今天分享的主题是工行“去 O”数据库选型与分布式架构设计。
图片来自 Pexels
本次分享分为三个章节:
- 金融行业的需求核心与策略
- 工行数据库选型的发展历程,即方案选型历程
- 转型中遇到的各种心酸坑
金融行业的核心需求与策略
传统 IT 架构挑战
大家可能都知道,工行最早是基于 IBM 大型主机搭建的核心系统,以及基于 Oracle 和 IBM WAS 搭建的 OLTP 系统,在分布式体系大热之前处于同业领先地位。
当然现在也是处于同业领先的,但是科技成本也相对较高,所谓的一份价钱一分货就是这个道理。

但是随着分布式技术的成熟,传统的 IT 架构面临着四大挑战:
①从处理能力层面来看,传统应用(也叫巨石型应用)系统规模庞大,采用集中式架构设计,使用单一系统垂直扩展模式,扩展能力相对来说是有限的。
另一方面,大数据时代引发海量数据分析处理和存储处理的问题,对扩展性、可靠性和吞吐量提出了较高要求。
②从运行风险层面来看,客户对金融行业的系统有着更高的业务连续性保障要求,对不可用问题实际上是零容忍的,比如要求 7*24 小时业务不能中断。
③从快速交付层面来看,传统巨石型应用实际上与快速交付是相悖的,应用内部模块、应用与应用之间耦合度高,使得软件开发和产品服务交付周期长,无法满足业务快速上线的需求,从而逐渐泯然众人矣,淹没在茫茫的金融行业洪流中。
大家可以看到不论是金融科技还是科技金融,一大堆的金融公司已经淹没在前浪里。
④从成本控制来看,大型主机运营费用昂贵,商业产品 License 费用高,买个机器和服务随随便便就几千万上亿的支出,真的是太贵了,所以随着业务系统做大做强,产品成本可能会成为压死骆驼的最后一根稻草。
为此,我们可以首先得出三点需求:
- 应该优化应用架构、数据架构和技术架构。
- 应该建设灵活开放、高效协同、安全稳定的 IT 架构体系。
- 能够强化对业务快速创新发展的科技支撑。
双十一压力
说到这里,就不得不吐槽阿里的“双十一”,将购买压缩到一天,对顾客和金融系统来说造成双重压力,相较而言,京东的 618 就比较人性化,每天都可以剁手。

我们可以看下双十一的峰值变化情况,从 2009 年开始,峰值只有 400 笔/秒,相较主机而言,有很大的差距,当然这也与他们当时的名气小有关。
但是 2015 年开始,借着云化和分布式的大旗,以及当时 BAT 的领头羊地位,仅 4 年时间,就从 2015 年的 14 万笔/秒迅速攀升至 2019 年的 54 万 4 千笔/秒。
这就给金融行业的系统建设带来了四个问题:
①高并发问题,我们可以看到,阿里为了提升峰值,做了大量的缓存,鼓励使用花呗,降低与外系统的交互,但是依然对金融行业产生额外的压力。
②高可靠性要求,确保系统稳定可靠,客户可以稳定支付成功,避免因不佳的客户体现导致用户流失。
③高成本压力,大幅扩容的设备,以及随之产生的运维成本,以及昂贵的商业 liscence,给金融行业带来一定的成本负担。
④同业竞争要求,大家都在做竞品分析,和同行进行比较,所以别人 ok,你挂了,你面子上还挂的住么,所以各机构在双十一前进行大量的模拟测试,类似于高考前的黑暗日子。
金融行业分布式的核心诉求及策略

为此,金融行业分布式的核心诉求及策略可以总结为以下五点:
①应该具备企业级的业务支撑能力,支持高并发、可扩展和海量数据库存储及访问;原则上应支持同城双活,实现集中式向分布式的转型。工行的两地三中心容灾体系在国有大型银行中属于第一梯队。
