概念
compare and swap,解决多线程并行情况下使用锁造成性能损耗的一种机制,CAS操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在CAS指令之前返回该位置的值。CAS有效地说明了“我认为位置V应该包含值A;如果包含该值,则将B放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。
简单点来说就是修改之前先做一下对比,校验数据是否被其他线程修改过,如果修改过了,那么将内存中新的值取出在与内存中的进行对比,直到相等,然后再做修改。
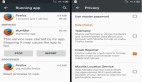
假如我们要对变量:num做累加操作,num初始值=0。1.cpu前往内存取出num;2.判断内存中的num是否被修改;3.做+1操作;4.将修改后的值写入内存中;
这时候可能会有疑问了,判断、自加、写回内存难道不会发生线程安全问题吗?既然cas能成为并发编程中安全问题的解决这,那么这个问题肯定是不会发生的,为什么呢?因为判断、自加、写回内存这是一个由硬件保证的原子操作,硬件是如何保证原子性的,请先看下面这个例子
需求:
使用三个线程分别对某个成员变量累加10W,打印累加结果。
我们使用两种方法完成此需求。1.正常累加(既不加锁,也不使用原子类)。
1.使用synchronized。
2.使用原子类(Atomic)。
实现
1.正常累加(既不加锁,也不使用原子类)。
这种方式没有什么说的,直接上代码
- package com.ymy.test;
- public class CASTest {
- private static long count = 0;
- /**
- * 累加10w
- */
- private static void add(){
- for (int i = 0; i< 100000; ++i){
- count+=1;
- }
- }
- public static void main(String[] args) throws InterruptedException {
- //开启三个线程 t1 t2 t3
- Thread t1 = new Thread(() ->{
- add();
- });
- Thread t2 = new Thread(() ->{
- add();
- });
- Thread t3 = new Thread(() ->{
- add();
- });
- long starTime = System.currentTimeMillis();
- //启动三个线程
- t1.start();
- t2.start();
- t3.start();
- //让线程同步
- t1.join();
- t2.join();
- t3.join();
- long endTime = System.currentTimeMillis();
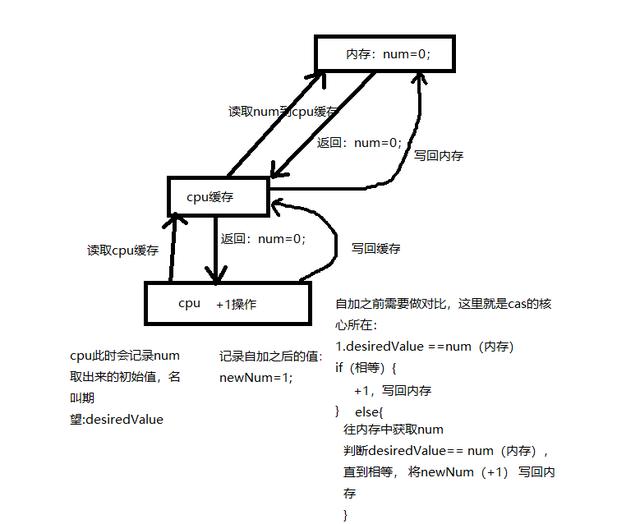
- System.out.println("累加完成,count:"+count);
- System.out.println("耗时:"+(endTime - starTime)+" ms");
- }
- }
执行结果

很明显,三个线程累加,由于cpu缓存的存在,导致结果远远小于30w,这个也是我们预期到的,所以才会出现后面两种解决方案。
2.使用synchronized
使用synchronized时需要注意,需求要求我们三个线程分别累加10W,所以synchronized锁定的内容就非常重要了,要么直接锁定类,要么三个线程使用同一把锁,关于synchronized的介绍以及锁定内容请参考:java并发编程之synchronized
第一种,直接锁定类,我这里采用锁定静态方法。
我们来改动一下代码,将add方法加上synchronized关键字即可,由于add方法已经时静态方法了,所以现在锁定的时整个CASTest类。
- /**
- * 累加10w
- */
- private static synchronized void add(){
- for (int i = 0; i< 100000; ++i){
- count+=1;
- }
- }
运行结果第一次:

第二次:

第三次:
这里就有意思了,加了锁的运行时间居然比不加锁的运行时间还少?是不是觉得有点不可思议了?其实这个也不难理解,这里就要牵扯到cpu缓存以及缓存与内存的回写机制了,感兴趣的小伙伴可以自行百度,今天的重点不在这里。
第二种:三个线程使用同一把锁
改造代码,去掉add方法的synchronized关键字,将synchronized写在add方法内,新建一把钥匙(成员变量:lock),让三个累加都累加操作使用这把钥匙,代码如下:
- package com.ymy.test;
- public class CASTest {
- private static long count = 0;
- private static final String lock = "lock";
- /**
- * 累加10w
- */
- private static void add() {
- synchronized(lock){
- for (int i = 0; i < 100000; ++i) {
- count += 1;
- }
- }
- }
- public static void main(String[] args) throws InterruptedException {
- //开启三个线程 t1 t2 t3
- Thread t1 = new Thread(() -> {
- add();
- });
- Thread t2 = new Thread(() -> {
- add();
- });
- Thread t3 = new Thread(() -> {
- add();
- });
- long starTime = System.currentTimeMillis();
- //启动三个线程
- t1.start();
- t2.start();
- t3.start();
- //让线程同步
- t1.join();
- t2.join();
- t3.join();
- long endTime = System.currentTimeMillis();
- System.out.println("累加完成,count:" + count);
- System.out.println("耗时:" + (endTime - starTime) + " ms");
- }
- }
结果如下:

这两种加锁方式都能保证线程的安全,但是这里你需要注意一点,如果是在方法上加synchronized而不加static关键字的话,必须要保证多个线程共用这一个对象,否者加锁无效。
原子类
原子类工具有很多,我们举例的累加操作只用到其中的一种,我们一起看看java提供的原子工具有哪些:
工具类还是很丰富的,我们结合需求来讲解一下其中的一种,我们使用:AtomicLong。
AtomicLong提供了两个构造函数:
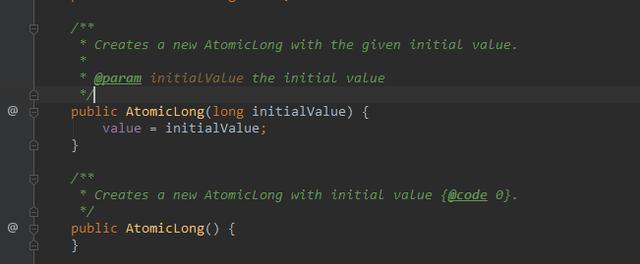

value:原子操作的初始值,调用无参构造value=0;调用有参构造value=指定值
其中value还是被volatile 关键字修饰,volatile可以保证变量的可见性,什么叫可见性?可见性有一条很重要的规则:Happens-Before 规则,意思:前面一个操作的结果对后续操作是可见的,线程1对变量A的修改其他线程立马可以看到,具体请自行百度。
我们接着来看累加的需求,AtomicLong提供了一个incrementAndGet(),源码如下:
- /**
- * Atomically increments by one the current value.
- *
- * @return the updated value
- */
- public final long incrementAndGet() {
- return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
- }
Atomically increments by one the current value :原子的增加一个当前值。好了,我们现在试着将互斥锁修改成原子类工具,改造代码:
1.实例化一个Long类型的原子类工具;
2.再for循环中使用incrementAndGet()方法进行累加操作。
改造后的代码:
- package com.ymy.test;
- import java.util.concurrent.atomic.AtomicLong;
- public class CASTest {
- // private static long count = 0;
- //
- // private static final String lock = "lock";
- private static AtomicLong atomicLong = new AtomicLong();
- /**
- * 累加10w
- */
- private static void add() {
- for (int i = 0; i < 100000; ++i) {
- atomicLong.incrementAndGet();
- }
- }
- public static void main(String[] args) throws InterruptedException {
- //开启三个线程 t1 t2 t3
- Thread t1 = new Thread(() -> {
- add();
- });
- Thread t2 = new Thread(() -> {
- add();
- });
- Thread t3 = new Thread(() -> {
- add();
- });
- long starTime = System.currentTimeMillis();
- //启动三个线程
- t1.start();
- t2.start();
- t3.start();
- //让线程同步
- t1.join();
- t2.join();
- t3.join();
- long endTime = System.currentTimeMillis();
- //System.out.println("累加完成,count:" + count);
- System.out.println("累加完成,count:" + atomicLong);
- System.out.println("耗时:" + (endTime - starTime) + " ms");
- }
- }
结果:

可以得到累加的结果也是:30w,但时间却比互斥锁要久,这是为什么呢?我们一起来解剖一下源码。
AtomicLong incrementAndGet()源码解析
- /**
- * Atomically increments by one the current value.
- *
- * @return the updated value
- */
- public final long incrementAndGet() {
- return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
- }
- public final long getAndAddLong(Object var1, long var2, long var4) {
- long var6;
- do {
- var6 = this.getLongVolatile(var1, var2);
- } while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
- return var6;
- }
我们来看看getAndAddLong方法,发现内部使用了一个 do while 循环,我们看看循环的条件是什么
- public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
这是循环条件的源码,不知道你们发现没有一个关键字:native,表示java代码已经走完了,这里需要调用C/C++代码,这里调用的时C++代码,在这里就要解释一下为什么原子类的比较和赋值是线程安全的,那是因为c++代码中是有加锁的,不知道你们是否了解过内存与cpu的消息总线制,c++就是再消息总线中加了lock,保证了互斥性,所以对比和赋值是一个原子操作,线程安全的。
Unsafe,这个类可以为原子工具类提供硬件级别的原子性,虽然我们java中使用的这些原子工具类虽然都是无锁的,但是我们无需考虑他的多线程安全问题。
为什么原子类比互斥锁的效率低?
好了,现在来思考一下为什么原子工具类的效率会比互斥锁低?明明没有加锁,反而比加了锁慢,这是不是有点不合常理?其实这很符合常理,我们一起来分析一波,CAS(Compare and Swap)重在比较,我们看源码的时候发现有一个 do while循环,这个循环的作用是什么呢?
1.判断期望值是否和内存中的值一致;
2.如果不一致,获取内存中最新的值(var6),此时期望值就等于了var6,使用改期望值继续与内存中的值做对比,直到发现期望值和内存中的值一致,+1之后返回结果。
这里有一个问题不知道你们发现没有,就是这个循环问题,1.我们假设线程1最先访问内存中的num值=0;加载到cpu中;2.还没有做累加操作,cpu执行了线程切换操作;3.线程2得到了使用权,线程2也去内存中加载num=0,累加之后将结果返回到了内存中;4.线程切回线程1,接着上面的操作,要和内存中的num进行对比,期望值=0,内存num=1,法向对比不上,从新获取内存中的num=1加载到线程1所在的cpu中;5.此时线程又切换了,这次切换了线程3;6.线程3从内存中加载num=1到线程3所在的cpu中,之后拿着期望值=1与内存中的num=1做对比,发现值并没有被修改,此时,累加结果之后写回内存;7.线程1拿到使用权;8.线程1期望值=1与内存num=2做对比,发现又不相同,此时又需要将内存中的新num=3加载到线程1所在的cpu中,然后拿着期望值=2与内存num=2做对比,发现相同,累加将结果写回内存。
这是再多线程下的一种情况,我们发现线程1做了两次对比,而真正的程序循环对比的次数肯定会比我们分析的多,互斥锁三个线程累加10w,只需要累加30万次即可,而原子类工具需要累加30万次并且循环很多次,可能几千次,也可能几十万次,所以再内存中累加操作互斥锁会比原子类效率高,因为内存的执行效率高,会导致一个对比执行很多循环,我们称这个循环叫:自旋。
是不是所有情况下都是互斥锁要快呢?肯定不是的,如果操作的数据再磁盘中,或者操作数据量太多时,原子类就会比互斥锁的性能高很多,这很好理解,就像内存中单线程比多线程效率会更高(一般情况)。
CAS的ABA问题
ABA是什么?我们来举个例子:变量a初始值=0,被线程1获取a=0,切换到线程2,获取a=0,并且将a修改为1写回内存,切换到线程3,再内存中获取数据a=1,将数据修改为0然后写回内存,切换到线程1,这时候线程1发现内存中的值还是0,线程1认为内存中a没有被修改,这时候线程1将a的值修改为1,写回内存。
我们来分析一下这波操作会不会有风险,从表面上看,好像没什么问题,累加或者值修改的时候问题不大,觉得这个ABA没有什么风险,如果你这样认为,那就大错特错了,我举个例子,用户A用网上银行给用户B转钱,同时用户C也在给用户A转钱,我们假设用户A账户余额100元,用户A要给用户B转100元,用户C要给用户A转100元,用户A转给用户B、用户C转给用户A同时发生,但由于用户A的网络不好,用户A点了一下之后没有反应,接着又点了一下,这时候就会发送两条用户A给用户B转100元的请求。
我们假设线程1:用户A第一次转用户B100元
线程2:用户A第二次转用户B100元
线程3:用户C转用户A100元。
线程1执行的时候获取用户A的余额=100元,此时切换到了线程2,也获取到了用户A的余额=100元,线程2做了扣钱操作(update money-100 where money=100),100是我们刚查出来的,扣完之后余额应该变成了0元,切换到线程3,用户C转给用户A100元,此时用户A的账户又变成了100元,切换到线程1,执行扣钱操作(update money-100 where money=100),本来是应该扣钱失败的,由于用户C给用户A转了100元,导致用户A的余额又变成了100元,所以线程1也扣钱成功了。
这是不是很恐怖?所以在开发的时候,ABA问题是否需要注意,还请分析好应用场景,像之前说的这个ABA问题,数据库层面我们可以加版本号(版本号累加)就能解决,程序中原子类也给我们提供了解决方案:AtomicStampedReference,感兴趣的小伙伴可以研究一下。其实思路和版本号类似,比较的时候不仅需要比较期望值,还要对比版本号,都相同的情况下才会做修改。