













谁不爱看可爱的小狗与顽皮的小猫?特别是在全球受新冠疫情影响而进行全面隔离的当下,我们更需要欢乐的视频来调剂自己的心情。
但这并不足以解释抖音为什么能获得如此之多的青睐。在不到两年时间里,它从一个只有少数粉丝的“对口型”应用,发展成今年月均近8亿活跃用户的“病毒式”应用。甚至,带有“新冠病毒”标签的抖音视频在应用中被播放了足足530亿次。
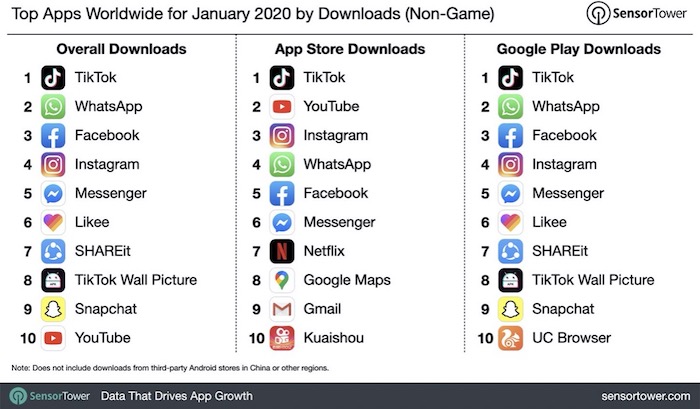
▲ 抖音成为2020年1月美国下载数量最高的应用
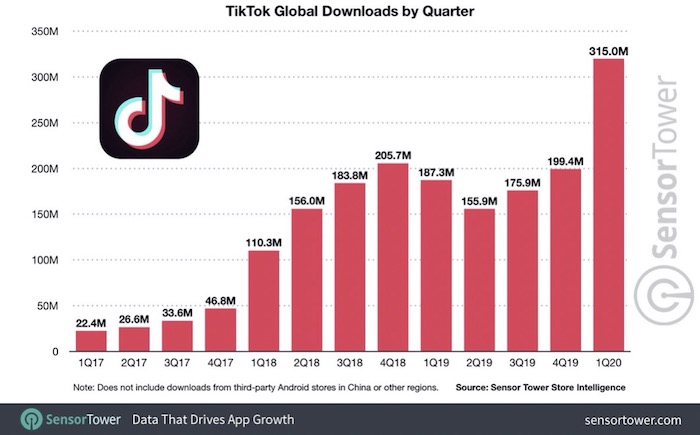
▲ 抖音全球下载量
抖音最显著的特色,在于各类洗脑歌曲加上有趣的哑剧式短视频。
用户每天平均在这款应用上耗费52分钟,相比之下,Snapchat、Instagram以及Facebook的日均使用时长分别为26分钟、29分钟与37分钟。
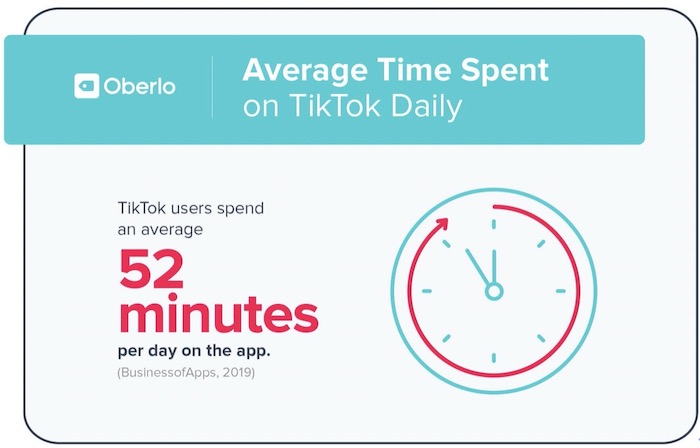
▲ Oberlo统计的使用时长报告
此外,这款只支持60秒短视频的应用中还充斥着模因、喜剧、舞蹈及无数才华横溢的用户。凭借着业内最强大的推荐引擎之一,我们无需搜索或拥有明确的诉求,就能很快找到符合自己口味的内容。点击一下,引擎会帮你生成个性化建议。
这种无穷无尽的快速刺激带来了轻松快乐的使用感受,最终让用户沉迷其中、无法自拔。有人将抖音称为浪费时间的终极杀手,并表示“在抖音上感觉过了5分钟,实际上已经过了1个小时。”
而在今天的文章中,我们将探讨抖音如何使用机器学习技术通过交互机制分析用户的兴趣与偏好,并据此为用户展示不同的个性化推荐内容。
对于数据科学社区来说,推荐引擎早已不是什么新鲜事物。但由于一直缺少图像识别或者语言生成等抓人眼球的最新“特效”,不少人倾向于将其划入传统AI系统一类。
尽管如此,推荐引擎仍是一类重要AI系统,而且几乎遍布各类在线服务与平台。从YouTube视频推荐、到亚马逊发布的广告邮件、再到Kindle书城中的热点图书,一切都是推荐引擎的功劳。
根据Gomez-Uribe与Netflix公司街道口负责人Neil Hunt发表的研究论文,个性化与推荐的综合作用每年可为Netflix节约超过10亿美元。此外,有80%的订阅者会从引擎提供的推荐列表中选择视频。
那么,抖音的独门绝技是什么?
1.关于推荐引擎
[ 如果您对推荐引擎的基本概念已经非常熟悉,可以直接阅读下一章节 ]
目前网络上关于推荐引擎的说明文章及在线课程所在多有,因此这里只给大家提供两条相关学习资源链接:
-
从零开始构建推荐引擎的综合指南[注1](阅读时长大约需要35分钟,重现其中的Python代码约需要40到60分钟)
-
来自吴恩达的推荐引擎指南[注2](视频时长约1个小时)
除了这些必要基础之外,工业级推荐引擎还需要强大的后端与架构设计以实现全面集成。下面来看相关示例:

▲ 推荐引擎(由Catherine Wang创建,版权所有)
实时系统应具备坚实的数据基础(用于收集与存储),支持顶端多个抽象层(算法层、服务层与应用层),借此解决不同的业务问题。
2.抖音推荐系统设计原型
“以用户为中心的设计”正是抖音的原型核心。简单来说,抖音只会推荐当前用户喜欢的内容,并从应用冷启动开始不断贯彻这种对用户偏好的跟踪与强化。
如果你点开了舞蹈视频,那么系统会初步将你的偏好定制为娱乐类,而后持续跟踪你的行为以进一步分析,最终为你提供高度贴合喜好的精确推荐。
下面说说高级工作流。

▲ 三大核心组件(由Catherine Wang创建,版权所有)
在抖音的原型体系中,包含三大核心组件:1)标记内容;2)创建用户资料与用户场景;3)训练并提供推荐算法。
下面,我们将具体对这三大组件做出说明。
2.1 数据与特征
首先是数据。如果用更正式的语言描述推荐模型,那它实际上是一项负责将用户满意度与“用户生成内容”匹配起来的函数。要实现这个目标,我们需要从三个维度输入数据。
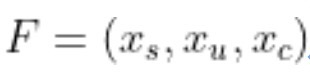
-
内容数据——抖音是一个包含大量用户生成内容的平台。每种类型的内容都有其特征,而系统需要能够识别并区分各类内容以实现可靠的推荐效果。
-
用户数据——其中包括兴趣标签、职业、年龄、性别、人口统计信息等等,也包含基于ML的客户集群内潜在特征。
-
场景数据——这部分数据用于跟踪用户在不同场景下的个人偏好变化。例如,用户在工作、旅行或者通勤时,分别更喜欢看到哪些类型的视频。
在收集到相关数据之后,系统就会导出四种类型的关键工程特征,并将其输入至推荐引擎当中。
-
关联特征:表示内容属性与用户标签之间的关联,包括关键字匹配、分类标签、源匹配、主题标签以及用户与内容间矢量距离等潜在特征。
-
用户场景特征:根据场景数据进行工程处理,包括地理位置、当前时间与事件标签等等。
-
趋势特征:基于用户交互并表现为全局趋势、热门话题、热门关键字、趋势主题等等。
-
协同特征:基于协同过滤技术,负责在狭窄推荐(偏见)与协同推荐(概括)之间寻求平衡。更准确地说,其不信会考虑单一用户的历史记录,同时还会分析相似用户组之间的协同行为(点击、赞、关键字、主题等)。而推荐引擎模型,将通过学习上述特征以预测特定内容在特定场景中是否适合特定用户。
2.2 隐性目标
在推荐模型当中,点击率、观看时长、赞、评论与转发等都属于明确可量化的目标。我们可以使用模型或算法对这些指标进行拟合,而后做出结论性的预测。
但除此之外,还存在其他一些无法通过这些可量化指标进行评估的隐性目标。
例如,为了维护健康的社区与生态系统,抖音一直努力控制与暴力、诈骗、色情及谣言相关的内容,希望保证平台上发布的内容更加贴近事实。
为此,自然需要在可量化模型目标之外定义新的边界控制框架(内容审核系统)。
2.3 算法
推荐目标可以指定为经典的机器学习问题,而后通过协同过滤模型、逻辑回归模型、分解机、GBD以及深度学习等多种算法对问题求解。
▲ 协同过滤示意图
工业级的推荐系统往往需要灵活且可扩展的机器学习平台以构建实验管道,借此快速训练各类模型,而后将不同模型叠加起来进行实时服务。(例如将强化学习、DNN、SVM以及CNN结合使用)
除了主推荐算法之外,抖音还需要训练内容分类算法与用户偏好算法。下面来看在实现内容分析方面,抖音建立起的多层级分类架构。

