概述
本文将给大家介绍oracle各类文件损坏的现象和应对策略,请注意所有的恢复都是基于有备份的情况,所以请开启数据库的日常备份。
文章将从以下文件展开:
a. 密码文件
b. 参数文件
c. 控制文件
d. 数据文件(分普通表空间数据文件,其它表空间数据文件如system、sysaux、undo)
e. 日志文件(分current、active、inactive)
在正式实验之前,我先问一个问题,上面这些文件,哪个损坏最致命?欢迎在文末留言处留言。
环境准备
本实验在oracle 11G归档模式下进行,实验前先对数据库做个全库备份。
- 创建一个普通表空间和一些测试表create tablespace tbs01 datafile '/u01/app/oracle/oradata/orcltest/tbs01.dbf' size 500m;create table scott.t01 tablespace tbs01 as select * from dba_objects where rownum<=100;RMAN> backup database; // 全库备份RMAN> list backup; // 查看备份
- BS Key Type LV Size Device Type Elapsed Time Completion Time------- ---- -- ---------- ----------- ------------ ---------------21 Full 1.14G DISK 00:01:33 17-MAR-20 BP Key: 21 Status: AVAILABLE Compressed: NO Tag: TAG20200317T133425 Piece Name: /home/oracle/backupdir/ORCLTEST_2750922031_133_1_20200317_1035293665.bkp List of Datafiles in backup set 21File LV Type Ckp SCN Ckp Time Name---- -- ---- ---------- --------- ----1 Full 1606913 17-MAR-20 /u01/app/oracle/oradata/orcltest/system01.dbf2 Full 1606913 17-MAR-20 /u01/app/oracle/oradata/orcltest/sysaux01.dbf3 Full 1606913 17-MAR-20 /u01/app/oracle/oradata/orcltest/undotbs01.dbf4 Full 1606913 17-MAR-20 /u01/app/oracle/oradata/orcltest/users01.dbf5 Full 1606913 17-MAR-20 /u01/app/oracle/oradata/orcltest/example01.dbf6 Full 1606913 17-MAR-20 /u01/app/oracle/oradata/orcltest/tbs01.dbfBS Key Type LV Size Device Type Elapsed Time Completion Time------- ---- -- ---------- ----------- ------------ ---------------22 Full 9.73M DISK 00:00:02 17-MAR-20 BP Key: 22 Status: AVAILABLE Compressed: NO Tag: TAG20200317T133602 Piece Name: /home/oracle/backupdir/c-2750922031-20200317-00SPFILE Included: Modification time: 17-MAR-20SPFILE db_unique_name: ORCLTEST Control File Included: Ckp SCN: 1606985 Ckp time: 17-MAR-20
密码文件损坏
文件说明:密码文件存储的是sys密码
模拟故障:清空该文件
- echo '' > $ORACLE_HOME/dbs/orapworcltest // orcltest是该数据库的实例名
现象:使用sys通过oracle net登录报密码错误
sqlplus sys/123456@10.40.16.120:1521/orcltest as sysdba
- SQL*Plus: Release 11.2.0.4.0 Production on Tue Mar 17 13:57:52 2020Copyright (c) 1982, 2013, Oracle. All rights reserved.ERROR:ORA-01017: invalid username/password; logon deniedEnter user-name:
修复:使用自带工具orapwd重新生成密码文件
- orapwd file=$ORACLE_HOME/dbs/orapworcltest password=123456 force=y // force=y如果原密码文件存在,强制覆盖
参数文件损坏
文件说明:这里所说的参数文件指的是spfile,该文件存储的是实例启动的参数和控制文件的路径
模拟故障:清空该文件
- echo '' > $ORACLE_HOME/dbs/spfileorcltest.ora
现象:修改数据库参数时会报错
- SQL> alter system set open_cursors=400;alter system set open_cursors=400*ERROR at line 1:ORA-01565: error in identifying file'/u01/app/oracle/product/11.2.0/db_1/dbs/spfileorcltest.ora'ORA-27046: file size is not a multiple of logical block sizeAdditional information: 1
修复:使用rman还原参数文件
- RMAN> list backup of spfile;BS Key Type LV Size Device Type Elapsed Time Completion Time------- ---- -- ---------- ----------- ------------ ---------------22 Full 9.73M DISK 00:00:02 17-MAR-20BP Key: 22 Status: AVAILABLE Compressed: NO Tag: TAG20200317T133602Piece Name: /home/oracle/backupdir/c-2750922031-20200317-00SPFILE Included: Modification time: 17-MAR-20SPFILE db_unique_name: ORCLTEST
