













本文转载自公众号“读芯术”(ID:AI_Discovery)
人工智能(AI)和机器学习(ML)已然“渗透”到了各行各业,企业们期待通过机器学习基础架构平台,以推动人工智能在业务中的利用。
理解各种平台和产品算得上是一项挑战。机器学习基础架构空间拥挤、混乱又复杂。许多平台和工具涵盖了整个模型构建工作流程的多种功能。
为了理解其生态,我们可将机器学习工作流程大致分为三个阶段:数据准备,模型构建和生产。了解工作流各个阶段的目标和挑战有助于人们正确地选出最适合企业业务需求的机器学习基础架构平台。

机器学习基础架构平台图
机器学习工作流程的每个主要阶段都具有许多垂直功能。其中一些功能是较大的端到端平台的一部分内容,还有一些功能则是某些平台的主要关注点。
本文将带你走进机器学习的第二阶段——模型构建。
什么是模型构建?
模型构建的第一步从了解业务需求开始。模型需要处理哪些业务需求?
这一步骤在机器学习工作流程的计划和构想阶段展开。在此阶段,与软件开发生命周期类似,数据科学家收集需求,考虑可行性,并为数据准备、模型构建和生产制定计划。他们还使用数据来探索各种模型构建实验,这些实验是在计划阶段所考虑的。
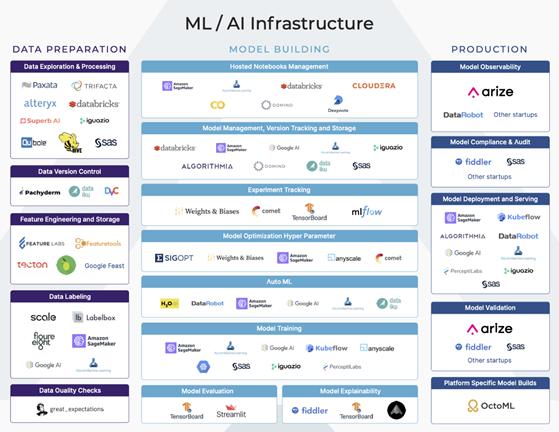
机器学习基础架构平台图
特征探索和选择
数据科学家探索各种数据输入选项以选择特征,是该实验过程的一部分。特征选择是为机器学习模型查找特征输入的过程。
对于新模型,理解可用的数据输入、输入的重要性以及不同特征之间的关系可能是一个漫长的过程。在这里,可以对更易解释的模型、更短的训练时间、特征获取的成本以及过度拟合的减轻做出许多决策。找出正确且合适的特征是一个连续不断的迭代过程。
- 在特征提取方面的机器学习基础架构公司有:Alteryx/ Feature实验室、Paxata(DataRobot)。
模型管理
数据科学家可以尝试多种建模方法。对于某些任务,一些类型的模型比其他模型更适用(例如,基于树的模型解释性更佳)。
作为构思阶段的一部分,该模型是监督、无监督、分类或回归等都是显而易见的。但建模方法、超参数以及特征的选择取决于实验。
一些自动机器学习(AutoML)平台会尝试附带各种参数的不同模型,这有助于建立基线方法。即使手动完成,探索各种选项也可以为模型构建者提供有关模型可解释性的见解。
实验跟踪
尽管各种类型的模型之间有许多优点和折衷点,但通常来说,此阶段涉及许多实验。许多平台可以跟踪这些实验、建模依赖和模型存储。这些功能可被大致归为模型管理。
一些平台主要关注实验跟踪。其他一些具有训练或服务组件的公司拥有模型管理组件,用于比较各种模型的性能,跟踪训练/测试数据集,调整和优化超参数,存储评估指标以及实现详细的沿袭和版本控制。
与用于软件的Github相似,这些模型管理平台应能实现版本控制、历史沿袭和可重复性。
各种模型管理平台之间的折衷在于集成成本。一些更轻量级的平台虽然仅提供实验跟踪,但可以轻松地与当前环境集成,并导入到数据科学notebook中。其他一些平台则需要进行更繁重的集成,并且需要模型构建者转移至其平台上,以便进行集中的模型管理。
在机器学习工作流程的这一阶段,数据科学家通常要花时间在notebook中建立、训练模型,将模型权重存储在模型库中,然后在验证集上评估模型结果。
这一阶段有许多平台提供训练所需的计算资源。根据团队存储模型对象的不同方式,模型还具备许多存储选项。
- 机器学习基础架构AutoML:H20、SageMaker、DataRobot、Google Cloud ML、MicrosoftML