▲ 多层级分类树(由Catherine Wang创建,版权所有)
我们从主root起步,一层层下探。首先是主类别与子类别。与独立的分类器相比,这种多层级分类机制能够更好地解决数据偏斜的问题。
2.4 训练机制
抖音使用实时在线训练协议,因此能够以较少的计算资源需求提供更快的反馈速度。这两点对于流媒体与信息流产品无疑非常重要。
训练系统会即时捕捉用户的行为与动作,并将其反馈给模型以在下一次响应中有所体现。(例如,当您点击新的视频时,馈送内容会根据您的最新操作而快速更改)
据个人推测,抖音很可能是使用Storm Cluster处理实时样本数据,包括点击、展示、收藏、赞、评论与共享等。
他们还构建起模型参数与特征服务器(分别存储特征与模型),借此进一步提升系统性能。其中特征存储可保存并交付数千万项原始特征与工程矢量,而模型存储则负责模型与经调优参数的维护与交付。
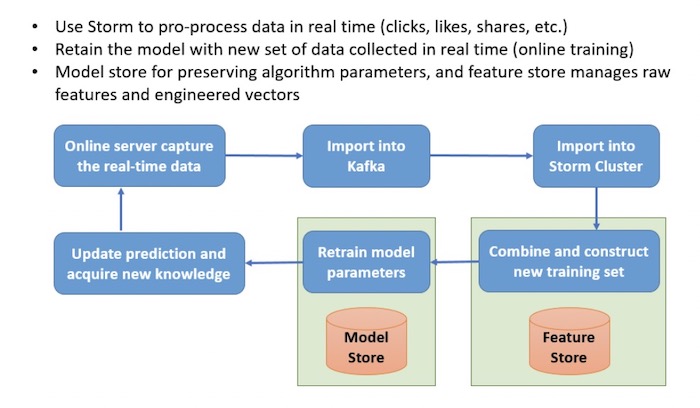
▲ 在线训练机制(简化版)(由Catherine Wang创建,版权所有)
下面我们对训练流程做出总结:1)在线服务器捕捉实时数据,并将其存储在Kafka当中;2)Storm Cluster使用Kafka数据并生成特征;3)特征存储负责收集新特征与推荐标签,并据此构建起新的训练集;4)在线训练管道重新训练模型参数,并将参数保存在模型存储中;5)更新客户端推荐列表,捕捉新的反馈(用户操作)并再次循环。
3.抖音的推荐工作流
抖音一直未向公众或技术界公开其核心算法。但通过该公司发布的零散信息,以及极客社区通过逆向工程发现的蛛丝马迹,我们初步得出以下结论。(免责声明——以下内容皆为作者个人的解释与推断,可能与抖音的实际情况有所出入)

▲ 推荐工作流(由Catherine Wang创建,版权所有)
步骤0:用户生成内容双审核系统 (UGC)
在抖音,每天有数百万用户上传自己制作的内容。恶意内容很可能从单一机器审核系统中发现漏洞并成功漏网,而过于庞大的上传量也让手动审核变得不切实际。为此,双审核成为抖音公司的主要视频内容筛选算法。

