为了提高人脸识别的实时性,我们团队将传统的利用神经网络框架推理升级至统一的 TensorRT 加速推理。经实验对比,经 TensorRT FP16 模式推理加速后的人脸识别不仅几乎无损精度,甚至于在部分场景精度有提升,识别速度提升为原来的 2.3 倍。统一加速推理的人脸识别不仅能为客户提供优质高响应的服务,同时也能提升 AI 服务器资源利用率,降低服务成本,也有利于各模型推理的整合统一。
一、目的及背景
首先,量化推理的出现为提升人脸识别服务的响应速度,给客户提供更优质的服务体验提供了更多的选择。
其次,由于不同业务需求的神经网络模型可能是在不同的神经网络框架下训练生成的,比如说人脸检测利用的是 TensorFlow,人脸识别利用的是 MxNet,而肖像生成利用的是 PyTorch。如果线上服务都用深度学习框架进行推理,则需要在服务器上部署多种框架,相对于统一的推理引擎,多种框架不利于结构的优化以及数据之间的通信,且会增加升级和维护的成本。
最后,面对日益增长的 AI 服务需求,为了保证响应的服务质量,企业需要采购更多的服务器资源,特别是 GPU 服务器。如何提升服务器资源的利用率,降低相应的服务成本也成为迫切的需求。通过模型量化推理减少计算和存储资源的占用,而推理加速也可以减少服务器资源占用。
基于以上背景,我们团队对现有的量化推理和深度学习推理服务进行了调研和实验。
二、相关技术
1、TensorRT
什么是 TensorRT?TensorRT 是 Nvidia 开发的用于高性能深度学习推理的 SDK。其包括一个高性能的神经网络 Inference Optimizer 和一个 Runtime Engine 用于生产部署。利用 TensorRT,可以优化所有主要深度学习框架中训练的神经网络模型,以高准确性来校准低精度,最终部署到超大规模的数据中心、嵌入式设备或汽车产品平台。如图 1 所示:

TensorRT 通过融合层和优化内核来优化网络,从而提高延迟、吞吐量、功率效率和内存消耗。如果应用程序指定,它还将优化网络以降低运行精度,进一步提高性能并减少内存需求。如图 2 所示:
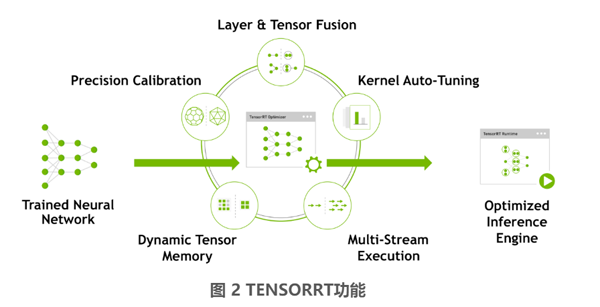
TensorRT 为深度学习推理应用的生产部署提供 INT8 和 FP16 优化,如视频流、语音识别、推荐和自然语言处理。减少精度推理可以显著降低应用程序延迟,降低延迟是许多实时服务、自动驾驶和嵌入式应用程序的需求。
① Low Precision Inference
MxNet、TensorFlow、PyTorch 等现有的深度学习框架,在训练模型的时候,一般都会使用 Float 32(简称 FP32)的精度来表示权值、偏置、激活值等. 而当网络的层数逐渐加深,其参数的计算量是极其多的,比如像 ResNet、VGG 这种网络。如此大的计算量,如果在推理过程中都用 FP32 的精度来计算,会比较耗费时间和资源。如果是在对计算资源有限制的移动设备或者是嵌入式设备,如此大的计算量简直无法想法,甚至于根本运行不起来。
在部署推理的时候使用低精度的数据,比如 INT8、FP16 等就是解决大计算量以及提升推理速度的一种方法。当然解决大计算量问题的方法,还有模型压缩这类方法。但本文的方法专注于模型推理阶段的优化。
那么问题就来了,使用更低精度的数值表示会不会降低原来的模型准确性。毕竟如表格 1 所示,不同精度的动态范围相差还是很大。

