【51CTO.com原创稿件】
1.导读:
如今,人工智能研究日益火热,机器学习技术也得到了迅速发展。而作为机器感知的研究热点,图像人群计数有着广泛的应用,如视频安全监控、C监控、图像识别和城市规划等。随着国家城镇化的不断推进,城市人群密集场景越来越多,继而带来的恐怖事件、踩踏事件也日益增多。所以如何实现精准的图像人群计数是一个至关重要的任务。但是,由于在监控时,计数收到场景内和场景间变化视角的干扰、图像受到闭塞、透视扭曲和缩放等问题,使得人群计数任务依旧具有很大的挑战性。如何设计一个准确、稳健的人群计数方法,是过去研究人员一直讨论的话题。
2.人群计数现状
近年来,深度学习技术和丰富特征融合技术显著提高了视觉目标识别的检测精准度。而神经网络在目前深度学习中最为流行,它是一种动物神经网络行为特征,进行分布式并行信息处理的算法数学模型,通过调节内部大量节点之间相互连接的关系,从而达到处理信息的目的。在人工神经网络中,卷积算法是运用最多的,运用卷积神经网络来处理图像数据可以更好的提高检测的准确性。
众所周知,学习丰富的特征对人群计数是至关重要的。然而,现有的基于神经网络的方法只使用了从最后的卷积层提取的CNN 特征,忽略了CNN 特征中包含的有用的分层信息。在本文中,提出一个基于全卷积网络的 CNN 结构,它通过结合一些有用的卷积特征来建立端到端之间密度图估计系统。利用这种组合可以有效地捕获复杂场景中的多尺度和多层次信息。
对于如图1所示的稀疏人群图像,我们可以用肉眼很直观的看出人数。而对于如图2所示的密集人群图像,由于很多人群之间存在遮挡情况,我们则无法通过肉眼轻易给出人数。所以我们不得不借助计算机去完成这项任务。解决这种问题的传统技术是手动设计并标注各种特征,基于提取的特征来训练出基于回归的线性或非线性的函数来统计人数。
图1:稀疏人群
图2:密集人群
3.传统的人群计数方法:
传统的人群计数算法大致可以分为以下几类: 基于检测的方法[1,2],基于回归的方法[3,4]和基于密度估计的方法[5]:
(1)基于检测的方法简单明了,仅适用于稀疏场景。这些方法的前提是可以找到场景中的每个实体。一般的工作流程是利用零件检测器对目标场景中的人进行一个接一个的检测,然后计算人数。然而,这些方法相对来说是不灵活的,需要昂贵的计算成本。此外,他们遭受严重的闭塞或高密度人群的存在,这大大降低了检测器的性能,从而导致计数系统的精度低甚至失败。
(2)基于回归的计数方法广泛地用于克服复杂场景中探测器设计的困难。这些方法的目的是了解低级功能与框架或框架区域中的人员数量之间的映射。基于回归的方法侧重于利用全局图像特征捕捉探测场景的全局属性。利用边缘、梯度和纹理等多种手工艺特征来刻画图像的低级特征。通过建立群体数与人群密度图之间的回归模型,就可以很容易地获得总体计数结果。
(3)基于密度估计的方法旨在学习局部块特征与其对应的人群密度图之间的线性映射。与基于回归和基于检测的方法不同的是,基于密度估计的方法在学习过程中将空间信息也纳入进去了,通过在所得到的密度图中的任何区域上积分都可以估计人群数。
20世纪80年代以来,深度学习提供精确识别和预测能力一直在提高,随着近几年来深度学习的飞速发展,进行人群计数的主要方法主要是采用深度学习,尤其具有代表性的是利用卷积神经网络来自动提取图像中人群密度特征从而估算不同场景的人数。卷积神经网络已成为在各种计算机视觉任务中最受欢迎的技术,大量的CNN的方法已经被提出来用于人群计数,如 MCNN[6],FCN[7],MSCNN[8]等。为更准确的进行人群计数检测,我们不得不采用深度学习技术,通过深度学习的神经网络算法模型来进行图像人群计数。文献[8]提出了一种具有全卷积网络结构的深度神经网络,并在一些数据集上实现最新的结果,也可以被看作为 MCNN 的延伸。尽管之前已经有人探索了全卷积网路的结构,解决了因图像缩减和变形而造成的视觉失真等问题。但是,这种全卷积网络结构还是不能很好地处理尺度变化,并且只有最终的卷积层才能用于估计人群数。为了解决这些问题,我们提出了新的全卷积模型的人群计数,精准地利用不同尺度的特征将其中几个CNN层组合在一起。
4.深度学习神经网络,人群计数的福音?
