新兴的编程语言中,Rust以高性能、内存安全为卖点在编程世界里广受好评。除了比较繁琐的语法,难于理解的变量所有权和生命周期,入门门槛比较高以外基本上没有其他的缺点了。现在处于编程语言百家争鸣的时代,如何选择合适的语言以及在合理时间解决问题成了一门学问。本文我们介绍一个案例为了解决瓶颈将将服务从Node.js迁移到Rust从而解决实际问题节省生产成本。过程中深入探讨了导致需要更改语言的一些细节,以及该过程中如何决策的,希望能给予大家一些启发。
概述
案例涉及的是一个企业的业务监控系统,该系统用来以帮助开发人员监控业务API。当客户的应用程序调用API时,会向系统发送日志,系统对发送的日志中进行监控和分析。
系统数据流为平均每分钟处理30k 的API调用。每个客户都会进行很多个API的调用。系统的处理分为两个关键部分:日志提取和日志处理。
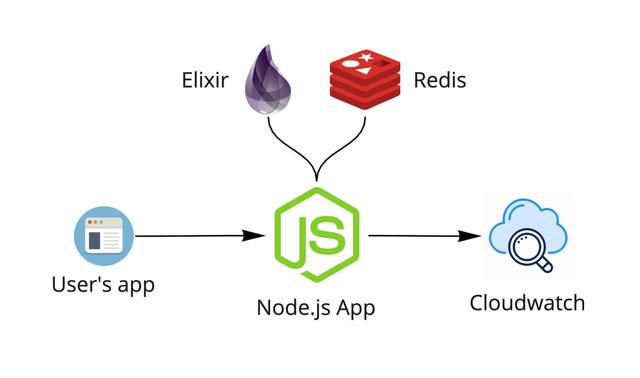
起初的系统中是通过Node.js构建提取服务。Node.js接收日志,与elixir服务进行通信检查用户的访问权限,用Redis检查速率限制,然后将日志发送到CloudWatch。CloudWatch部署了触发器,触发事件通知数据处理程序处理。
系统提取有关API调用的信息,包括从用户应用程序发送的每个调用的有效负载(请求和响应)。这些文件的大小被限制为1MB,但是仍然涉及大量的数据需要处理。处理程序以异步的形式发送和处理所有内容,目标是使信息尽快提供给最终用户。
所有内容都托管在亚马逊云AWS Fargate上,并对其设置为在4000 req/min阈值触发自动缩放。
整个流程都运行的很好,但是费用却非常昂贵。由于AWS是按照CloudWatch存储的使用来收费的,存储的越多,需要支付的费用就越多。
为了解决费用的问题,于是就有一个救援计划。
Kinesis救援和灾难
为了解决昂贵的CloudWatch存储费用问题,在将日志传送到CloudWatch之前,使用了Kinesis Firehose前置处理。Kinesis Firehose可能熟悉少,但是知道kafka的人可能多,那么Kinesis Firehose就是AWS云中的Kafka。使用Kinesis Firehose前置处理,可以用可靠的方式将数据流传递到多个目的地。只需对日志处理程序进行很少的更新,就可以从CloudWatch和Kinesis Firehose提取日志。通过该架构的更改,可以将日成本下降到之前的千分之六。
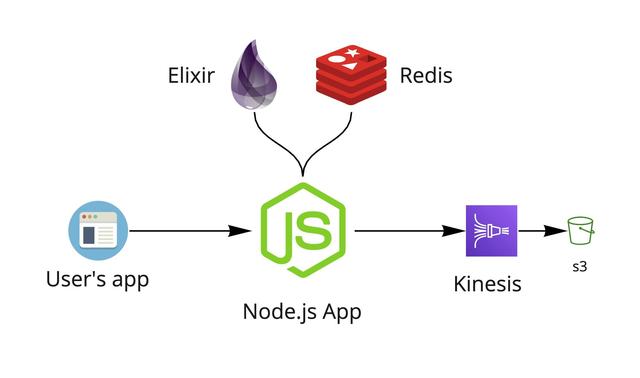
新架构中系统将日志数据通过Kinesis传递到s3中,从而触发日志处理程序。新架构运行后,一切都ok。但是过几天出现了异常。。。监控仪表板上的一些异常情况。系统在收集垃圾,很多垃圾!
