












这几天在尝试手撸一个类似Lombok的注解式代码生成工具,用过Lombok的小伙伴知道,Lombok可以通过注解自动帮我们生产equals()和hashCode()方法,因此我也想实现这个功能,但是随着工作的深入,我发现其实自己对于equals()和hashCode()的理解,也处在一个很低级的阶段。
因此痛定思痛,进行了一番深入学习,才敢来写这篇博客。
1、equals在Java中含义
首先要解释清楚这个,equals方法在Java中代表逻辑上的相等,什么叫逻辑上的相等?这个就涉及到Java本身的语法特性。
我们知道,Java中存在着==来判断基本数据类型的相等,但是对于对象,==只能判断内存地址是否相等,也就是说是否是同一个对象:
- int a = 10000;
- int b = 10000;
- // 对于基本数据类型, == 可以判断逻辑上的相等
- System.out.println(a == b);
- Integer objA = 10000;
- Integer objB = 10000;
- Integer objAobjA1 = objA;
- // 对于类实例, == 只能判断是否为同一个实例(可以视为内存地址是否相等)
- System.out.println(objA == objB);
- System.out.println(objA == objA1);
注:这里我们不讨论Integer对于-128~127的缓存机制。
结果显而易见:
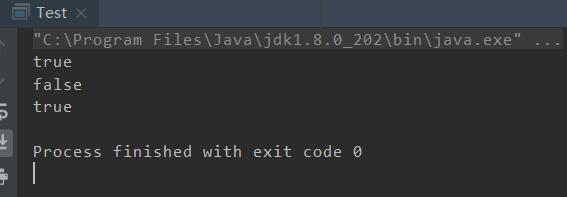
但是明明 objA和objB逻辑上是相等的,凭什么你就返回false?这时就诞生了一种需求,对于Java中的对象,要判断逻辑相等,该怎么实现呢,于是就出现了equals()方法。
- Integer objA = 10000;
- Integer objB = 10000;
- Integer objAobjA1 = objA;
- // 对于对象实例, equals 可以判断两个对象是否逻辑相等
- System.out.println(objA.equals(objB));
Integer类已经重写了equals()方法,所以结果也显而易见:
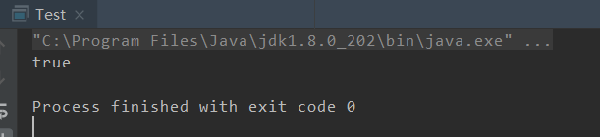
因此如果我们自己创建一个类的话, 要实现判断两个实例逻辑上是否相等,就需要重写他的equals()方法。
- // 重写了equals方法的类
- static class GoodExample {
- private String name;
- private int age;
- public GoodExample(String name, int age) {
- this.name = name;
- this.age = age;
- }
- @Override
- public boolean equals(Object o) {
- if (this == o) return true;
- if (o == null || getClass() != o.getClass()) return false;
- GoodExample that = (GoodExample) o;
- return age == that.age &&
- Objects.equals(name, that.name);
- }
- }
- // 没有重写euqals方法的类
- static class BadExample {
- private String nakeName;
- private int age;
- public BadExample(String nakeName, int age) {
- this.nakeName = nakeName;
- this.age = age;
- }
- }
- public static void main(String[] args) {
- System.out.println(new GoodExample("Richard", 36).
- equals(new GoodExample("Richard", 36)));
- System.out.println(new BadExample("Richard", 36).