很多人可能会认为深度学习是一门新技术,并会对这个新兴领域感到陌生和惊讶。事实上,深度学习的历史可以追溯到20世纪40年代左右。一般认为,迄今为止深度学习已经经历了3次发展浪潮:20世纪40年代到60年代,深度学习的雏形出现在控制论中,20世纪80年代到90年代,深度学习表现为联结主义;知道2006年,才真正以深度学习之名复兴,也称为人工神经网络
4.1感知器
感知器,也是最简单的神经网络(只有一层),由美国计算机科学家Roseblatt 于1957 年提出的。它只有一个神经元,感知器也可以看出是线性分类器的一个经典学习算法。结构如图所示:
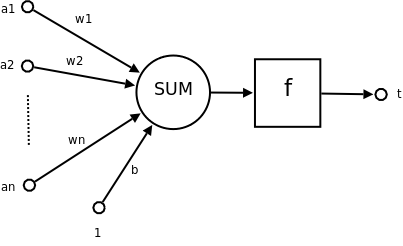
感知器结构
类似wx + b的形式,其中a1…an为输入向量,w1…wn为权重,b为偏置,f为激活函数,t为输出。W 和b是未知的,需从给定的训练集中学习得到。
4.2神经网络
神经网络即人工神经网络的简称,将单个的感知器模拟成神经元而形成的网络结构。它的构筑理念是受到生物神经网络功能的运作启发而产生的。人工神经网络模型主要考虑网络连接的拓扑结构、神经元的特征、学习规则等。目前,已经有40种神经网络模型[9],其中有反传网络、感知器、自组织映射、Hopfield网络、玻尔兹曼机等。根据连接的拓扑结构,神经网络模型可以分为前向网络和反馈网络。
4.3前向网络
前向网络中各个神经元接受前一级的输入,并输入到下一级,网络中没有反馈。这种网络实现信号从输入空间到输出空间的变换,它的信息处理能力来自于简单非线性函数的多次复合,网络中可以有多个隐藏层,每个神经元都有若干个输入,但是只有一个输出。
反馈网络内神经元间有反馈,可以用一个无向的完备图表示。这种神经网络的信息处理是状态的变换。系统的稳定性与联想记忆功能有密切关系。
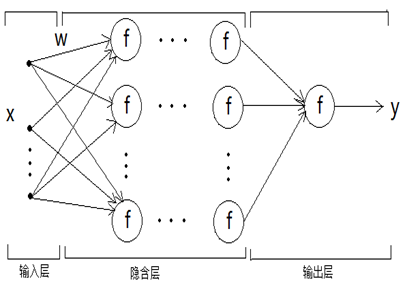
前向神经网络结构
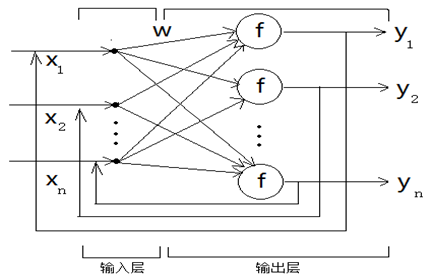
反馈神经网络结构
5.基于卷积特征融合的人群计数
很多文献都已经讨论了有关深度神经网络的不同卷积层所包含的信息。总体上,卷积特征中间层包含了丰富的细节,但随着层数的增加而变得粗糙。对于应对规模变化和背景杂波等挑战,尽管这种方法比手动设计的特征更具有鉴别力。但是也促使我们去考虑CNN 的功能在文献[5]和文献[7]中是否得到充分的利用,是否只有最终的卷积层被用来估计人群数量,学习更多的辨别特征仍然是人群计数中的一个开放性问题。本文试图将 CNN 的功能从最终和中级两层结合起来,以获得更好的代表性。
5.1网络结构
为了加强特征鉴别,结合了多个卷积层的思想进行了研究。多列 CNN 的最终卷积层,即几个具有相同结构和不同过滤器大小的 CNN,被合并以产生最终的特征图。融合过程增强了CNN 功能的多尺度代表能力。但是,主要的缺点是每个单列需要单独训练,从而导致训练时间非常长。此外,微调整个网络仍然是一项艰巨的任务。在文献[11]中,采用了一种不同的多尺度特征策略用于边缘检测任务。提出的网络结构使用了所有卷积层的CNN功能,目的是为不同尺度的物体获得准确的表示。由于只有一个CNN需要培训,培训成本比文献[6]中方法更有效。
基于FCN 网络,考虑到上述所有元素,结合不同的卷积层,以产生分层的 CNN 功能来进行人群计数。根据实证研究发现使用多尺度特征的最佳方法是融合最后三卷积层所产生的特征图。所以使用的网络各卷积层结构如图7所示,网络的激活函数采用修正线性单元(Relu)函数,不同的颜色代表不同种类的层,包括6个卷积层、2个最大池层和 1 concat函数融合层。除了卷积6,每个卷积层后跟一个整流线性单元 (ReLU)。用一个1*1滤波器的卷积层代替了完全连接的层,因此模型的网络输入图像可以是任意大小的,直接输出的是一个人群密度估计图,从而得到整体计数。