- RMAN> restore spfile to '/home/oracle/spfileorcltest.ora' from '/home/oracle/backupdir/c-2750922031-20200317-00';
- mv /home/oracle/spfileorcltest.ora /u01/app/oracle/product/11.2.0/db_1/dbs/
- SQL> shutdown immediate
- SQL> startup
注意在还原spfile的时候如果还原到spfile原先的位置,会报ORA-32011: cannot restore SPFILE to location already being used by the instance
所以需要还原到一个新的路径,然后手工移过去
PS:参数文件也可以从内存中直接创建一个新的,更省事(create spfile='/home/oracle/spfileorcltest.ora' from memory;)
控制文件损坏
文件说明:控制文件记录数据库文件的信息和日志的信息等
查看控制文件
- SQL> show parameter control_files
- NAME TYPE VALUE
- ------------------------------------ ----------- ------------------------------
- control_files string /u01/app/oracle/oradata/orclte
- st/control01.ctl
模拟故障:将该文件清空
- echo '' > /u01/app/oracle/oradata/orcltest/control01.ctl
现象:前台正常的增删改查不受影响,但一旦出现切换日志或产生检查点时数据库宕机
- SQL> alter system switch logfile;alter system switch logfile*ERROR at line 1:ORA-03113: end-of-file on communication channelProcess ID: 3433Session ID: 1 Serial number: 5
数据库alert日志
- Tue Mar 17 17:39:06 2020Errors in file /u01/app/oracle/diag/rdbms/orcltest/orcltest/trace/orcltest_ckpt_3415.trc:ORA-00202: control file: '/u01/app/oracle/oradata/orcltest/control01.ctl'ORA-27072: File I/O error...LGWR (ospid: 3413): terminating the instance due to error 227Tue Mar 17 17:40:37 2020System state dump requested by (instance=1, osid=3413 (LGWR)), summary=[abnormal instance termination].System State dumped to trace file /u01/app/oracle/diag/rdbms/orcltest/orcltest/trace/orcltest_diag_3403_20200317174037.trcDumping diagnostic data in directory=[cdmp_20200317174037], requested by (instance=1, osid=3413 (LGWR)), summary=[abnormal instance termination].Instance terminated by LGWR, pid = 3413
可以看到ckpt这个进程最先发现控制文件损坏了,实例之后被lgwr进程杀掉。可能大家在做实验的时候发现实例是被ckpt杀掉,这也是有可能的,反正可以肯定的一点是,实例最后肯定会挂掉
修复:使用rman还原控制文件
- rman target /
- RMAN> startup nomount
- RMAN> restore controlfile from '/home/oracle/backupdir/c-2750922031-20200317-00';
- RMAN> alter database mount;
- RMAN> recover database; // 这一步其实是使用archivedlog + redolog对控制文件进行恢复
- RMAN> alter database open resetlogs;
说明:
a. 不要使用删控制文件的方式去模拟该实验,这是由于ckpt、lgwr进程已经打开了控制文件,内存中已经有了这个控制文件的镜像,而rm命令并不能把这些进程已经打开的控制文件的句柄删掉。所以你会发现实例并没有挂掉。
b. 对数据库resetlogs之后,之前的备份就作废了,所以应该第一时间对数据库做一个全备。
c. 可能大家也注意到了,该实验中只有一个controlfile,当controlfile被破坏了之后,实例就挂了。如果是controlfile的多路复用,其中一个controlfile坏了数据库又是什么影响?我这里先说下我的结论:controlfile只要有一个坏了,实例就会奔溃,同时在alert日志中会提示具体是哪个controlfile损坏,解决办法就是复制一份好的controlfile去替换损坏的controlfile,重新启库即可。实验就留给大家自己做吧。附一段我实验的alert日志(ORA-00227: corrupt block detected in control file: (block 1, # blocks 1) ORA-00202: control file: '/u01/app/oracle/oradata/orcltest/control02.ctl')
总结:
1. 控制文件恢复不会丢失任何事务,但会要求数据库resetlogs,这将会导致之前的备份片无效,所以恢复控制文件后最好做一个全库备份。
2. 对控制文件最好设置两个,一个坏了还能利用另一个恢复,对数据库的影响和恢复的时间都是最小的。