②应能大幅降低使用成本,可以基于通用的廉价的 X86 硬件基础设施;降低商业产品依赖,拥抱开源产品,互联网企业已经给我们做了一个很好的参考。
③应该提升数据库的运维自动化和智能化能力,支持与自身系统进行适配性定制,工行即实现了行内系统适配定制。
④金融行业还应考虑到社会声誉性要求,客户对金融行业的期望很高,特别是对银行等金融组织,所以要求也更加严格,原则上应该是 7*24 小时的不间断服务。
像当年支付宝在 2015 年的支付瘫痪事件仅仅上了下热搜,但是 2013 年工行因为 IBM 主机 Bug 的问题却上了新闻联播,这就是所谓的爱之深责之切吧。
⑤要考虑到政治因素风险,虽然全球化要求技术无国界,但是从去年开始的贸易战,以及美国的实体管制清单,我们可以看到技术是有国界的。
近期 HashiCorp 发布公告,其企业版产品禁止中国使用已经引发了一种担忧。说起 HashCorp ,大家可能不一定熟悉,但是其旗下有大名鼎鼎的产品 Consul,可以简化分布式环境中的服务注册与发现流程,大家一定耳熟能详。
最后中国人民银行在 2019 年 8 月 23 日发布了《金融科技(FinTech)发展规划(2019-2021)》中提到“做好分布式数据库金融应用的长期规划,加大研发与应用投入力度,妥善解决分布式数据库产品在数据一致性、实际场景验证、迁移保障规范、新型运维体系等方面的问题,这也给金融行业指明了方向。
选型的发展历程(方案选型历程)
接下来,给大家介绍下如何选型以及工行的选型历程。
工行分布式转型发展历程
大家可以看下工行分布式的发展历程:

其大致可分为 2 个关键阶段,2016 年初-2017 年末为基础研究及试点阶段,之后为转型实施及推广阶段。
大致有如下五个关键时点:
- 2016 年初工行进行分布式体系研究,建立了基于 Dubbo 框架的分布式生态服务。
- 2016 年底借着人民银行对于个人账户的管理要求,实行三类账户的场景,开始了基于分布式的 OLTP 数据库研究,并确定了基于开源 MySQL 的 OLTP 数据库解决方案,因为 MySQL 8.0 的不成熟,所以我们采用了 MySQL 5.7。
- 2017 年末,我们完成开源 MySQL 初步能力体系的建设,涵盖了基础研究、配套方法论、应用试点等等。
- 2018 年开始大规模的实施和推广,我们逐步建立企业级的数据库服务能力,包括引入了分布式的中间件,在高可用、运维能力的提升,资源使用率的提升,MySQL 上云及自主服务的建设等等,同时开启了对 OLTP 的分布式数据库进行了研究。
- 2019 年 11 月我们实现了国产分布式数据库产品 GaussDB 试点上线。
方案选型调研
大家可以看下工行的选型过程,希望可以给大家带来一定的参考:

工行的技术规划是相当严谨的,所以当时我们从五个层次进行了考量:OLTP 分布式数据库、NewSQL 数据库、支持分布式架构、自主可控、开源抑或商业。
当时我们的第一个疑问是,到底是选 NoSQL、NewSQL 还是关系型数据库。
当时 MongoDB、Redis、Cassandra、HBASE 等 NoSQL 数据库开始在某些场景下大热,但是可用场景不满足我们的 OLTP 业务场景需求。
NewSQL 随着 Google 的 Spanner 和 F1 开始进入大家的视野,但是国内可以考据的只有相关的 paper;国产的 TiDB 也是小荷初露尖尖角,但是毕竟还是幼儿期。