对这个精度损失的问题,已经有不少学者在经验层面对其进行了相应的分析。比如 Why are Eight Bits Enough for Deep Neural Networks? [1]以及 Low Precision Inference with TensorRT [2] 这两篇博文的提出即便是推理时使用低精度的数据,在提升推理速度的同时,并不会对精度造成太大的影响。博文作者认为神经网络学习到数据样本的模式可分性,同时由于数据中存在的噪声,使得网络具有较强的鲁棒性,也就是说在输入样本中做轻微的变动并不会过多的影响结果性能。甚至有研究发现,在某些场景下,低精度推理能提升结果的准确性。此外 Improving the Speed of Neural Networks on CPUs [3]和 Training Deep Neural Networks with Low Precision Multiplications [4] 这两篇文章则在理论上其进行了分析论证。
由于 INT8 的低存储占用以及高通过率,但是由于其表示范围与 FP32 相差还是太大,实际上将 FP32 精度降为 INT8 精度,即用 8bit 来表示原来用 32bit 表示的 tensor,这其实相当于信息再编码过程,而且不能有明显的精度损失,还是具有相当大的挑战。该转换过程需要将每一层输入张量 (Tensor) 和网络学习的参数都从原来的 FP32 表示转为 INT8 表示。因此需要最小化该转换过程的信息损失,而且转换方式得要是简单而且计算效率高的。TensorRT 采用是简单有效的线性量化的转换方式。即式(1):
FP32 Tensor(T) = FP32 scale factor * 8-bit Tensor(t) + FP32_bias(b)(1)
其中 Nvidia 的研究者经过证明可以将其中的偏置项去掉,即式(2):
FP32 Tensor(T) = FP32 scale factor * 8-bit Tensor(t)(2)
那么在转换过程中最重要的就是确定这个 scale factor,最简单的方法就是如图 3 左边所示的直接将 FP32 tensor 值中的 –|max| 和 |max| 映射为 INT8 对应的 -127 和 127,中间的值按照线性的关系进行映射,该方法也被称为不饱和(No saturation)映射。但是经过实验表明,该种方式有明显的精度损失。因此 TensorRT 的开发者采用被称为饱和 (saturate) 映射的方式,如图 3 右边所示:
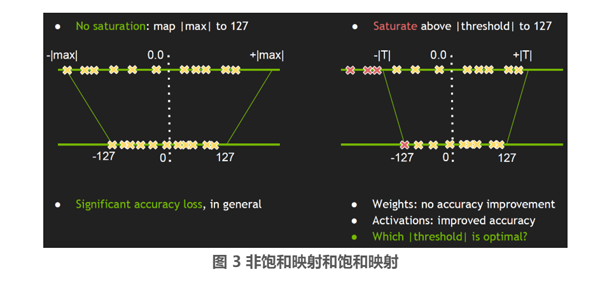
相对于非饱和映射,不再是直接将两端的 ±|max|值映射到±127,而是选取一个阈值|T|, 将 ±|T| 映射为±127,其中 |T| < |max|。在 [ -|T|, |T| ] 区间外的值直接映射为 ±127,比如图 3 中的三个红色 x 点就直接映射为 -127, 而在 [ -|T|, |T| ] 区间内的按照线性映射的方式。
TensorRT 开发者分别对网络推理过程中涉及的权重 ( weights ) 和激活值 ( activation ) 做了实验,得出对权重做饱和映射相对于不饱和方式并没有精度的提高,而对激活值做饱和映射有明显的精度提升。因此在 TensorRT 中对权重采用的是不饱和映射的方式,对激活值采用的是饱和映射的方式。