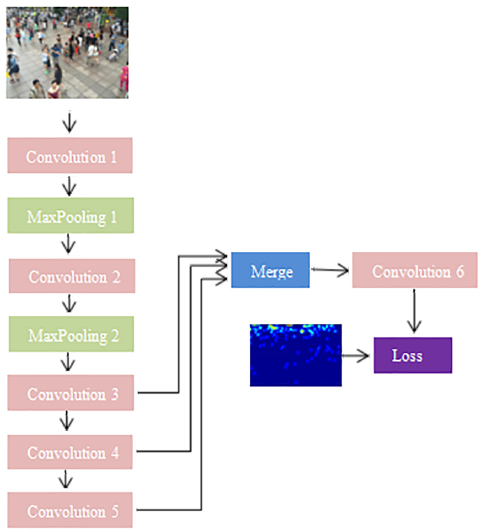
图7:CNN丰富的卷积特征融合人群计数结构
5.2评价指标
根据文献[6],我们采用人群计数方面普遍使用的平均绝对误差(MAE)和均方误差(MSE),对预测的结果进行评价,其中平均绝对误差反映了预测的准确性,均方误差反应了预测的鲁棒性,二者详细定义如下:
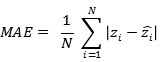
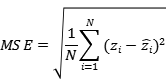
式中: 为图像中的实际人数; 为预测得到的人数; 为测试图像的数量。
5.3数据集
ShanghaiTech是一个开放场景人群数据集,一共有标注了330165个人的1198张图片。ShanghaiTech数据集包括两个部分,分别为Part A和Part B,每一部分都分好了train和test。其中Part A 来自互联网抓拍图片,其中300张图像用于训练,其余182图像用于测试。这些图像的分辨率不同,最大值为1024x1024。为了方便起见,我们将所有图像的分辨率调整为相同大小的1024x1024。Part B来自上海街头的监控视频帧,一共有716个图像,其中400个图像用于训练,其余316个图像用于测试,所有图像的分辨率都是1024x768。对比不同人群计数方法在两个数据集上的实验结果如表所示:
不同人群计数方法在ShanghaiTech数据集上的性能比较
|
方法 |
Part_A |
Part_B |
||
|
|
MAE |
MSE |
MAE |
MSE |
|
(Zhang et al. ,2016[6]) |
110. 3 |
171. 2 |
26. 3 |
41. 4 |
|
(FCN. ,2016[7]) |
128. 4 |
176. 5 |
24. 74 |
37. 15 |
|
(Zhang et al. ,2015[12]) |
181. 5 |
227. 4 |
32. 1 |
48. 4 |
|
本文提出的方法 |
111. 2 |
167. 7 |
21. 84 |
33. 35 |
由表可以得到,本文方法在ShanghaiTech A部分的数据集上优于 FCN方法[7],在MAE上性能提高和MSE上性能均有所提高。同时,在ShanghaiTech B部分数据集上对比FCN,MAE性能也有所提高。
UCF CC 50数据集由从网上收集的50张图像组成,该数据集包含从94到4543的头部注释,每个图像平均有1280个个体。按照文献[10]中的标准设置,我们将数据集分成五个统一的部分,其中每个都包含10个图像。就MAE而言,该方法表现最好,该方法的性能也非常接近最佳结果。
不同人群计数方法在UCF-CC 50数据集上的性能比较
|
方法 |
MAE |
MSE |
|
(Zhang et al. ,2016[6]) |
376. 6 |
504.1 |
|
(FCN. ,2016[7]) |
348. 4 |
425. 5 |
|
(Zhang et al. ,2015[12]) |
466. 0 |
497. 5 |
|
本文提出的方法 |
321. 9 |
427.2 |
6. 总结
在提出的方法中,除了一些高度拥挤的场景外,估计数大多数情况下都接近真实计数。推测这种估计误差可能是由于缺乏数据密集型场景中的训练图像造成的。这也说明深度学习技术未来在这一领域仍旧还有很长的路要走,同时在计数方面需要更加注重来进一步提高技术精度,同时来提高实时性能,从而使计数系统更有可能扩展到实际应用中。
参考文献
[1] W. Ge and R. T. Collins. Marked point processes for crowd counting[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2009: 2913–2920.