而 DB-Egines 发布的《2016 年全球数据库大盘点》,Oracle、MySQL 和 SQL Server 三大数据库产品遥遥领先。
MySQL 当时在互联网公司的名气是越来越响,谷歌、淘宝、百度、腾讯、豆瓣、网易、脸书等都使用了 MySQL。
一方面 MySQL 提供了免费版,另一方面 Oracle 收购 Sun 后,可以很明显的看到 MySQL 越来越规范,5.5、5.6、5.7 均可以看到很明显的提升,5.7 号称性能是 5.6 的 3 倍,5.6 号称是 5.5 的 2 倍。
为此,我们经过谨慎的验证,选取了 MySQL 作为分布式数据库的第一选型,毕竟业界有很多丰富的案例。
而且在互联网企业里面得到了很好的实践,在业界资源案例和周边产品都很丰富,能应对我行的高并发、弹性扩展需求。
同时其具有如下特点:
- 开源,基于 GPL(GNU 通用许可证)可以免费使用修改,当时很多公司都基于 MySQL 进行了深入定制,但是在与他们的交流过程中,发现版本归并真的是一种梦魇。
- 高可用,具有优秀的架构设计及相当丰富的周边产品,实现了企业级的高可用性和高扩展性。
- 免费,有效降低企业运行成本。
- 趋势,产品成熟度、排名一直遥遥领先,占行业应用的比重增大,产业链丰富,从业人员有规模效应。
然后我们选择了 MySQL 5.7,其相较之前的版本有六个优点:
- InnoDB 增强,在线修改 ibp,快速扩展 VARCHAR,UNDO 可回收,可关闭死锁检测。
- 复制增强,多源复制,基于 WRITESET 的并行复制,增强半同步,在线设置 repl filter。
- 优化器增强,几乎重构优化器,EXPLAIN 增强,引入 Optimizer Hints。
- 安全性增强,新增密码过期机制,支持账号锁定等。
- 功能增强,默认开启 PFS,新增 sys schema 等。
- 其他增强,支持多个触发器,新增 Query Rewrite,支持设置 SQL 执行最长时间。
方案技术栈
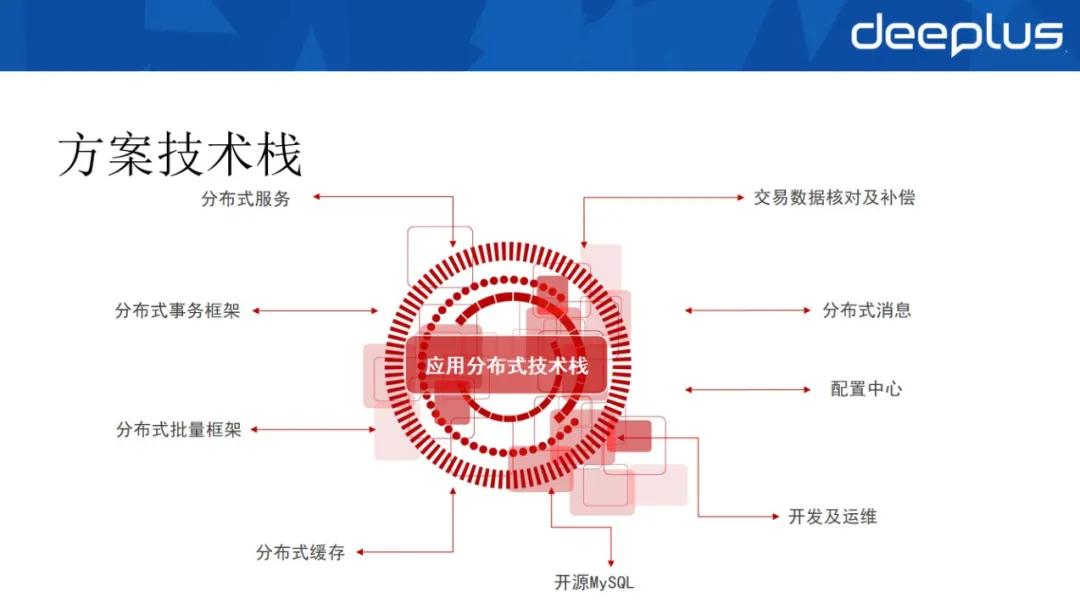
基于 MySQL 选型,还应考虑一系列的分布式架构技术栈,包括分布式服务、分布式事务框架、分布式批量框架、分布式缓存、交易数据核对及补偿、分布式消息、配置中心、开发及运维管理。
这里提醒下大家,在选型上没有最好的产品,只有最适合自己的产品:
①分布式事务,业界实际上有多种解决方案,2PC(2 阶段式事务提交)、3PC、TCC 和 SAGA 模型等等,我们这 4 种方案我行都有应用在使用,互为补充,满足不同业务场景对事务强一致性或最终一致性的要求。
②业务层面,在交易或者应用级层面进行数据核对及补偿,有些场景就是在传统的 OLTP 的情况下,也会对应用上下游进行核对和补偿。
③分布式消息,我们选取了 Kafka 作为分布式消息中间件。
④分布式批量框架,在大规模的数据结点上进行批量操作的一个整体的解决方案。
⑤运维层面,我行建立了统一的运维管理平台,纳入所有数据库节点,实现一键式的数据库安装、版本升级、基线参数配置等等。并且实现了多种高可用策略配置,包括自动、人工一键式切换。
为什么要有自动化和人工的两种切换方式?这里我要解释下,一种新的事务上线之前,都会面临一些挑战和怀疑的,都是一个循序渐进的过程,特别是是在金融行业,自动真的好么?万一搞错了怎么办?决策因素和模型是否设计正确?设计正确了是否编码正确?
