案,可以做到一行命令跑评测,非常方便。
高效率的分布式训练
OpenSelfSup 收录的算法全部实现了多机多卡的分布式训练、提特征和测试。
上手容易
该代码库的环境配置、数据配置均有 from scratch 的脚本或详细指导,简单易行。训练和测试现有算法,只需要一行命令即可搞定。
高度灵活性和可扩展性
1. 改进现有算法。OpenSelfSup 用 config 文件来定义各种参数和模块,方便修改。config 中还支持一些较复杂的调整,比如 data augmentation 的组合、learning rate schedule、独立调整某些网络参数的优化参数等。例如,你希望单独调整 head 中 fully-connected layer 的 momentum 和 learning rate,或者 backbone 中某几层的 weight decay 等等,那么你可以在 config 中 optimizer: paramwise_option 下用正则表达式筛选出对应网络参数,然后指定这些值,而不需要改动代码。

DeepCluster中指定head(fc layer) 的momentum为0
2. 使用自己的训练数据。OpenSelfSup 将数据处理和数据源解耦。使用自己的训练数据,只需要新增一个自己的 data source 文件,并在 config 中指定即可。
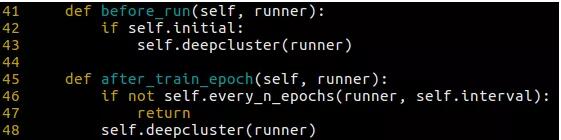
3. 设计自己的算法。高度模块化的设计使得自行设计算法变得非常简单。你只需要设计自己的模块或者复用现有模块,然后新建一个模型文件将这些模块组织起来即可。如果你的算法包含间隔 iteration、间隔 epoch 的操作(例如 DeepCluster 需要在每个 epoch 结束后对训练集做聚类),也只需要新建一个 hook 来定义这些操作,并在 config 中设置这个 hook 即可。hook 的调用是自动进行的。
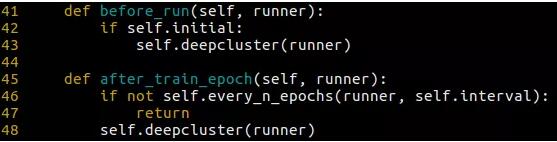
DeepCluster 初始聚类和每 n 个 epoch 后做聚类
结语
OpenSelfSup 是一个长期维护的开源项目,旨在方便学术界和工业届的研究者推动自监督表征学习领域继续前进。也希望有兴趣的研究者、开发者帮助继续完善 OpenSelfSup,为这个领域贡献自己的力量。