[2] M. Li, Z. Zhang, K. Huang, and T. Tan. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection[C]// international conference on pattern recognition, 2008: 1–4.
[3] A. B. Chan and N. Vasconcelos. Bayesian poisson regession for crowd counting[C]// IEEE International Conference on Computer Vision, 2009: 545–551.
[4] K. Chen, C. L. Chen, S. Gong, and T. Xiang. Feature mining for localised crowd counting[C]// British Machine Vision Conference, 2013: 1–11.
[5] V. Lempitsky and A. Zisserman. Learning to count objects in images[C]// International Conference on Neural Information Processing Systems, 2010: 1324–1332.
[6] Y. Zhang, D. Zhou, S. Chen, S. Gao, and Y. Ma. Single-image crowd counting via multi-column convolutional neural network[C]// IEEE Conference on Computer Vision and Pattern Recognition,2016: 589–597.
[7] M. Marsden, K. Mcguinness, S. Little, and N. E. Connor. Fully convolutional crowd counting on highly congested scenes [EB/OL] 2016, arXiv:1612.00220.
[8] L. Zeng,X. Xu, B. Cai, S. Qiu, and T. Zhang. Multi-scale convolutional neural networks for crowd counting [EB/OL] 2017, arXiv:1702.02359.
[9]赵申剑, 符天凡等译. 深度学习[M]. 北京:人民邮电出版社, 2007. 8.
[10]J. D. Cowan. Discussion:McCulloch-Pitts and related neural nets from 1943 to 1989[C]// Bulletin of Mathematical Biology, 1990: 73-97.
[11] M. D. Zeiler and R. Fergus. Visualizing and Understanding Convolutional Networks[C]// European Conference on Computer Vision, 2014: 818–833.
[12] C. Zhang, H. Li, X. Wang, and X. Yang. Cross-scene crowd counting via deep convolutional neural networks[C]// Computer Vision and Pattern Recognition, 2015: 833–841.
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】