数据文件损坏
为了继续实验,请手工删除之前所有的归档日志和备份文件,并对现在的数据库做一个全备
- RMAN> backup database; // 全库备份
6.1 普通数据文件损坏
模拟故障:将该文件清空
echo '' > /u01/app/oracle/oradata/orcltest/tbs01.dbf // tbs01是一个普通表空间数据文件
现象:查询该数据文件上的对象报错
- SQL> select * from scott.t01; // t01表在tbs01.dbf文件上select * from scott.t01 *ERROR at line 1:ORA-01115: IO error reading block from file (block # )ORA-01110: data file 6: '/u01/app/oracle/oradata/orcltest/tbs01.dbf'ORA-27072: File I/O errorAdditional information: 4Additional information: 130
修复:先对数据文件offline,然后使用rman还原恢复,最后online
- SQL> alter database datafile 6 offline;RMAN> restore datafile 6;RMAN> recover datafile 6; SQL> alter database datafile 6 online;
6.2 system表空间数据文件损坏
模拟故障:将该文件清空
- echo '' > /u01/app/oracle/oradata/orcltest/system01.dbf
现象:查询数据字典报错
- SQL> select * from dba_users;select * from dba_users *ERROR at line 1:ORA-00604: error occurred at recursive SQL level 1ORA-01115: IO error reading block from file (block # )ORA-01110: data file 1: '/u01/app/oracle/oradata/orcltest/system01.dbf'ORA-27072: File I/O errorAdditional information: 4Additional information: 95524
修复:先关库,然后使用rman还原恢复,最后启库
- SQL> shutdown abortSQL> startup mountRMAN> restore datafile 1;RMAN> recover datafile 1; SQL> alter database open;
6.3 sysaux和undo表空间数据文件损坏
sysaux表空间的文件损坏处理手段与普通表空间数据文件损坏处理手段相同,undo表空间的文件损坏处理手段与system表空间数据文件损坏处理手段相同,因为undo表空间的数据文件也不能offline。限于篇幅省略实验步骤,仅贴出文件损坏的现象。
sysaux表空间文件损坏现象:访问sysaux表空间的对象报错
- SQL> select * from sys.WRI$_OPTSTAT_HISTHEAD_HISTORY;
- ERROR:
- ORA-01578: ORACLE data block corrupted (file # 2, block # 986)
- ORA-01110: data file 2: '/u01/app/oracle/oradata/orcltest/sysaux01.dbf'
undo表空间文件损坏现象:所有修改操作全部报错
- SQL> insert into scott.t01 select * from scott.t01;insert into scott.t01 select * from scott.t01 *ERROR at line 1:ORA-00603: ORACLE server session terminated by fatal errorORA-01578: ORACLE data block corrupted (file # 3, block # 144)ORA-01110: data file 3: '/u01/app/oracle/oradata/orcltest/undotbs01.dbf'ORA-01578: ORACLE data block corrupted (file # 3, block # 144)ORA-01110: data file 3: '/u01/app/oracle/oradata/orcltest/undotbs01.dbf'Process ID: 2835Session ID: 20 Serial number: 85
日志文件损坏
7.1 inactive或active日志文件损坏
查看当前日志状态:current-当前正在写入的日志组,active-还未归档的日志组,inactive-已归档的日志组
- SQL> select a.group#, a.member, b.status from v$logfile a, v$log b where a.group#=b.group# order by group#;
- GROUP# MEMBER STATUS
- ---------- -------------------------------------------------- ------------
- 1 /u01/app/oracle/oradata/orcltest/redo01.log INACTIVE
- 2 /u01/app/oracle/oradata/orcltest/redo02.log CURRENT
- 3 /u01/app/oracle/oradata/orcltest/redo03.log INACTIVE
模拟故障:将inactive日志文件清空
- echo '' > /u01/app/oracle/oradata/orcltest/redo03.log
现象:当数据库切换到该日志组时,数据库并不知道磁盘上的日志文件有问题,只是将内容写到日志文件在内存的拷贝中,等到切换的时候,日志文件落盘就会发现该日志是有问题的,然后alert日志出现报错,不过不影响数据库正常运行,只是以后数据库切换日志会跳过该日志组
- SQL> insert into scott.t01 select * from scott.t01; // 重复对一张表进行插入,模拟产生大量的日志
观察alert日志