最难的是还要应对不同应用场景的需求,有的应用要求 RPO 优先,有的应用又要求 RTO 优先。
我们之前经过充分调研,预见到该种情况,所以我们提供了多种高可用策略的灵活配置,以便满足不同应用的个性化要求。
我们的高可用整体上面基于 MySQL 的复制技术,通过半同步复制和多数派共识机制实现冗余备份,基于 MySQL binlog 日志实现自动数据补全,保障数据的一致性。
其他考量
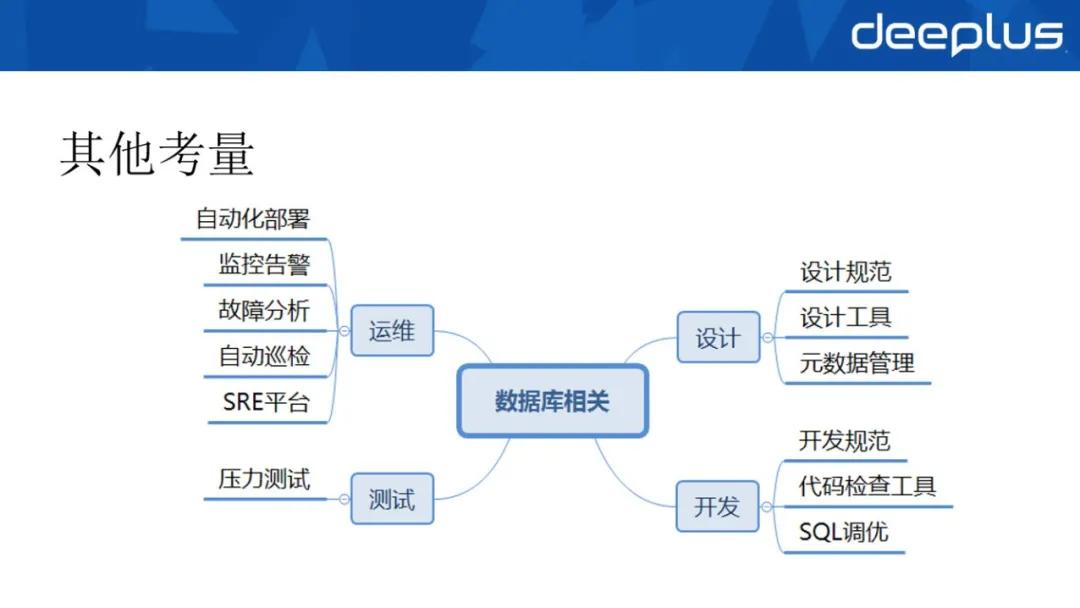
除此以外,数据库选型后,还应完善相关体系,规范设计、开发、测试和运维,实现管控的体系化和自动化,才能避免眼高手低,减少生产安全风险。
①在设计层面,在验证功能、新特性和配置基线,数据备份恢复的基础上,我们参考了爱可生、阿里等公司的规约,建立了 MySQL 设计指引,可以说,我们是站在巨人的肩膀上成长的。
加强元数据管理,提出元数据完备性、明确性、具象性和前瞻性的要求,建立应用的元数据标准,统一数据架构设计,架构师设计表结构时均基于元数据进行设计,提升数据架构质量。
此外,我们还开发了表结构设计工具,将其融合在 Excel 中,实现对元数据的自动应用,支持自动生成脚本,简化架构师的贯标操作,将人员成熟度的要求降至最低,提升设计效能和质量。
②在开发层面,我们制订了开发规范和 SQL 调优指引,同时基于 sonar 开发了 MySQL 检查工具,支持对基于 myBatis 的 mapper 文件进行解析,提前发现 SQL 不规范的写法。
同时将 sonarlint 插件纳入开发人员必备插件,实现规则的云化部署和本地联动扫描分析,将规范融入开发过程中,提升开发人员的 SQL 编写能力。
③在测试层面,我们自研压力测试服务平台,尽量减少性能瓶颈,提前发现 SQL 性能问题。
④在运维层面,感觉应该是最重要的一个层面,我们需要考虑自动化部署、监控告警、故障分析、自动巡检以及 SRE 平台,还有数据迁移、备份恢复、配置管理、版本升级、多租户等等。
随着节点的增加,运维实际上是一个很大的挑战,几千几万个节点,安装、监控、报警、故障、人工处理等非常麻烦。
必须要实现自动化的安装部署,进行批量安装部署,同时批量串行还不行,时间太长了,要并行,并行太高了,网络的流量又会受到很大的影响,所以很多场景都需要细细打磨,还要按照博弈论的思路建立纳什均衡。
监控告警里有事件等级,如何划分各种等级,都需要灵活定制支持,建立基线告警,建立应急流程。
像华为等公司都有基于设备的网络拓扑图,问题在哪个节点,可以快速分析和定位,所以说运维是一个很麻烦的事情,像故障分析,完善日志记录、采集和分析,建立故障分析规范。