-
机器审核:总体来看,双审核模型(基于计算机视觉)可以识别用户上传内容中的视频图像与关键字。它主要提供两大核心功能:1)检查剪辑内容中是否存在违规并检查文本信息。如果怀疑存在问题,内容将被拦截并标记为黄色或红色,以供人工审核员进行复核。2)提取视频中的图片与关键帧,抖音的双审核算法随后将这些内容与庞大的归档内容库进行匹配。这些副本将被渲染为低精度版本,借此降低流量占用并减轻推荐引擎的处理负担。
-
手动审核:主要关注三个问题:视频标题、封面缩略图与视频关键帧。对于被双审核模型标记为可疑的内容,技术人员将进一步做出手动检查。如果确定违规,则删除该视频并冻结上传账户。
步骤1:冷启动
抖音推荐机制的核心在于信息流漏斗。在内容通过双审核过滤之后,将被放入冷启动流量池内。例如,当用户的新视频成功通过审核流程,抖音会为其分配200到300个活跃用户的初始流量,保证你的内容初步获得向用户展示的机会。
在这种机制下,新创作者可以与意见领袖们(可能已经拥有成千上万关注者)站上相同的起点,完全依靠作品质量展开正面竞争。
步骤2:基于指标的权重机制
通过初始流量池,我们的视频已经获得了几千次浏览,而这些数据将被进一步收集与分析。分析中考量的指标主要包括赞、观看、完整观看、评论、关注、转发与分享等数据。
接下来,推荐引擎会根据这些初始指标与账户得分(无论您是否身为高水平创作者)对内容进行权重评分。
根据评分结果,前10%的视频将获得额外10000到100000次推荐展示的机会。
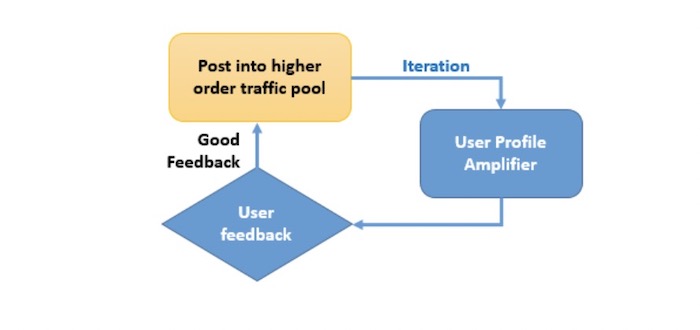
步骤3:用户偏好放大器
来自步骤2内流量池阶段的反馈将接受进一步分析,帮助系统判断是否使用用户偏好放大器。在这一步中,高质量的内容将被投放至特定的用户组(例如体育迷、时尚爱好者)中并得到进一步加强与放大。
这类似于“猜你喜欢什么”的概念。推荐引擎将建立用户个人偏好库,以便在内容与用户组之间找到最佳匹配。
步骤4:精品趋势池
只有低于1%的内容最终能够进入趋势池。趋势池中的内容将获得远超其他视频的曝光量,包括以无差别方式推荐给所有用户。
其他步骤:延迟曝光
部分抖音用户可能会注意到,自己的内容在发布数周之后,才突然获得了巨大的关注与点击——在此之前,观看量与转发量都一样比较平均。这是怎么回事?
这主要有两个原因:
-
首先,抖音使用一种昵称为“掘墓人”的算法,可以回溯旧有内容并挖掘出高质量的曝光对象。如果您的内容被这种算法选中,则表明您的账户中拥有足够的垂直视频以获得清晰的定位标签。换言之,建立明确的标签能够帮助您的内容得到“掘墓人”算法的青睐。
-
第二是“时尚效应”。换句话说,如果您的某条内容获得了数百万次观看,那么观看者会主动前往您的主页,查看您之前发布过的其他内容。这是个主动探索并发现宝藏的过程,也在一定程度上增加了用户的成就感。
局限性:流量峰值
如果某段内容通过信息流漏洞(双审核、权重迭代与放大),那么创建者的账户将获得大量展示机会、用户交互与关注群体。
但根据研究,这种高曝光时间窗口极窄。通常,该窗口只会持续一周左右;在此之后,内容与账户将快速“凉凉”,连随后发布的内容也无法得到人们的关注。
为什么会这样?
这主要是因为抖音希望尽量为内容制作者们提供更公平的发布环境,消除算法中的意外偏见。通过这种设计,推荐引擎不会偏向于特定类型的内容,这将保证各类新内容都有平等的机会成为新的爆款。
【注】:
1.https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/
2.https://www.youtube.com/playlist?list=PL-6SiIrhTAi6x4Oq28s7yy94ubLzVXabj
【参考资料】:
1.https://www.businessofapps.com/data/tik-tok-statistics/
2.https://mediakix.com/blog/top-tik-tok-statistics-demographics/
3.https://en.wikipedia.org/wiki/TikTok
4.http://shop.oreilly.com/product/9780596529321.do
5.https://sensortower.com/
6.https://www.nytimes.com/2020/06/03/technology/tiktok-is-the-future.html
















![[[329651]]](http://img.zhiding.cn/5/600/liMX9IxaK8uzQ.jpg){kind=link}