本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
BERT、GPT-2、XLNet等通用语言模型已经展现了强大的威力,它们可以应付各类任务,比如文本生成、问答。当这些模型对各种语言任务进行微调时,可以达到SOTA性能。
以上这些NLP模型都是“通才”,虽然全面,但在面向特定任务时需要微调,训练数据集也十分庞大,非一般人所能承受。
如果开发一个非通用NLP模型,专门针对某项具体任务,在降低训练成本的同时,性能会不会提高呢?
这就是谷歌发布的“天马”(PEGASUS)模型,它专门为机器生成摘要而生,刷新了该领域的SOTA成绩,并被ICML 2020收录。
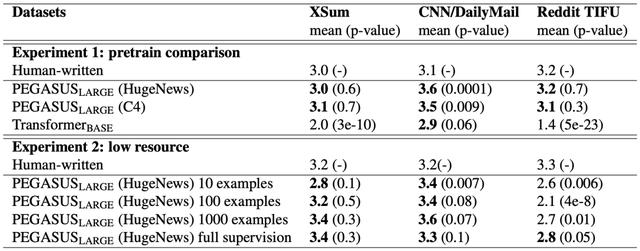
“天马”模型仅使用1000个样本进行训练,就能接近人类摘要的水平,大大减少了对监督数据的需求,创造了低成本使用的可能性。
从填空到生成摘要
PEGASUS的全称是:利用提取的间隙句进行摘要概括的预训练模型(Pre-training with Extracted Gap-sentences for Abstractive Summarization)。就是设计一种间隙句生成的自监督预训练目标,来改进生成摘要的微调性能。
在之前的NLP研究中,自监督预训练对下游的目标并不清楚,可能是文本生成、也可能是摘要提取,模型倾向于通用性。
而来自谷歌的研究者认为,自监督预训练目标越接近最终的下游任务,微调性能越好。
那论文标题中的间隙句(Gap-sentences)又是什么意思?
在“天马”模型的预训练中,研究者从一段文档中删掉一些句子,让模型进行恢复任务。这些隔空删掉的句子即为间隙句。
这样一项具有挑战性的任务促使模型学习发现一般事实的能力,以及学习如何提取从整个文档中获取的信息。
谷歌发现,选择“重要”句子去遮挡效果最好,这会使自监督样本的输出与摘要更加相似。
作者选择了12个不同数据集,内容丰富多样,包括新闻、科学论文、专利文件、短篇小说、电子邮件、法律文件和使用说明,表明该模型框架适用于各种主题。
与谷歌之前提出的T5对比,参数数量仅为T5的5%。
谷歌根据ROUGE标准对输出结果进行评判,通过查找与文档其余部分最相似的句子来自动识别这些句子。
ROUGE使用n元语法重叠来计算两个文本的相似度,分数从0到100。
1000个训练样本即超过人类
尽管PEGASUS在大型数据集上表现出了卓越的性能,但令人惊讶的是,“天马”模型并不需要大量的样本来进行微调,就可以达到近乎SOTA的性能。
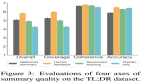
下图展示了在四个选定的摘要数据集中,ROUGE得分与监督样本数量的关系。虚线表示具有全监督但没有预训练的Transformer编码器-解码器的性能。
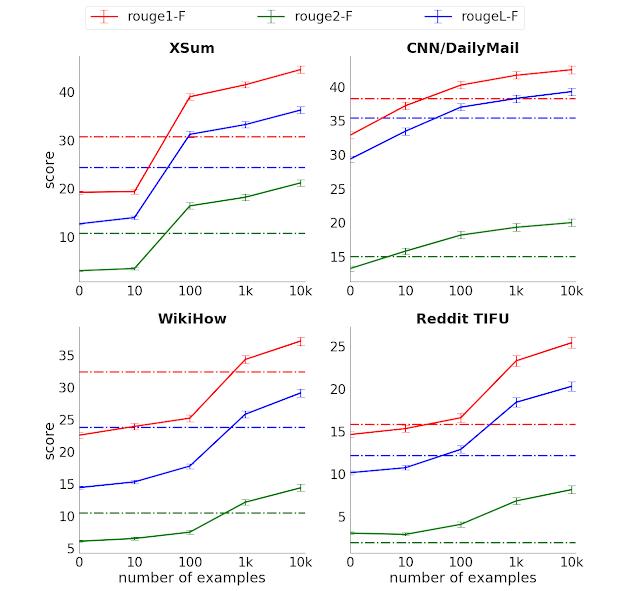
与基线相比,即使仅用1000个微调样本,“天马”在大多数任务中的性能还是要好一些。要考虑到,在某些实际情况下,样本数量还要多几个数量级。
这种“样本效率”极大地提高了文本摘要模型的实用性,因为它大大降低了监督数据收集的规模和成本。
除了机器给出的ROUGE评分外,谷歌还进行了一项鉴别摘要的“图灵测试”。
谷歌将模型生成的摘要和人类提取的摘要放在一起,给用户进行评估。在3个不同数据集上进行的实验表明,打分的人有时会更喜欢机器生成的摘要。

当然,“天马”模型并非没有缺点,谷歌就找到了一个bug。
作者从XSum数据集中寻找了一段话,其中提到了英国4艘护卫舰的名字,通篇没有提到4,“天马”还是正确提取出了护卫舰数量信息。
军舰的数量从2~5的时候都没有问题,当数量增加到6时,“天马”错误地认为有7艘。这说明模型“符号推理”的数量有限。
最后,为了支持该持续研究并确保可重复性,谷歌在GitHub上发布了“天马”的代码、模型checkpoint以及其他汇总数据集。
传送门
博客地址:
https://ai.googleblog.com/2020/06/pegasus-state-of-art-model-for.html
论文地址:
https://arxiv.org/abs/1912.08777
代码地址:
https://github.com/google-research/pegasus