那么为什么非饱和映射的方式相对饱和映射有精度的提升?此外非饱和映射中的 T 要如何选取呢?首先来看下图右边所示,该图是 resnet-152 网络模型中间层的激活值统计,横坐标是激活值,纵坐标是统计数量的归一化表示。
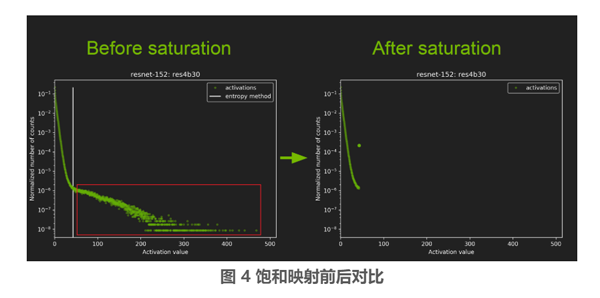
可以看到图 4 中白线左边的激活值分布比较的集中重合,而白线(该线对应的就是阈值 T 线)右边,即红色框内的激活值就比较的分散,而且在红色框内的激活值在整个层中所占的比例比较少,因此这部分可以不考虑到映射关系中,如图右边所示。研究发现大部分的网络都具有这种大部分激活值集中,少量激活值分散的特点。
T 值需要满足 FP32 模式到 INT8 模式转换的信息损失最小化,而信息损失可以用 KL 散度(也叫做相对熵)来衡量,即如式(3)所示:
KL_divergence(P, Q) := SUM( P[i] * log( P[i] / Q[i] ), i) (3)
其中 P,Q 分别表示 FP32 和 INT8 模式下的分布,每一层 tensor 对应的 T 值都是不同的,而确定 T 值的过程被称为校准(Calibration), 如图 5 所示校准的原理图。
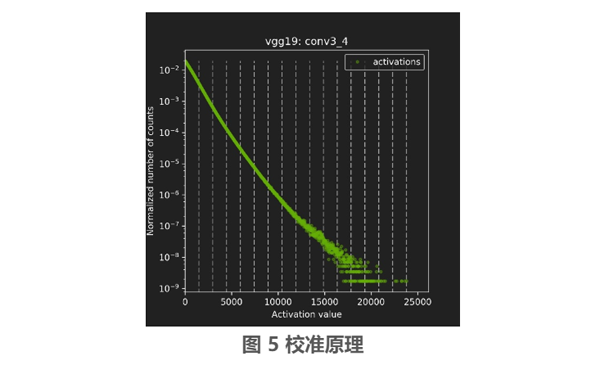
首先需要在校准数据集(Calibration Dataset)做 FP32 推理,然后获取每一层激活值的直方图,并用不同的量化阈值生成相应的量化分布。其中量化阈值就如上面的激活值直方图中,等间隔的虚线所对应的激活值就是量化阈值,我们需要的 T 值就是这些虚线中能够使得 KL 散度最小化的激活值。这个校准是需要一些时间的,所以每次进行量化的时候,会将校准得到的 T 值都保存在相应的文件中,待下次进行 FP32 到 INT8 推理模式转换的时候,直接读取保存了每层 T 值的文件,这样可以节省整个流程的时间。
显而易见的是校准数据集(Calibration Dataset)会直接的影响到激活值的分布,进而影响到 T 值的选择。校准数据集要具有代表性、多样性,比如在图像分类应用中,校准数据集的要能够代表所有的分类目标。验证集 (validation dataset) 的子集是比较理想的校准集,当然有人或许会问,把全部的数据用于校准不就可以最好的体现原始数据分布么?但是这样的话也会增加整个流程的时间,而经过研究和实验表明校准集只需要 1000 个样本即可。
TensorRT INT8 量化的性能和精度,图 6 和图 7 来自 Nvidia 官方的 PPT。

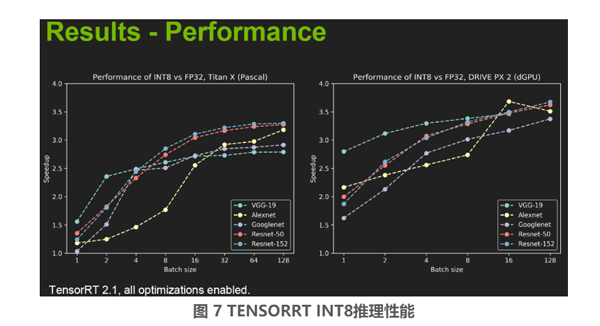
从上面图 6 和图 7 中可以看到经过校准的 INT8 推理相对于 FP32 的推理,准确率(Accuracy)有略微的损失,也可见在部分情况下(图 6 表格中绿色所示)INT8 推理相比 FP32 推理准确率有略微提升。另外可以看见一个趋势,随着 Calibration dataset 中图片数量的增加,INT8 相对于 FP32 的精度损失是在逐渐减小。从 Performance 这张图中可见在不同的推理 Batch Size(注意实际推理的 Batch Size 和 Calibration 过程中的 Batch Size 并不需要保持一致)设定下,INT8 推理相比于 FP32 推理的加速比。图中可见 Batch Size 越大,加速效果越好,在 Batch Size 为 128 的时候,加速比大约在 3.5 倍左右,当然实际的加速比和硬件平台,还有神经网络本身也有关系。除了速度上面的提升以外,低精度推理在存储消耗上相对于 FP32 也有相应的优化,如图 8 所示:
