













关于变量的命名,这又是一个容易引发程序员论战的话题。如何命名才能更具有可读性、易写性与明义性呢?众说纷纭。
本期“Python为什么”栏目,我们将聚焦于变量命名中的连接方式,来切入这块是非之地,想要回答的问题是——Python 为什么要推荐蛇形命名法?
首先一点,对于单个字符或者单词(例如:a、A、PYTHON、Cat),当它们被用作变量名时,大致有全小写、全大写和首字母大写这几种情况。编程语言中出现这些情况时,它们基本上跟英语的表达习惯是相同的。
但是,编程语言为了令变量名表达出更丰富的含义,通常需要使用多个单词或符号。英语习惯使用空格来间隔开单词,然而这种用法在编程语言中会带来一些麻烦,所以程序员们就创造出了另外的方法:
- 蛇形命名法(snake case)
- 驼峰命名法(camel case)
- 匈牙利命名法(HN case)
- 帕斯卡命名法(Pascal case)
- 脊柱命名法(spinal case)
- 自由命名法(studly caps)
- 驼峰蛇形命名法
总体而言,这些命名法都是要克服单词间的空格,从而把不同单词串连起来,最终达到创造出一种新的“单词”的效果。
我画了一张思维导图,大略区分了这几种命名法:
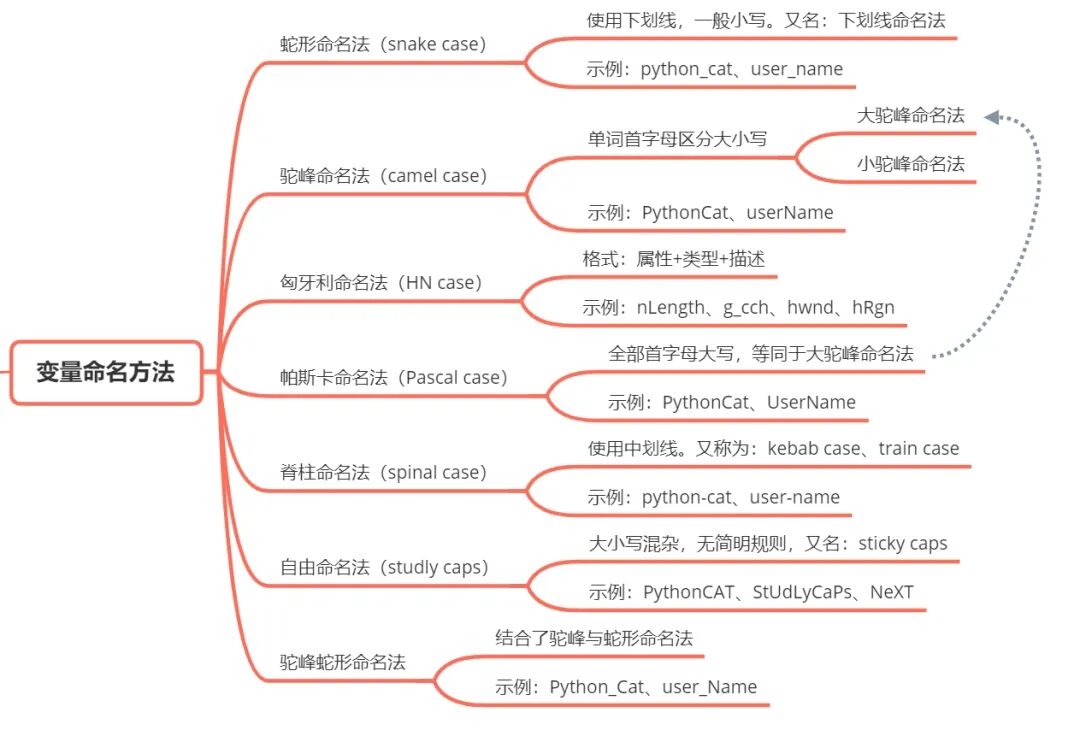
如果按照受众量与知名程度排名,毫无疑问排前两位的是驼峰命名法和蛇形命名法。
我们简单比较一下它们的优缺点:
- 可读性:蛇形命名法用下划线拉大词距,更清楚易读;驼峰命名法的变量名紧凑,节省行宽
- 易写性:驼峰命名法以大小写为区分,不引入额外的标识符;蛇形命名法统一小写,输入相对方便
- 明义性:对于某些缩写成的专有名词,例如HTTP、RGB、DNS等等,一般习惯全用大写表示,但是如果严格遵循这两种命名法的话,须得只留首字母大写或者全小写,这样对原意都会造成一些“破坏”,有时候甚至让人感觉到别扭。如果保留全大写,IDE可能识别不准,反而会出现波浪提示
由此可见,它们各有优缺点,但哪一方都不具有压倒性。我个人稍微偏好于蛇形命名法,但是在需要用驼峰命名的时候(比如写 Java 时),也能无障碍切换。
需要指出的是,Python 也推荐使用驼峰式命名,那是在类名、Type 变量、异常 exception 名这些情况。而在包名、模块名、方法名和普通变量名等情况,则是推荐用蛇形命名(lower_case_with_underscores)。
那么,为什么 Python 会推荐用蛇形命名法呢?
最大的原因是历史原因。蛇形命名方式起源于 1960 年代,那时它甚至还没有特定的名称。Python 从 C 语言中借鉴过来后,给它起名为“lower_case_with_underscores”,即带下划线的小写命名。
直到 21 世纪初的几年,在 Intel 和 Ruby 社区中,才有人开始以“snake_case”即蛇形命名来称呼它。
现今有不少编程语言在某些场景下会推荐使用蛇形命名法,而 Python 则是其中最早这么做的之一,并且是使用场景最多的语言之一。
维基百科上统计了一份清单,可以看出 Python 对它的偏好:

其次,还有一个比较重要的原因,那就是 Python 对下划线“_”的独特偏爱。
比如类似于 _xx、__xx、xx_、__xx__ 等等的写法就随处可见,甚至还有孤零零一个下划线 _ 作为变量的特殊情况。这样看来,下划线作为单词间的连接,恰恰是这种传统习惯的一部分。
最后,我还看到过一种解释:因为 Python 是蟒蛇啊,理所当然是用蛇形命名……
