- equals(new BadExample("Richard", 36)));
- }
相信你已经知道结果是什么了:
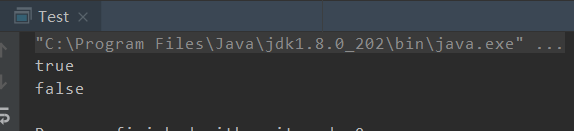
2、hashCode在Java中的作用
网上有很多博客都把hashCode()和equals()混为一谈,但实际上hashCode()就是他的字面意思,代表这个对象的哈希码。
但是为什么JavaDoc明确的告诉我们,hashCode()和equals()要一起重写呢?原因是因为,在Java自带的容器HashMap和HashSet中,都需同时要用到对象的hashCode()和equals()方法来进行判断,然后再插入删除元素,这点我们一会再谈。
那么我们还是单独来看hashCode(),为什么HashMap需要用到hashCode?这个就涉及到HashMap底层的数据结构 – 散列表的原理:
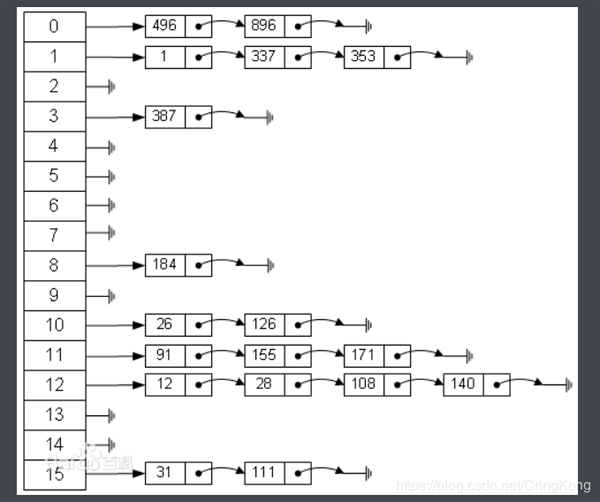
HashMap底层用于存储数据的结构其实是散列表(也叫哈希表),散列表是通过哈希函数将元素映射到数组指定下标位置,在Java中,这个哈希函数其实就是hashCode()方法。
举个例子:
- HashMap<String,GoodExample> map = new HashMap<>();
- map.put("cringkong",new GoodExample("jack",10));
- map.put("cricy",new GoodExample("lisa",12));
- System.out.println(map.get("cricy"));
在存入HashMap的时候,HashMap会用字符串"cringkong"和"cricy"的hashCode()去映射到数组指定下标位置,至于怎么去映射,我们一会再说。
好了,现在我们明白了hashCode()为什么被设计出来,那么我们来进行一个实验:
- // 科学设计了hashCode的类
- static class GoodExample {
- private String name;
- private int age;
- public GoodExample(String name, int age) {
- this.name = name;
- this.age = age;
- }
- @Override
- public int hashCode() {
- return Objects.hash(name, age);
- }
- }
- // 不科学的hashCode写法
- static class BadExample {
- private String nakeName;
- private int age;
- public BadExample(String nakeName, int age) {
- this.nakeName = nakeName;
- this.age = age;
- }
- @Override
- public int hashCode() {
- // 这里我们没有用
- return nakeName.hashCode();
- }
- }
这里我们存在两个类,GoodExample类通过类全部字段进行hash运算得到hashCode,而BadExample只通过类的一个字段进行hash运算,我们来看一下得到的结果:
- System.out.println(new GoodExample("李老三", 22).hashCode());
- System.out.println(new GoodExample("李老三", 42).hashCode());
- System.out.println(new BadExample("王老五", 50).hashCode());
- System.out.println(new BadExample("王老五", 25).hashCode());
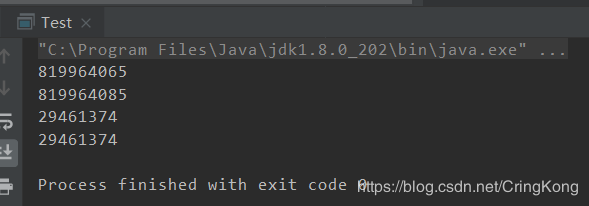
可以看到,GoodExample的hashCode()标明了22岁和42岁的李老三是不同的,而BadExample却认为50岁和25岁的王老五没什么区别。
那么也就是说在HashMap中,两个李老三会被放到不同的数组下标位置中,而两个王老五会被放到同一个数组下标位置上。
PS : hashCode相等的两个对象不一定逻辑相等,逻辑相等的两个对象hashCode必须相等!