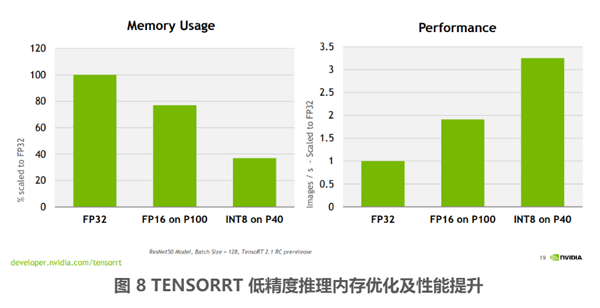
图 8 中,INT8 on P40 即表示在 P40 显卡上进行 INT8 推理,可以看出相比 FP32 推理模式内存占用减少了 3 倍多,而速度提升了 3 倍多。而 FP16 模式也减少了 30% 的内存占用,速度提升了近两倍。
当然,上述的实验对比测试均来自 Nvidia 官方,具体到我们实际的深度学习场景,还需要经过实验进行对比精度的损失以及速度的提升,在第三章中,将会概述我们团队利用 TensorRT 加速人脸识别的实验流程以及效果,还有在实施中遇到的一些问题和解决方法。
② 神经网络优化
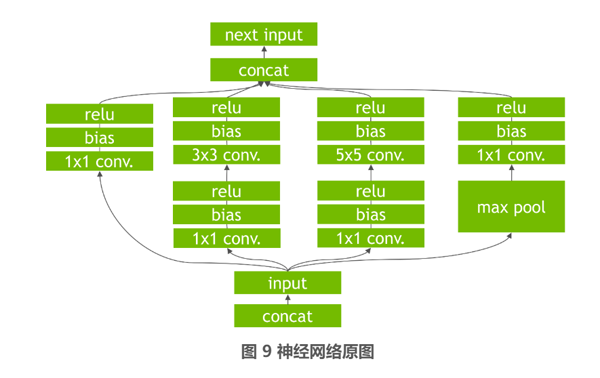
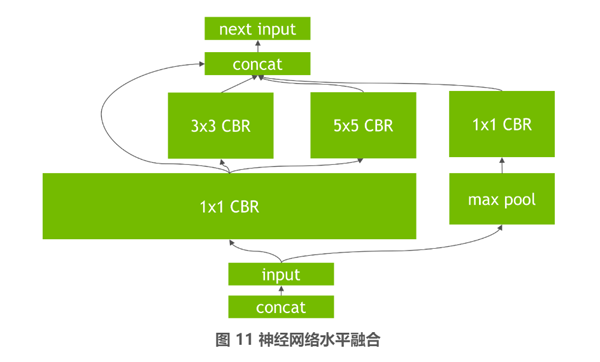
TensorRT 除了通过支持 FP16 和 INT8 这两种低精度模式的推理来提升速度以外,其在底层会根据 GPU 特性对神经网络进行相应的重构和优化。首先是其会删除一些并没有使用输出的层,以避免不必要的计算。然后会对神经网络中一些可以合并的运算进行合并,例如在图 9 所示的原始网络,TensorRT 会将其中的 conv、bias、relu 这三个层融合在一个层中,即图 10 所示的 CBR 层,这个合并操作也被成为垂直层融合。进一步的还有水平层融合,即如图 10 到图 11 的过程,将处于同一水平层级的 1x1CBR 融合到一起。

2、Inference Server
Inference Server 是一类为机器学习模型提供一站式管理、推理服务、集成等功能的高性能模型服务系统。以下简要介绍几种常见的 Inference Server。
① TensorFlow Serving
TensorFlow Serving 是由 Google 的 TensorFlow 团队开发的一种灵活的、高性能的机器学习模型服务系统,专为生产环境设计。在机器学习推理方面,其可以对训练后的模型进行生命周期管理,通过高性能、引用计数的查找表为客户端提供版本化访问。其提供了与 TensorFlow 模型开箱即用的集成,也能拓展到其他模型。如果模型由 TensorFlow 训练生成的,用 TensorFlow Serving 最为方便。详细介绍参见 https://github.com/tensorflow/serving 。
② MMS( Multi Model Server )
Multi Model Server(MMS)是一个灵活和易于使用的工具,为使用任何 ML/DL 框架训练的深度学习模型提供推理服务。这个是由 Amazon 的 AWSlab 开发的模型推理工具,原来叫 MxNet Model Server。由于 Amazon 主力支持的是 MxNet,因此 MMS 对 MxNet 有更好的优化,对 MxNet 的特性支持也更加积极。详见 https://github.com/awslabs/multi-model-server 。
③ TensorRT Inference Server
前面介绍的 TensorFlow Serving 和 MMS 都是由深度学习框架的厂商推出的,相应的对其各自的深度学习框架支持也会更好。