自动巡检,自动化的巡检和评分报告,对实例状态进行健康评分。在这个阶段我们实现了同城 RPO=0,RTO=分钟级目标,RPO 为 0 的切换,问题可监控,实现了人工或自动的一键式切换。
最后我们不得不提到 SRE,很多人会联想到运维工程师、系统工程师,其实不然,SRE 本质上仍然是软件工程师。
SRE 最早在十多年前 Google 提出并应用,近几年逐步在国内外 TOP 互联网公司都开始广泛应用。
其中 Google 缔造了 SRE,并奠定了其权威的地位,而 Netflix 将 SRE 的实践做到了极致,Netflix 仅有的个位数的 Core SRE 支持了 190 个国家、数亿用户、数万微服务实例业务规模的运维。
像数据库瓶颈,顶配数据库空间仍然无法支撑业务半年发展;慢 SQL 数量爆发式增长,应用稳定性岌岌可危;人工运维风险极高;人工运维频率高,研发幸福感下降这些大家都会遇到的问题也会逐渐地遇到。
他山之石,可以攻玉,我们完全可以把别人的挫折拿过来,避免自己走弯路。
MySQL 上云
在逐步推进的过程中,完善选型体系建设后,为了确保资源的有效利用,上云实际上是一种必然的选择。
从工行来看,经历 1-2 年的发展,MySQL 数据库节点就已经增至几千套,机房和设备实际上已成为一个瓶颈,再这么玩儿下去机房容量不足了,所以必须提升资源的使用效率。
我行新建应用时,一般都会进行 1-3 年的一个超前规划,业界也是同样的做法,为了稳定运行,避免出现资源瓶颈,基本上提交资源申请时,都选择物理机。
但是大规模的申请物理机,而当前应用的交易量又无法达标,所以资源浪费非常严重。
根据评测,相较 Oracle,MySQL 数据库实例单体性能容量较小,数据容量普遍小于 500G,同时超过一定容量的就要进行分库,但是一台物理机部署 1 个数据库的方式并未发生变化,MySQL 的服务器资源密度较低。
同时运维效率低,在服务器、存储、网络等基础设施环节的运维和交付仍然需要大量手工操作。
业界普遍的做法就是将 MySQL 上云,实现云化部署,借助成熟的云体系实现弹性伸缩和动态扩容。
工行有个优势,IAAS 和 PAAS 云处于同业领先地位,有着丰富的经验积累,为此结合行内对于云战略的规划,MySQL 上云是一种必然趋势。
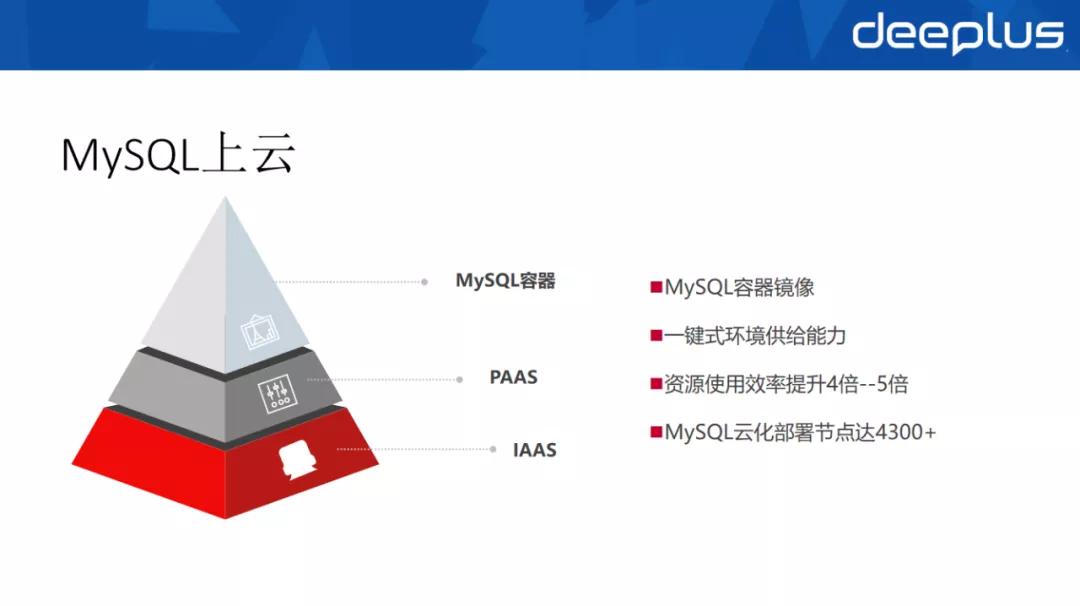
我们提供了 MySQL 的容器镜像,提供了一键式的环境供给能力,通过上容器把 IAAS、PAAS 全部打通,支持快速搭建符合行内标准的基础环境,提升环境支持能力。
工行基于 K8S、SDN、IAAS 建设持久性的状态容器运行集群,通过 SDN 实现容器网络资源的自动化申请,通过底层扩展 K8S 实现容器的固定 IP,业界一般会采用 K8S Operator 实现容器的有状态资源绑定,也包含了固定 IP 绑定。