3、为什么hashCode和equals要一起重写
刚刚我们知道,equals()是用来判断对象是否逻辑相等,hashCode()就是获得一个对象的hash值,同时再HashMap中用来得到数组下标位置。
那么为什么很多地方都说到,hashCode()和equals()要一起重写呢?明明通过对象hashCode就可以定位数组下标了啊,那我们直接用把对象存进去取出来不就行了吗?
答案是这样的:设计再良好的哈希函数,也会出现哈希冲突的情况,什么是哈希冲突呢?举个例子来说,我设计了这样一种哈希函数:
- /**
- * 硬核哈希函数,哈希规则是 传入的字符串的首位字符转换成ASCII值
- *
- * @param string 需要哈希的字符串
- * @return 字符串的哈希值
- */
- private static int hardCoreHash(String string) {
- return string.charAt(0);
- }
我们来测试一下硬核哈希函数的哈希效果:
- System.out.println(hardCoreHash("fish"));
- System.out.println(hardCoreHash("cat"));
- System.out.println(hardCoreHash("fuck"));
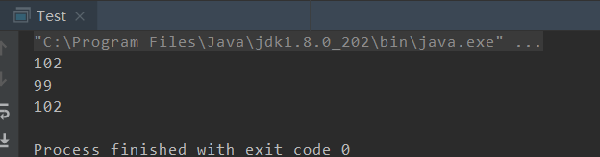
可以看到, "fish" 和 "fuck"出现了哈希冲突,这是我们不想看到的,一旦出现了哈希冲突,我们的哈希表就需要解决哈希冲突,一般解方式有:
- 开发定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
这都是数据结构课本上的东西,我就不再细讲了,不懂的同学自行搜索!
就像我之前说的,设计再精良的哈希函数,也会有哈希冲突的情况出现,Java中的hashCode()本身就是一种哈希函数,必然会出现哈希冲突,更怕一些程序员写出某些硬核哈希函数。
既然存在哈希冲突,我们就得解决,HashMap采用的是链地址法来解决:(偷张图…
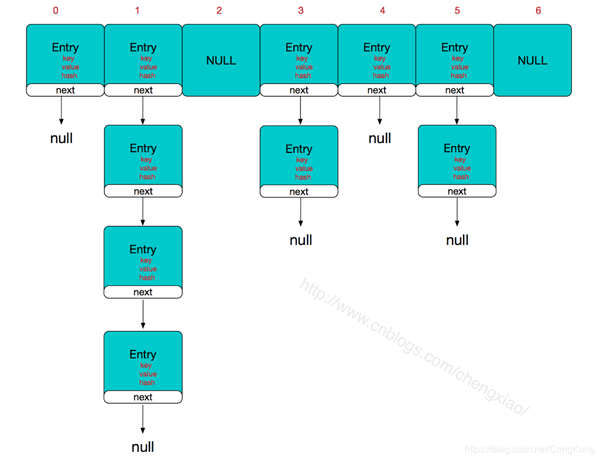
这里就存在一种极端情况,如何判断是究竟是两个 逻辑相等的对象重复写入,还是两个逻辑不等的对象出现了哈希冲突呢?
很简单,用equals()方法判断不就完事了吗,我们之前说了,equals()方法就是用来设计判断两个对象是否逻辑相等的啊!