TensorRT Inference Server (最新版叫 Nvidia Triton Inference Server)是由显卡厂商 Nvidia 开发的深度学习模型推理 Server。其针对 Nvidia GPU 有更深层次的优化,该 Server 可以通过 HTTP 或者 GRPC 端点提供推理服务。其最大的特点是多框架的支持,其不仅支持 TensorRT 本身生成的模型,而且支持 TensorFlow、Caffe2、ONNX 和 PyTorch 的模型。还支持混合模型的推理,以及不同框架模型同时推理。这很好的契合业务上推理服务与神经网络框架脱离的需求。详见 https://github.com/NVIDIA/triton-inference-server。
这里简单介绍常见的 Inference Server,当然还有其他厂商的 Inference Server,如 TorchServe,见 https://github.com/pytorch/serve。
三、TensorRT 加速人脸识别
1、TensorRT 的典型 INT8 工作流程:
首先我们需要在 FP32 模式下训练得到的模型文件及校准数据集。接下来:
① TensorRT 将会在校准集上作 FP32 的推理。
② 得到每个网络层相应的激活值统计。
③ 实施校准算法即获取每层对应的最佳阈值 T,获取最优的量化因子。
④ 量化 FP32 的权重为 INT8 模式。
⑤ 生成相应的校准表 ( CalibrationTable ) 和 INT8 执行引擎。
2、TensorRT 加速需要注意的问题:
① 深度学习框架与 TensorRT 的整合度不同
如上所述实施 TensorRT 推理加速,首先是需要一个 FP32 模式下训练得到的神经网络模型。如果要进行 INT8 推理,还需要校准数据集 (Calibration Dataset),一般是选取验证集的子集。由于各深度学习框架和 TensorRT 的整合度和支持度不同,除了 TensorFlow 和 MATLAB 已经集成了 TensorRT 外,大部分的深度学习框架生成的模型都要通过 ONNX 格式导入 TensorRT 中。如图 12 所示:
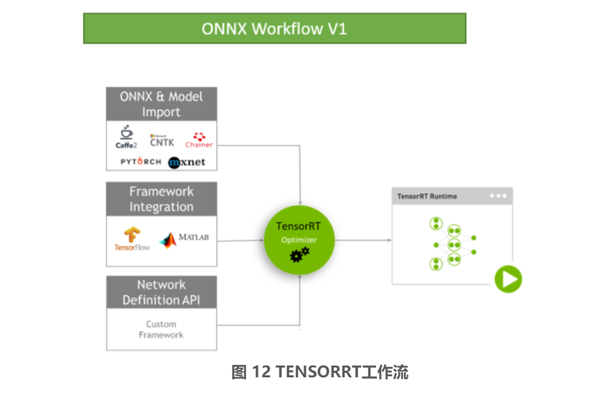
由于 TensorFlow 内实现了和 TensorRT 进行整合的 API,即可以从 TensorFlow 代码中指定 TensorRT 作为 Inference 的 backend,TensorRT 中也实现了一个 TensorFlow Parser 用于解析 TensorFlow 生成的模型文件。PyTorch、MXNET 则需要在训练的时候将模型文件保存为 ONNX 格式,或者是将原先的模型文件导入框架再保存为 ONNX 格式。当然这些深度学习框架也在跟进对 TensorRT 的支持和整合,比如新的 1.60 版本 MXNET 中已经实现了调用 TensorRT 加速推理,但是当前版本只支持 FP16 的推理,还不支持 INT8 推理。当然使用框架内提供的 TensorRT 接口进行加速有其好处,当然也会带来相应的问题,好处是框架内提供的比较方便,减少转换等中间过程,但还是不能脱离框架本身,这与统一用推理引擎,脱离深度学习框架本身的出发点相背道。
② TensorRT 对神经网络中的算子和层的支持
