【51CTO.com快译】
训练和测试深度学习模型是个困难的过程,需要对机器学习和数据基础架构有深入了解。从特征建模到超参数优化,训练和测试深度学习模型的方法是实际环境下数据科学解决方案面临的最大瓶颈之一。简化这部分有助于简化深度学习技术的采用。虽然深度学习模型的低代码训练是新兴领域,但我们已经看到相关的创新。解决该问题的最完整解决方案之一来自优步AI实验室。Ludwig(https://ludwig-ai.github.io/ludwig-docs/?from=%40)是一种训练和测试机器学习模型的框架,无需编写代码。最近,优步发布了Ludwig的第二版,包括功能上的重要改进,以便为机器学习开发人员提供主流的无代码体验。
Ludwig的目的是使用一种声明式无代码体验,简化训练和测试机器学习模型的过程。训练是深度学习应用最耗费开发人员精力的方面之一。通常,数据科学家花大量时间来试验不同的深度学习模型,以更高的性能处理特定的训练数据集。这个过程不仅涉及训练,还包括其他几个方面,比如模型比较、评估和工作负载分配等。考虑到技术性很强,训练深度学习模型是一项通常仅限于数据科学家和机器学习专家的活动,包含大量代码。虽然该问题对任何机器学习解决方案而言具有普遍性,但在深度学习架构中变得极为严重,因为它们通常涉及许多层和层次。Ludwig使用易于修改和版本控制的声明式模型,将训练和测试机器学习程序的复杂性隐藏了起来。
功能方面,Ludwig这个框架用于简化针对某种场景选择、训练和评估机器学习模型的过程。Ludwig提供了一套模型架构,可以将它们组合在一起,以创建针对一系列特定需求优化的端到端模型。从概念上讲,Ludwig是基于一系列原则设计的:
- 无需编程:Ludwig无需任何机器学习专业知识即可训练模型。
- 通用性:Ludwig可用于许多不同的机器学习场景。
- 灵活性:Ludwig足够灵活,可以供经验丰富的机器学习从业人员和毫无经验的开发人员使用。
- 可扩展性:Ludwig设计时就考虑到可扩展性。每个新版本都包含新功能,无需更改核心模型。
- 可解释性:Ludwig包括可视化元素,可帮助数据科学家了解机器学习模型的性能。
数据科学家使用Ludwig,只需提供含有训练数据的CSV文件以及带有模型输入和输出的YAML文件,即可训练深度学习模型。使用这两个数据点,Ludwig执行多任务学习例程,同时预测所有输出并评估结果。这种简单的结构是支持快速制作原型的关键。Ludwig在底层提供了一系列深度学习模型,这些模型不断加以评估,可以合并到最终的架构中。
Ludwig背后的主要创新基于针对特定数据类型的编码器和解码器这个概念。针对支持的任何一种数据类型,Ludwig使用特定的编码器和解码器。与其他深度学习架构中一样,编码器将原始数据映射到张量(tensor),解码器将张量映射到输出。Ludwig的架构还包括组合器概念:组合器是一种组件,用于组合来自所有输入编码器的张量,对它们处理后,返回供输出解码器使用的张量。
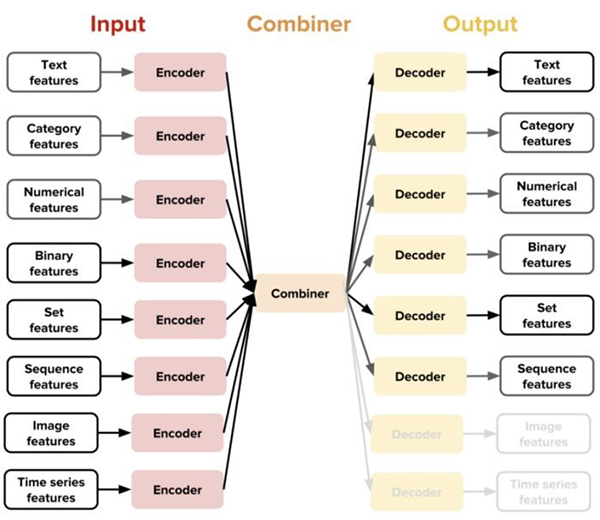
图1
数据科学家将Ludwig用于两种主要的功能:训练和预测。假设我们在处理拥有下列数据集的文本分类场景:
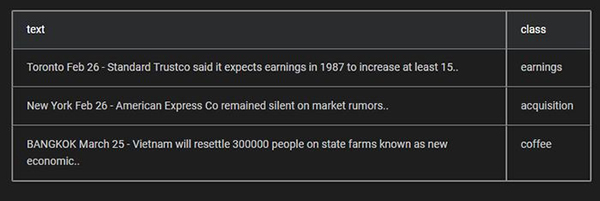
图2
我们可以开始入手Ludwig,只需使用下列命令来安装它:
- pip install ludwig
- python -m spacy download en
下一步是配置模型定义YAML文件,该文件指定了模型的输入和输出特征。
- input_features:
- -
- name: text
- type: text
- encoder: parallel_cnn
- level: wordoutput_features:
- -
- name: class
- type: category
有了这两个输入(训练数据和YAML配置),我们可以使用下列命令训练深度学习模型:
- ludwig experiment \
- --data_csv reuters-allcats.csv \
- --model_definition_file model_definition.yaml
Ludwig提供了一系列可视化元素,可以在训练和预测过程中使用这些元素。比如说,学习曲线可视化元素让我们可以了解模型的训练和测试性能。
图3
训练后,我们可以使用下列命令评估模型的预测:
- ludwig predict --data_csv path/to/data.csv --model_path /path/to/model
其他可视化元素可用于评估模型的性能。

图4
Ludwig的新增功能
最近优步发布了Ludwig的第二版,为核心架构增添了一系列新功能,这些新功能旨在改善训练和测试模型的无代码体验。Ludwig的许多新功能基于与其他机器学习架构或框架集成。以下是一些主要功能:
- 与Comet.ml集成:Comet.ml是市面上用于超参数优化和机器学习试验的最流行平台之一。Ludwig与Comet.ml集成的新功能带来了超参数分析或实时性能评估等功能,而这些功能是数据科学家工具箱的必要组成部分。
- 模型服务:模型服务是机器学习程序生命周期的一个关键部分。Ludwig的新版本提供了API端点,使用简单的REST查询来提供经过训练的模型和查询预测。
- 音频/语音功能:Ludwig 0.2最重要的新增功能之一是支持音频功能。这使数据科学家可以用极少的代码构建音频分析模型。
- BERT编码器:BERT是深度学习历史上最受欢迎的语言模型之一。BERT基于Transformer架构,可以执行许多语言任务,比如问题解答或文本生成。Ludwig现在支持BERT,作为文本分类场景的原生构建模块。
- H3功能:H3是非常流行的空间索引,用于将位置编码成64位整数。Ludwig 0.2直接支持H3,允许使用空间数据集实施机器学习模型。
Ludwig的其他新增功能包括可视化API方面的改进、新的日期功能、为文本标识化更好地支持非英语语言以及更好的数据预处理功能。尤其是数据注入似乎是下一Ludwig版本重点关注的方面。
Ludwig仍是一种比较新的框架,仍需要大量改进。然而,支持低代码模型是一个关键的构建模块,可以方便更广泛的开发人员采用机器学习。此外,Ludwig抽象并简化了市面上一些主流机器学习框架的使用。
原文标题:Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning,作者:Jesus Rodriguez
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】