保守估计,资源的使用效率至少提升了 4 到 5 倍。而且,我们的工作成果也相当喜人,截止当前工行的 MySQL 云化部署节点已达 4300 多个。
工行实施效果
我们可以看下工行的转型成效,首先看下数据:
①我们已实施 200 多个应用,高灾备等级应用占比高达 53%。
②6000 多个 MySQL 节点,高灾备等级应用占比高达 87.31%。
③实施的应用涉及很多核心业务,包括个人、对公、基金以及很多高灾备等级应用,大多数为主机下平台迁移应用,少量应用是从 Oracle 迁移过来的,因为工行将 PLSQL 存储过程用到了极致,所以应用层也因此需要重构。
④我们通过 MySQL 支持的核心交易可以达到日均 7 亿的交易量,经历过双十一和春节的多重考验,峰值 TPS 至少可以达到 1.5 万 TPS,同时支持横向扩展,理论上通过扩展设备还可以无限地增加。
而如果通过主机想达成这个目标,那么挑战就会比较大,这就是建摩天大厦和建排屋的区别。
⑤通过良好的架构设计,我们可以满足两地三中心的架构要求,做到同城 RPO=0,RTO<60s。
⑥在自主能力方面,初步建立了企业级的基于 MySQL 的分布式解决的自主能力:首先是分布式框架+MySQL 的应用级分布式解决方案,该方案承载了我行很多主机下平台应用。
其次是基于分布式中间件 DBLE(原型为 MyCat,后经爱可生公司优化为 DBLE,同时我行进行了深度优化和开发)建立数据访问层,支持应对一些不是很复杂的场景,通过良好设计的分库分表方案即可满足需求。
⑦在成本方面,我行在主机上的成本投入明显下降,近几年我行的业务交易量每年以 20% 的速度增长,但是主机并没有进行扩容,投入还逐年降低。
商业产品的数据库的使用不仅实现零增长,还有所下降。从整个经费上来说,有非常大的降幅。
典型实施案例:信息辅助服务
介绍一下我行的典型案例:信息辅助系统。
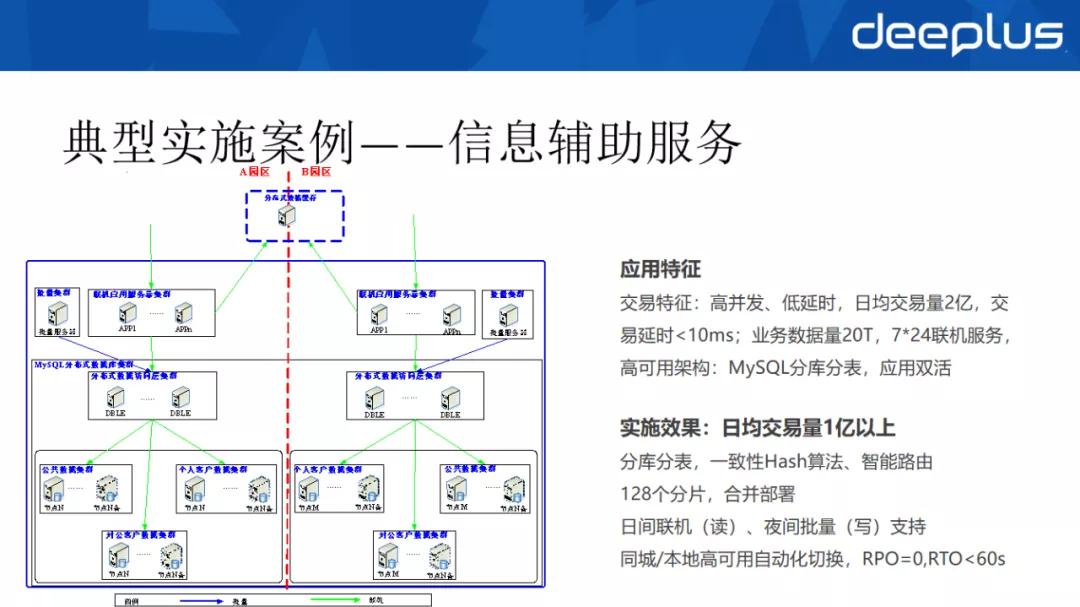
从应用场景分析其需求,需要支持高并发、低延时,日均交易量为 2 亿,交易响应延时要求 10ms 以内,业务数据量大概 20T 左右,要求 7×24 小时的联机服务,这就对应用的高可用提出了新的要求。
为此,通过统一运维管理平台,吸纳所有节点,实现一键式的安装、版本的升级、参数的配置。
①设计层面通过分布式数据中间件 DBLE,进行分库分表,规划了 128个 分片,并对分片进行了合并部署,虽然相较于阿里的 1024 分片来说较少,但是我们使用了一致性 hash 算法,在资源使用上收益很大。
②DBLE 中间件在日间进行联机服务,夜间进行批量变更,把主机上的一些数据同步下来,减少批量作业对联机作业的影响。