我们来看一段HashCode简单的取出key对应value的源码:
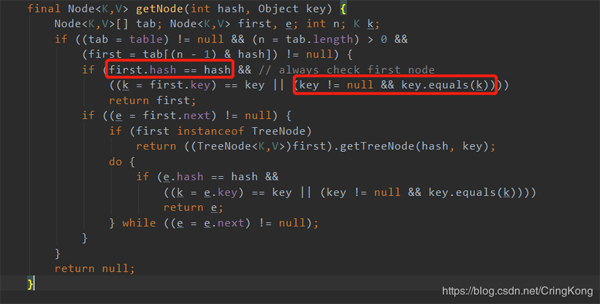
意思很简单,先判断这key的 hashCode是否相等,如果不相等,说明key和数组中对象一定逻辑不相等,就不用再判断了,如果相等,就继续判断是否逻辑相等,从而确定究竟是出现了哈希冲突,还是确实就是要取这个key的对应的值。
所以说到这里,你应该明白为什么千叮咛万嘱咐equals()和hashCode()要一块重写了吧。如果这个类的对象要作为HashMap的key,或者要存入HashSet,是必两个方法都要重写的,其他情况可以自行斟酌,但是为了安全方便不出错,就直接一块重写了吧。
4、扩展:实现科学的哈希函数
说的科学的哈希函数,就不得不说经典的字符串哈希函数:DJB hash function俗称Times33的哈希函数:
- unsigned int time33(char *str){
- unsigned int hash = 5381;
- while(*str){
- hash += (hash << 5 ) + (*str++);
- }
- return (hash & 0x7FFFFFFF);
- }
这个函数的实现思路,就是不断地让当前的哈希值乘33(左移5位相当于乘上32,然后加上原值相当于乘上33),再加上字符串当前位置的值(ASCII),然后哈希值进入下一轮迭代,直到字符串的最后一位,迭代完成返回哈希值。
为什么说他科学?因为根据实验,这种方式的出来哈希值分布比较均匀,就是最小可能性出现哈希冲突,同时计算速度也比较快。
至于初始值5381怎么来的?也是实验找到的比较科学的一个数。(怎么感觉说的跟废话一样?)
那么Java中的hashCode()有没有默认实现呢?当然有:
- // Object类中的hashCode函数,是一个native方法,JVM实现
- public native int hashCode();
Object类作为所有类的父类,实现了native方法,是一个本地方法,JVM实现我们看不到。
而String类,则默认重写了hashCode方法,我们看一下实现:
- public int hashCode() {
- // 初始值是0
- int h = hash;
- if (h == 0 && value.length > 0) {
- char val[] = value;
- // 31作为乘子,是不是应该叫Timers31呢?
- for (int i = 0; i < value.length; i++) {
- h = 31 * h + val[i];
- }
- hhash = h;
- }
- return h;
- }
可以看到,Java选择了31作为乘子,这也是有他的道理的,根据 Effective Java所说:
选择数字31是因为它是一个奇质数,如果选择一个偶数会在乘法运算中产生溢出,导致数值信息丢失,因为乘二相当于移位运算。选择质数的优势并不是特别的明显,但以往的哈希算法都这样做。同时,数字31有一个很好的特性,即乘法运算可以被移位和减法运算取代,来获取更好的性能:31 * i == (i << 5) - i,现代的 Java 虚拟机可以自动的完成这个优化。
总结一下其实就是两点原因:
- 奇质数作为哈希运算中的乘法因子,得到的哈希值效果比较好(分布均匀)
- JVM对于位运算的优化,最后选择31是因为速度比较快
说这么多,还是实验出来的结果,Java开发人员认为这个数比较适合JVM平台。
当然也有大哥做了实验:科普:为什么 String hashCode 方法选择数字31作为乘子
有兴趣的小伙伴可以去看看。
而且Java本身也提供了一个工具类,就是之前我用到的java.util.Objects.hash()方法,我们来下他的实现方式:
- public static int hashCode(Object a[]) {
- if (a == null)
- return 0;
- int result = 1;
- // 对于传入的所有对象都进行一次Timers31
- for (Object element : a)
- // 同时用到了每个对象的hashCode()方法
- result = 31 * result + (element == null ? 0 : element.hashCode());
- return result;
- }
总体思路还是一样的。






















