













本文转载自微信公众号「 写PHP的老王」,转载本文请联系 写PHP的老王公众号。
业务需求痛点
- 业务增长,查询条件越来越多,索引越来越多
业务发展初期,数据量不多。查询,写入都很快。随着业务的发展,数据量增大,出现慢查询,开始往表里不断的加索引,保证数据查询效率。但是当数据量继续增大,业务查询越来越复杂。程序员天天想着这个表怎么加索引。索引的增加,写入数据的时间成本越来越高。
- 表数据增加,数据拆分越来越复杂
数据量增大,开始进行分表处理。慢慢的发现,尼玛,分的表越来越多。再这么下去,这台数据库服务器上都容不下他了,这是要做数据分片的操作啊。分表已经够费劲了,还要分片?
- 全文检索功能
嗨,哥们,给我加个全文搜索的功能。简单的一句话,你心里十万个草泥马。这么多的数据量你让我搞全文搜索。
上面业务通点总结起来就是要查的快,要分布式,要全文搜。
ES 能解决什么问题
S主要运用于全文搜索、数据分析, 底层使用开源库Lucene,拥有丰富的REST API。内部分布式的数据存储、倒排索引等设计,使其可以快速存储、搜索、分析海量数据。典型的使用方和应用场景,如github,StackOverflow,elasticsearch+logstash+kibana 一体化的日志分析。
ES 搜索为什么快的原因
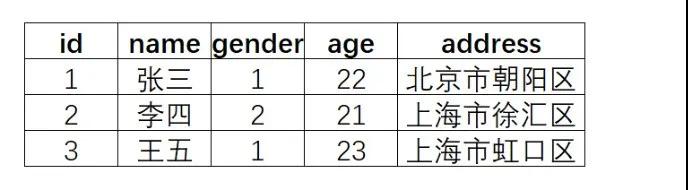
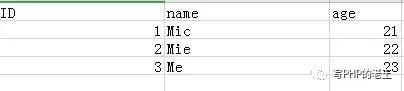
对于mysql中如上的数据表,ES会对每个字段的值建立索引,通过索引的值去找数据,而且这些索引都是在内存里面的。
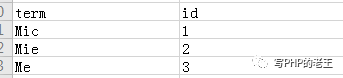
name段索引:
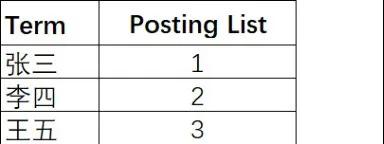
age字段索引
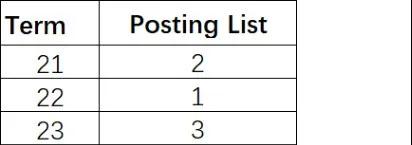
address 字段索引
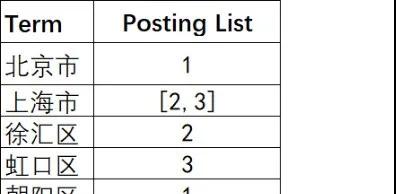
这样,当我们要找上海市,年龄为21岁的数据就能够通过address,age索引快递定位到数据id=2的是我们需要查找的。
然后在从磁盘中把数据id=2的数据读取出来。
上面的其实就是ES中倒排索引的一个简化版本。
实际上的ES的倒排序使用的是前缀作为索引,同时会使用*FST*对索引数据进行压缩,以保证在内存的数据量不会因为索引多而带来比较大的内存消耗。
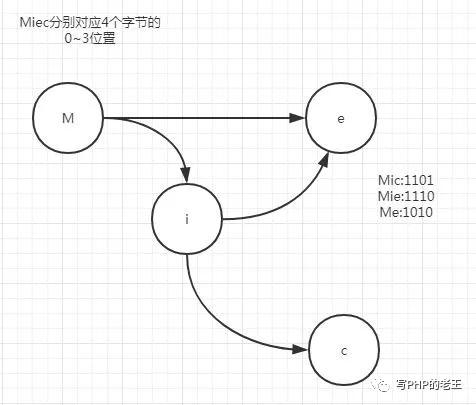
对于上面的数据表,如果采用HashMap的方式对name字段索引的话,索引所占用内存20个字节。
但是如果转换成FST结构的话,可以用四个字节表示name,总共占用内存为4+4*3=16。(假设数据范围只有M,i,e,c) 四个字符。
ES 分布式数据结构设计
- 数据分片均衡
分片是 Elasticsearch 在集群中分发数据的关键。文档存储在分片中,然后分片分配到集群中的节点上。当集群扩容或缩小,Elasticsearch 将会自动在节点间迁移分片,以使集群保持平衡。
- 数据可靠
分片有主分片,复制分片。复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的 shard 取回文档。
每个主分片都有一个或多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。主分片和对应的副本分片是不会在同一个节点上的 。
- 分布式搜索
分片本身就是一个完整的搜索引擎,它可以使用单一节点的所有资源。主分片或者复制分片都可以处理读请求——搜索或文档检索,所以数据的冗余越多,能处理的搜索吞吐量就越大
ES 集群中每个节点通过路由都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
在一个写请求被发送到某个节点后,该节点即为协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。如果是查询操作,则协调节点会将请求分发到其他分片上,其他分片查询结果之后再由协调节点将数据组装返回。
所以,引入ES,能够实现帮你解决数据量多,分布式查询问题。同时ES会自动的替你对所有字段建立索引,以实现高性能的复杂聚合查询,因此只要是存入ES的数据,无论再复杂的聚合查询也可以得到不错的性能,而且你再也不用为如何建立各种复杂索引而头痛了。另外,ES支持多种分词器,对全文搜索支持更加高效。
ES引入会有什么样的问题
- 字段类型无法修改、写入性能较低和高硬件资源消耗
ES需要在创建字段前要预先建立Mapping,Mapping中包含每个字段的类型信息,ES需要根据Mapping为字段建立合适的索引。由于这个Mapping的存在,ES中的字段一但建立就不能再修改类型了。ES在数据结构灵活度上高于MySQL但远不如MongoDB
- 不支持事务,JOIN
- 吃硬件
ES的排序和聚合(Aggregation)操作会把几乎所有相关不相关的文档都加载到内存中,一个Query就可以很神奇地吃光所有内存,现在新的Lucene版本优化了基于硬盘的排序,但也仅当你使用SSD的情况下,才不会牺牲过多的搜索性能。其他的问题还包括,大量的增量写操作会导致大量的后台Merge,CPU和硬盘读写都会很容易达到瓶颈。ES确实在横向Scale方面做的很出色,但前提是有足够的预算买硬件。
- 数据实时性
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存,当达到默认的时间(1秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统 上,稍后再被刷新到磁盘中并生成提交点。因此,从Index请求到对外可见能够被搜到,最少要1秒钟的数据延时。
- 不支持数据的权限管理
总结
ES香不香看你怎么用。有人用的很爽,有人用的很痛苦。用好了就少加班调索引,调sql。用不好就常加班调ES。
优点:
- 1.高并发
- 2.容错能力比mg强。比如1主多从,主片挂了从片会自动顶上
- 3.满足大数据下实时读写需求,无需分库(不存在库的概念)。
- 4.易扩展。分片数据自动均衡
- 5.支持较复杂的条件查询,group by、排序都不是问题
缺点:
- 1.不支持事务
- 2.读写有一定延时
- 3.无权限管理
- 4.吃硬件



