③目前我们的高可用架构采用一主三从(1 主库、1 本地半同步库、2 同城半同步库)架构,基于 MySQL 的半同步复制,实现园区级的 RPO=0。
通过 DBLE 中间件和管理平台联动完成实现了本地和同城的自动化切换,RPO=0,RTO<60S,完全满足工行的业务要求。
最后补充说明下,为了实现数据库层面的高可用, DBLE 到数据库的访问同一配置为实 IP。
④这里我补充下我们高可用的发展史,其实我们对高可用方案进行了持续的优化。
同时学习和借鉴互联网包括分布式数据库的一些方案,从 1 主 2 备,本地 1 备和同城 1 备,扩展成 1 主 3 备,通过半同步的机制,做到真正的在系统级去保证 RPO=0。
⑤在异地灾备方面。最开始采用磁盘复制实现灾备,一方面成本比较高,另一方面是冷备,无法热切换,RTO 至少半个小时以上。所以我们后期用了 MySQL 异步复制。
在存储方面采用集中存储,一套集中存储上面需要同时支撑上百个 MySQL 实例,IO 性能直接成为瓶颈,为了应对高并发场景时的 IO 瓶颈,我们直接引入 SSD 盘,基本上把 MySQL 的 IO 瓶颈给解决了。
转型中遇到的各种心酸坑
最后我们说下我行转型过程中遇到的心酸坑。
其实如果使用过 MySQL 5.7 的企业,肯定都遇到过相似的问题,比如超过 MySQL 的默认闲置时间导致的连接超时、dependent subquery 导致的语句效率差、字符集乱码等等。
以及 MySQL 的自身 Bug,比如 Intel PAUSE 指令周期的迭代引发 MySQL 的性能瓶颈。
毕竟免费的午餐并不是那么完美,总是会有或多或少的问题需要规避。

我这里说下让我痛心疾首的几个心酸坑吧:
坑一:慢 SQL 数量爆发式增长,应用隐患逐步暴露,在阿里等互联网公司和我行都是一个痛点,值得大家警醒和重视。
我行 OLTP 之前为 Oracle 数据库,借助于 Oracle 良好的优化器,大家习惯于 5 张表左右的连接,但是迁移至 MySQL 后,习惯没有及时转换过来,一个慢 SQL 可能就导致服务不可用,降低用户幸福指数。
为此我们规划了三个方面的改善措施:
①设计层面制定了规范,强调数据设计的合理性,组织 DBA 进行内部复核,提前规避设计问题,比如 3NF、BCNF 的设计遵循、可控性冗余处理(空间换时间或时间环空)等等,通过辅助工具的自动化手段,从源头扼杀风险。
②开发层面我们基于 Sonar 开发了自动化检查工具,支持分析 mapper 文件,既然开发人员没空看规范,那我们工具辅助,增加质量门禁,强制将规范融合至开发过程中,进一步降低风险。
但是对新人可能不友好,以前看到一个新人的朋友圈的哭诉,被质量门禁卡的无法提交代码,一直苦逼的加班整改。
③运维层面我们建立了 SRE 平台,监测慢 SQL 语句,并分批次要求整改,将结果都摆在台面上,真的不是我们不给力,而是应用开发不给力啊。