- Errors in file /u01/app/oracle/diag/rdbms/orcltest/orcltest/trace/orcltest_arc0_9006.trc:
- ORA-00313: open failed for members of log group 3 of thread 1
- ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcltest/redo03.log'
- ORA-27048: skgfifi: file header information is invalid
- Additional information: 12
- Master archival failure: 313
- SQL> alter system switch logfile;
查看v$log,可以看到group 3一直没有被用到
修复:将该日志文件重新初始化
- SQL> alter database clear unarchived logfile group 3; // active的日志损坏也是类似处理,使用该命令后数据库归档会断,所以在恢复日志组后,应立即进行全库备份。
7.2 current日志文件损坏
为了继续实验,请手工删除之前所有的归档日志和备份文件,并对现在的数据库做一个全备
- RMAN> backup database; // 全库备份
查看当前日志状态
- SQL> select a.group#, a.member, b.status from v$logfile a, v$log b where a.group#=b.group# order by group#; GROUP# MEMBER STATUS---------- -------------------------------------------------- ------------1 /u01/app/oracle/oradata/orcltest/redo01.log INACTIVE2 /u01/app/oracle/oradata/orcltest/redo02.log INACTIVE3 /u01/app/oracle/oradata/orcltest/redo03.log CURRENTSQL> create table scott.t02 as select * from dba_users;
模拟故障:current日志文件清空
- echo '' > /u01/app/oracle/oradata/orcltest/redo03.log
现象:前台正常的增删改查不受影响,但一旦出现切换日志数据库宕机
- SQL> create table scott.t03 as select * from dba_users;SQL> alter system switch logfile;alter system switch logfile*ERROR at line 1:ORA-03113: end-of-file on communication channelProcess ID: 3758Session ID: 1 Serial number: 9
查看alert日志
- Errors in file /u01/app/oracle/diag/rdbms/orcltest/orcltest/trace/orcltest_lgwr_8969.trc:
- ORA-00316: log 2 of thread 1, type 0 in header is not log file
- ORA-00312: online log 2 thread 1: '/u01/app/oracle/oradata/orcltest/redo02.log'
- LGWR (ospid: 8969): terminating the instance due to error 316
- Instance terminated by LGWR, pid = 3458
恢复:使用不完全恢复打开
- sqlplus / as sysdba
- SQL> startup mount
- SQL> recover database until cancel; // 不完全恢复
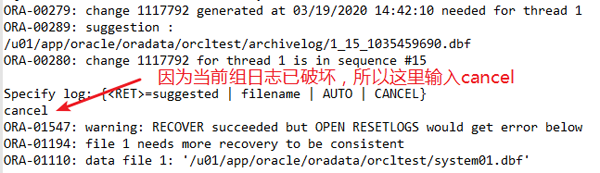
- SQL> alter database open resetlogs; // 会发现启库失败alter database open resetlogs*ERROR at line 1:ORA-01194: file 1 needs more recovery to be consistentORA-01110: data file 1: '/u01/app/oracle/oradata/orcltest/system01.dbf'
这个时候就需要加入隐含参数,再启动
- SQL> alter system set "_allow_resetlogs_corruption"=true scope=spfile; SQL> shutdown abortSQL> startup mountSQL> recover database until cancel; // 不完全恢复输入cancelSQL> alter database open resetlogs;
说明:
a. 使用该方式恢复的库,可能会造成数据的丢失,而且也并不能保证一定成功。
b. 恢复成功后,应将表全部使用expdp导出,重建库。
c. 上面的实验每个日志组都只有一个member,如果每个日志组有两个member又是什么样子呢?
先说下我的结论:损坏其中任何一个member对数据库没什么影响,只是在切换到有member损坏的日志组时,会在alert日志中提示告警ORA-00313 ORA-00312 ORA-27048,解决办法就是删掉这个member,重新添加,不需要对数据库进行重启,实验过程我就不展示了。所以最好是每组日志中设置2个成员。
这儿我有个疑问想不通:对inactive的日志进行破坏,数据库切换到这个被破坏的日志时,数据库正常写,只是在日志切换的时候报错,这个能理解,因为系统内存中有这个被破坏的日志之前的拷贝,所有的写可能都是在内存中。切换的时候该日志文件就必须要落盘,所以提示报错。而对current的日志进行破坏,数据库也正常写,但是在日志切换的时候数据库直接崩了。没弄懂这两个为什么会有这个区别。
总结
1. 生产中应制定好备份策略
2. 控制文件和日志文件最好是设置大于一个成员
3. 当前日志组损坏最为致命,如果日志写很繁忙,可以只为日志文件配置一个成员,但同时需要配置一个dataguard,方便切换
4. 此博客仅为个人理解,如有不对的地方,欢迎大家指出