垃圾回收(GC)是某些编程语言自动释放不再使用内存的一种方式。发生这种情况时,程序将会暂停。这称为GC暂停。对内存进行的写操作越多,需要进行的垃圾回收就越多,因此暂停时间会增加。对于系统服务,这些暂停的速度越来越快,足以导致服务器重新启动并给CPU造成压力。发生这种情况时,它看起来就像是服务器已关闭(因为它暂时处于关闭状态),并且在客户端会有大量的5xx错误,而代理所尝试提取的日志中大约有6%出现了这个错误。
下面图显示了垃圾回收的暂停时间和暂停频率:
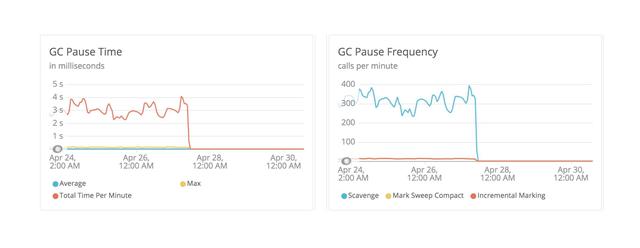
在某些情况下,暂停时间超过了4秒(如左图所示),并且每分钟最多有400次暂停(如右图所示)。
经过更多研究分析后,似乎成为AWS Javascript SDK中内存泄漏的导致的该问题的发生。尝试将资源分配增加到极限,例如减小缩放阈值到1000 req/min自动缩放,但是没有问题仍没有解决。
可能的解决方案
由于不能能使用上面的kninesis方案,因此需要新的解决方案来解决问题。可选的方案有以下几种。
Elixir
如前的架构介绍,系统使用Elixir服务检查客户访问权限。该服务是私有的,只能从虚拟私有云(VPC)中访问。由于从未遇到过该服务的任何可扩展性问题,并且大多数逻辑已经存在。所以可选择简单地从该服务中将日志发送到Kinesis,而跳过Node.js服务层。这是一个值得尝试的方案。
做了一番改进后,系统进行了测试。效果会好一点,但仍然不是很佳。系统的基准测试表明,GC垃圾收集的水平仍然很高,并且在使用日志时仍会有5xx的日志返回给用户。
Golang
系统也考虑到Golang。这是一个很好的选择方案,但是,毕竟Golang也是一种垃圾收集语言。虽然可能可以实现比上述更高效,但随着规模的扩展,很可能还会遇到类似的问题。考虑到这些限制,系统需要一个更好的选择。
以Rust为核心进行重新架构
在系统最初的实现和备份中,核心问题都是相同的:垃圾回收。解决方案是使用一种具有内存管理更好的并且没有垃圾回收的语言。那么可选择的语言就到了Rust。
Rust
Rust不是垃圾收集的语言。Rust依赖于称为变量生命周期和所有权的概念。所有权是Rust的最独特功能,它使Rust无需垃圾收集器即可保证内存安全。
所有权是一个经常使Rust难以学习和编写的概念,但又使它非常适合像这个项目遇到的情况。Rust中的每个值都有一个所有者变量,因此在内存中有一个分配点。一旦该变量超出范围,内存将会立即释放。
由于提取日志所需的代码很小,应该非常值得尝试。为了对此进行测试,通过问题的瓶颈:向Kinesis发送大量数据。第一个基准测试非常成功。
所以Rust最终成了救世主,最后决定将原型充实并在生产系统的部署。
在这些实验过程中,并没有直接使用Rust直接替换原始的Node.js服务,而是重构了日志提取的大部分架构。新服务的核心是通过Envoy代理,在其中Rust应用程序作为辅助工具。
新架构流程
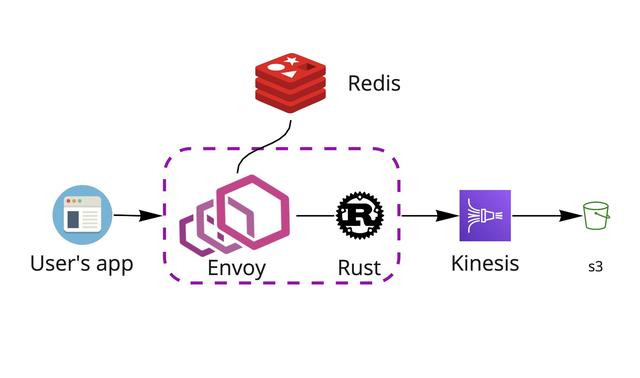
当用户应用程序中Agent将日志数据发送到系统时,它将首先进入Envoy代理。Envoy查看请求并与Redis通信以检查速率限制,授权详细信息和使用配额之类的内容。接下来,与Envoy一起运行的Rust应用程序准备日志数据,并将其通过Kinesis传递到s3存储桶中进行存储。然后,S3触发日志处理程序处理,Elastic Search开始对其进行索引。这样,最终用户就可以访问仪表板中的数据。
性能和资源对比
新架构中使用了更少(更小)的服务器,但是可以处理更多数据,而不会出现任何之前的gc 5xx问题。
对比新旧架构的服务延迟。在旧的Node.js架构下服务的延迟数如下图,可以看到平均响应时间接近1700ms的峰值:
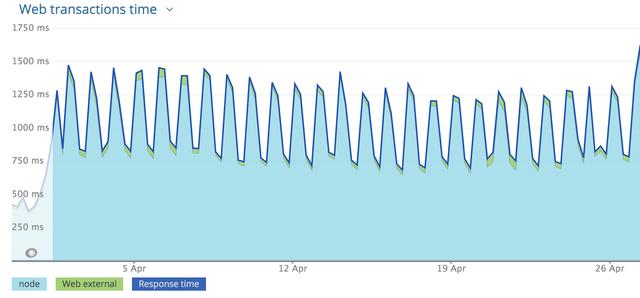
通过Rust服务的实施,新架构中,即使在最高峰期间,延迟也降至90ms以下,平均响应时间保持在40ms以下。
旧架构下Node.js应用程序在任何给定时间都会使用约1.5GB的内存,CPU的负载约为150%。
新架构下Rust服务使用了大约100MB的内存,而仅占用了2.5%的CPU负载。
结论
大多数初创公司都一样,会遭遇业务迸发的阶段。这时候当初最好的解决方案并非永远都不再是最好的解决方案了。
该案例中的Node.js的架构就是这种情况。它使企业能够前进,但是随着业务的飞速成长,最终业务超过了它。这时简单的资源缩放会带来昂贵的不可接受的成本。这时候就需要优化基础架构,以满足新的需求。本案例中,虽然仅用Rust替换Node.js就完成了架构的升级和优化,并完美解决了业务瓶颈。