由于我们当前业务中人脸识别是在 mxnet 框架上实现的,为了实现并对比其在 TensorRT FP32、FP16、INT8 三种模式下的精度损失情况和加速效果。我们首先将原始的 mxnet 格式(.params + .json)模型文件导入到 mxnet 中,然后利用 mxnet 内部的 onnx 接口将模型文件转换为 onnx 格式。这里需要注意一个问题是 Mxnet 模型导出为 onnx 格式,需要安装 1.3.0 以上版本的 mxnet,以及对应的组件 onnx 也需要 1.2.1 版本,不过我们测试过 1.3.0 版本的 onnx 也可以。具体可参见 MxNet 的官方教程:Exporting to ONNX format [5]。onnx-1.2.1 版本生成的是 onnx 文件默认 V7 版本的 onnx operator,而 1.3.0 版本 onnx 生成的 onnx 文件支持的是 V8 版本的 onnx operator。不同版本的 onnx operator 对算子的支持是不同的,而且即便是同样的算子,不同的版本其内部实现方式也可能会不同。不同版本的 TensorRT 对 onnx 的算子支持也不同,mxnet 对 onnx 算子支持可参见: ONNX Operator Coverage[6]。TensorRT 对 onnx 算子支持可参见:Supported ONNX Operators[7] 和 TensorRT-Support-Matrix-Guide[8]。
我们团队在利用 TensorRT 转换人脸识别 onnx 模型到 TensorRT 对应的模型文件(.trt)的过程就曾遇到过算子支持的问题。由 mxnet 生成的 onnx 模型文件导入到 TensorRT 之后,一直无法正常的导出 TRT 文件。后来通过调研发现是 TensorRT 对 Prelu 这个算子的支持模式问题。通过 Netron(神经网络可视化工具)可以清楚的看到这两种 Prelu 的模式区别。如图 13 所示:

其中绿色粗线左边的 PRelu 是 mxnet 中支持运行的模式,这是 mxnet 导出 onnx 的默认 PRelu 模式。绿色粗线右边带有 Reshape 的 PRelu 则是 TensorRT 中支持的模式。为此我们通过手动修改 mxnet 的对应 onnx 转换的源码,将导出的 onnx 文件的 Prelu 修改为图右边的模式。除此外,团队里有其他深度学习的任务在转 onnx 格式时还碰到过如 softmaxactivation、upsampling、crop 等算子的支持问题。除了修改 mxnet 的源码的解决方式以外,还可以通过修改原始的神经网络结构为支持 TensorRT 的,然后重新进行模型的训练,但重新调参训练模型在部分业务场景下所消耗的时间和精力成本比较大。也可以通过 TensorRT 提供的 plugin 功能来自行实现有些尚未支持的算子和网络层的解析。
③ 不同的显卡对计算模式的支持度不同
由于架构和功能上的差异,不同的显卡对 FP16、INT8、INT4 的支持,以及相对于 FP32 实际获得加速效果是不同的,详见图 14 的表格所示:
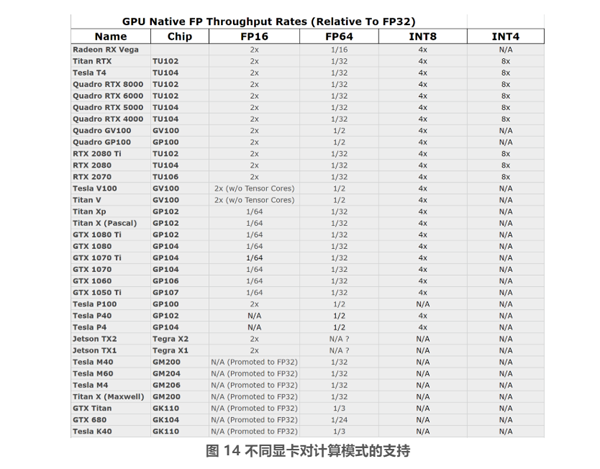
