













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
疫情当下,Waymo等自动驾驶厂商暂时不能在现实世界的公共道路上进行训练、测试了。
不过,工程师们还可以在GTA(划掉),啊不,在仿真环境里接着跑车。

模拟环境里的场景、对象、传感器反馈通常是用虚幻引擎或者Unity这样的游戏引擎来创建的。
为了实现逼真的激光雷达等传感器建模,就需要大量的手动操作,想要获得足够多、足够复杂的数据,可得多费不少功夫。
数据不够,无人车标杆Waymo决定用GAN来凑。
这只GAN,名叫SurfelGAN,能基于无人车收集到的有限的激光雷达和摄像头数据,生成逼真的相机图像。
用GAN生成的数据训练,还是训练自动驾驶汽车,这到底靠谱不靠谱?
SurfelGAN
那么首先,一起来看看SurfelGAN是怎样炼成的。
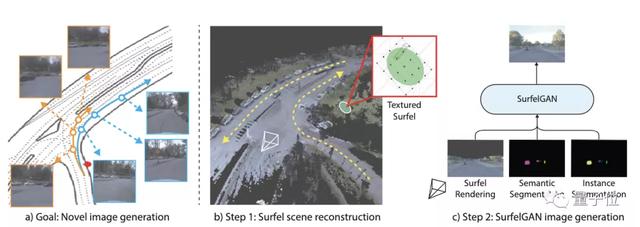
主要有两个步骤:
首先,扫描目标环境,重建一个由大量有纹理的表面元素(Surfel)构成的场景。
然后,用相机轨迹对表面元素进行渲染,同时进行语义和实例分割。接着,通过GAN生成逼真的相机图像。
表面元素场景重建
为了忠实保留传感器信息,同时在计算和存储方面保持高效,研究人员提出了纹理增强表面元素地图表示方法。
表面元素(surface element,缩写Surfel)适用于动态几何建模,一个对象由一组密集的点或带有光照信息的面元来表示。
研究人员将激光雷达扫描捕获的体素,转换为具有颜色的表面元素,并使其离散成 k×k 的网格。
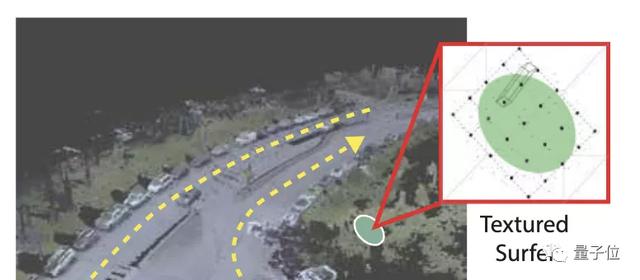
由于光照条件的不同和相机相对姿势(距离和视角)的变化,每个表面元素在不同的帧中可能会有不同的外观,研究人员提出,通过创建一个由 n 个不同距离的 k×k 网格组成的编码簿,来增强表面元素表示。
在渲染阶段,该方法根据相机姿势来决定使用哪一个 k×k 块。

图中第二行,即为该方法的最终渲染效果。可以看到,与第一行基线方法相比,纹理增强表面元素图消除了很多伪影,更接近于第三行中的真实图像。
为了处理诸如车辆之类的动态对象,SurfelGAN还采用了Waymo开放数据集中的注释。来自目标对象的激光雷达扫描的数据会被积累下来,这样,在模拟环境中,就可以在任意位置完成车辆、行人的重建。
通过SurfelGAN合成图像
完成上面的步骤,模拟场景仍存在几何形状和纹理不完美的问题。
这时候,GAN模块就上场了。
训练设置了两个对称的编码-解码生成器,从Sufel图像到真实图像的GS→I,以及反过来从真实图像到Sufel图像的GI→S。同样也有两个判别器,分别针对Sufel域和真实域。
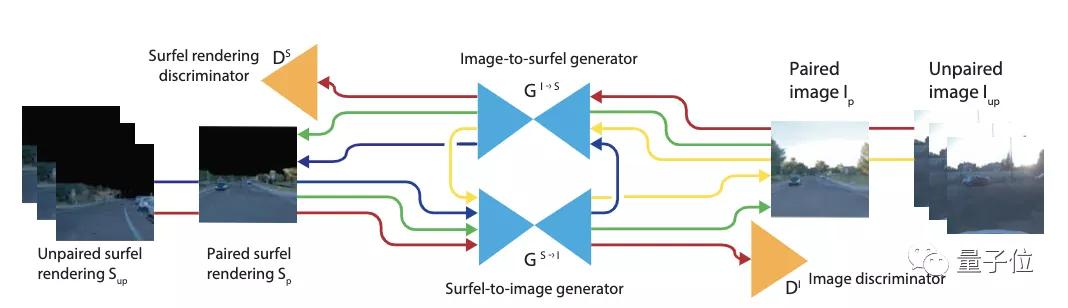
上图中,绿色的线代表有监督重建损失,红色的线代表对抗损失,蓝线/黄线为周期一致性损失。
输入数据包括配对数据和未配对数据。其中,未配对数据用来实现两个目的:
- 提高判别器的泛化性能;
- 通过强制循环一致性来规范生成器。
另外,由于表面元素图像的覆盖范围有限,渲染出的图像中包含了大面积的未知区域,并且,相机和表面元素之间的距离也引入了另一个不确定因素,研究人员采用了距离加权损失来稳定GAN的训练。
具体而言,在数据预处理过程中,先生成一个距离图,然后利用距离信息作为加权稀疏,对重构损失进行调节。
实验结果
最后,效果如何,还是要看看实验结果。
研究人员们基于Waymo Open Dataset(WOD)进行了实验。该数据集包括798个训练序列,和202个验证序列。每个序列包含20秒的摄像头数据和激光雷达数据。此外,还包括WOD中真的对车辆、行人的注释。
他们还从WOD中衍生出了一个新的数据集——Waymo Open Dataset-Novel View。在这个数据集中,根据相机扰动姿势,研究人员为原始数据集里的每一帧创建了新的表面元素渲染。
此外,还有9800个100帧短序列,用于真实图像的无配对训练。以及双摄像头-姿势数据集(DCP),用于测试模型的真实性。

可以看到,在检测器的鉴定下,SurfelGAN生成的最高质量图像将AP@50从52.1%拉升到了62.0%,与真实图像的61.9%持平。

Waymo认为,这样的结果为将来的动态对象建模和视频生成模拟系统奠定了坚实的基础。
华人一作
论文的第一作者,是Waymo的华人实习生Zhenpei Yang,他于2019年6月至8月间在Waymo完成了这项研究。
Zhenpei Yang本科毕业于清华大学自动化系,目前在德州大学奥斯汀分校攻读博士,研究方向是3D视觉和深度学习。
Waymo首席科学家Dragomir Anguelov,也是论文的作者之一。
