坑二:在 MySQL 5.7 中,表的 TRUNCATE 操作存在 Bug,对应编号 68184,会阻塞整个数据库实例上的所有其他交易。
所以对大表进行 TRUNCATE 操作会影响整个 MySQL 数据库的处理性能,即使是访问不想关的表也会收到影响。
此时你就会收到一群开发人员的请求,哎呀,数据库夯住了,求救啊,实际上解决方案也很简单,因为 Drop 语句不受影响,所以映射为 DROP+CREATE 的操作即可规避该 Bug,而 MySQL 8.0 也将其进行了同样的映射。
所以我们将其固化到设计开发规范中,提醒相关人员进行注意,同时在工具中增加 TRUNCATE 关键字识别检查,做到提前预防。
坑三:MySQL 的超时中断,wait_timeout 参数,即 MySQL 客户端的数据库连接闲置最大时间值(秒),我行设置为 1 小时。
如果长连接的空闲时间超过该参数设置时间,数据库连接就会被 MySQL 主动断开,而中间件的连接池的连接就处于“假活“状态。
一般的建议方法就是增加心跳监测,使用 dbcp 设置 testWhileIdle、validationQuery 等参数,如果跟我行一样使用 WAS 的,在 WAS 控制台上设置时效超时的参数即可。
坑四:Replce Into 引发的自增列主键冲突 Bug,对应编号 73563,主库在执行 replace 操作时,如果有数据冲突,会转换为一笔 delete+一笔 insert。
所以主库无问题,但是 binglog 记录的为 update 操作,备库重做 update 动作,更新主键,但由于 update 动作不会更新自增列值,导致更新后记录值大于自增列值。
当此时发生主备切换时,备库提升为主库,插入的自增列主键会取自增列的值,从而引发主键冲突。
解决方案也属于应急方案,可以在发生问题时,通过 ALTER 语句将自增列增加。
另一种解决方案,可以在 replace into 之后开启一个新的事务,插入一条无意义的记录然后删除掉,可以保证主备一致。
最后一种解决方案,是直接用雪花算法计算递增序列号。
作者:魏亚东
简介:中国工商银行软件开发中心三级经理,资深架构师。杭州研发部数据库专家牵头人和开发中心安全团队成员,负责技术管理、数据库和安全相关工作。2009 年加入中国工商银行软件开发中心,致力于推动管理创新、效能提升,提供全面技术管控,推动自动化实施,实现业务价值的高质量快速交付;同时作为技术专家,为生产安全提供技术支持。
编辑:陶家龙
出处:转载自微信公众号 DBAplus 社群(ID:dbaplus),本文根据魏亚东老师在〖deeplus 直播第 225 期〗线上分享演讲内容整理而成。