- 模型管理方面的机器学习基础架构公司:Domino Data Labs、SageMaker
- 超参数选项方面的机器学习基础架构公司:Sigopt、Weightsand Biases、SageMaker
- 实验跟踪方面的机器学习基础架构公司:权重和偏差、Comet ML、MLFlow、Domino、Tensorboard
模型评估
一旦实验模型在具有选定特征的训练数据集上经过训练,就可以在测试集上进行评估了。
在这一阶段,数据科学家试图了解模型的性能以及需要改进的地方。一些更高级的机器学习团队拥有自动回测框架,可供其利用历史数据来评估模型性能。
每个实验都试图击败或超越基准模型的性能,并考虑如何对计算成本、可解释性和归纳能力做出权衡。在一些更规范的行业中,此评估过程还可以包括外部审核员执行的合规性和审核,以确保模型的可重复性、性能和需求。
- 用于模型评估的机器学习基础工具/架构:Fiddler AI、Tensorboard、Stealth Startups
- 用于试生产验证的机器学习基础架构:Fiddler AI、ArizeAI
管理以上所有任务的平台
许多以AutoML或模型构建为中心的公司只选定一个平台,用以处理一切事物。因此许多平台争相成为公司在数据准备、模型构建和生产中使用的唯一人工智能平台,这样的公司有DataRobot、H20、SageMaker等。
该集合分为低代码解决方案和以开发人员为中心的解决方案。Datarobot公司似乎专注于无代码/低代码选项,该选项允许商务智能(businessintelligence, BI)或财务(Finance)团队从事数据科学项目。
这与SageMaker和H20公司形成鲜明对比,它们似乎迎合了当今更为常见的数据科学组织——数据科学家或开发者第一团队。
这两种情况下的市场都很大,并且可以共存,但值得注意的是,并非所有的机器学习基础架构公司都向相同的人或团队出售产品。
近期,该领域中的许多新成员可以被视为机器学习基础架构食物链中特定部分的优秀解决方案。比较好的模拟将是软件工程领域,其软件解决方案GitHub、集成开发环境(IDE)以及生产监控并非都是相同的端到端系统。
它们是不同的软件,这一点并非空穴来风,它们提供了迥然不同的功能,并且具有明显的区别。
挑战
与软件开发并行不同的是,由于缺乏对模型所训练数据的版本控制,模型的可重复性通常被视为一个挑战。
在理解模型的性能方面存在许多挑战。如何比较实验并确定哪种模型版本是性能和折衷的优质平衡?稍差的模型是一种折衷方案,但它更易于解释。一些数据科学家使用内置的模型可解释性特征或使用SHAP/ LIME,来探索特征的重要性。
另一性能挑战是不知道实验阶段的模型性能如何转化到现实世界中。
通过确保训练数据集中的数据是模型在生产中可能看到的数据的代表性分布,以防止过度拟合训练数据集,可以很大程度地缓解这种情况。这是交叉验证和回测框架发挥作用之处。
接下来发生了什么?
对数据科学家来说,确定何时将模型投入生产的标准是很重要的。如果生产环境中已部署了预先存在的模型,则可能是新版本的性能更高的时候。无论如何,设置标准对于将实验转移至实际环境中至关重要。
一旦模型受过训练,模型图像/权重将存储在模型库中。这时,负责将模型部署到生产中的数据科学家或工程师通常可以获取模型并用于服务。
在一些平台上,该部署甚至可以更简单,并且可以使用外部服务能调用的RESTAPI来配置已部署的模型。




