图 14 中,N/A 表示不支持,2x、4x、8x 分别表示在该模式下相对于 FP32 模式下的加速比为 2 倍、4 倍、8 倍。比如从表中可以看到,Tesla P100 支持 FP32 和 FP16,但是不支持 INT8 和 INT4 加速。而 Tesla P40 则支持 INT8,但是不支持 FP16。在 nvidia 新的图灵架构 (表中 chip 为 tu102 和 tu104) 卡已经完整的支持 FP16、INT8、INT4。
为保证 TensorRT 加速人脸识别的公平性,我们团队统一在 Tesla T4 上进行 FP32、FP16、INT8 的实验。另外有一点需要提到的是在不同的型号显卡上生成的 TensorRT 推理引擎文件 (TRT) 是不能通用的,比如说在 Tesla P40 上面生成的 TRT 文件并不能在 Tesla P100 上运行,反之同理。
3、人脸识别在经过 TensorRT 的加速后效果
测试集:由客流云系统前端摄像头采集的 506 张员工照片;
校准集:LFW,INT8 模式需要校准,FP16 模式无需校准;
测试平台: Nvidia Tesla T4;
相关设置: 校准 batch size 设置为 64;推理的 batch size 设置为 1,这个与我们实际业务场景一样,要求来一张处理一张,保证实时返回处理结果。
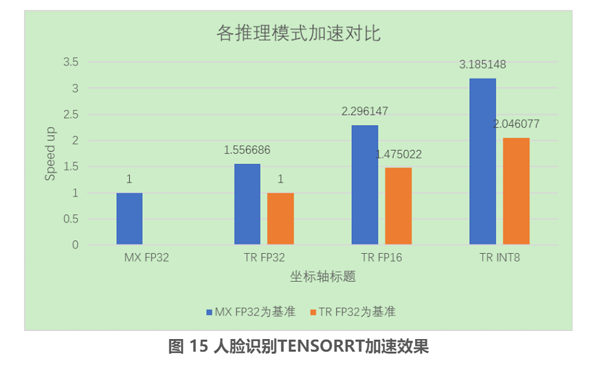
上面图 15 所展示的为我们团队利用 TensorRT 加速人脸识别的推理效果,其中 MX 表示利用 MXNET 框架进行推理,TR 表示利用 TensorRT 进行推理,FP32、FP16、INT8 分别表示对应的推理模式。首先来看蓝色柱形部分,以 MX FP32 为基准,在 TensorRT 上以 FP32 的精度来进行推理,其推理速度是 MX FP32 模式下的 1.557 倍,该提速主要是得益于 TensorRT 对神经网络中的层和算子进行相应的融合及优化。利用 TensorRT 分别在 FP16 和 INT8 模式下获得的提速分别是 2.296 倍和 3.185 倍。再看橙色的柱形,TR FP16 和 TR INT8 相对于 TR FP32 的 1.475 倍的加速主要是得益于 FP16 和 INT8 相对于 FP32 计算获得更加高效的计算以及更高的通过率。INT8 加速的效果是非常喜人的,不仅是速度的提升,以及还有内存上占比的减少,带来的效果不光是服务的提升,同时也能减少相应的资源成本。
我们的目的是在尽量保持原有精度的情况下获得提速,经过后续的精度对比实验,其中 FP16 模式几乎无精度损失,甚至于部分情况下精度有略微提升,而 INT8 模式的精度损失稍微大了些。为此团队在综合考虑之后,拟线上部署 TensorRT FP16 模式加速推理,FP16 模式精度几乎无损、加速效果可以、使用也比较方便(无需校准),另外 FP16 模式也是 NVIDIA 何琨老师比较推荐的。
四、总结
为了提升客流云的服务速度以及降低相应的服务成本,我们团队在调研和实验相关的量化推理加速方案后,利用 TensorRT 在无损精度的情况下将人脸识别服务的推理速度提升为原来的 2.3 倍。统一推理后台为 TensorRT,同时也为后续融合多种不同神经网络框架模型带来可能,也相应的减少了业务部署上的成本和麻烦。主要需要注意的问题是,神经网络框架、ONNX、TensorRT 对算子的支持,此外一定要结合自身的业务场景实验量化推理,保证无损精度的情况下获得相应的加速,这也为我们后续加速其他的 AI 服务提供了宝贵经验。