作者:deryzhou,腾讯 PCG 后台开发工程师
Go 中怎么实现内存池,直接用 map 可以吗?常用库里 GroupCache、BigCache 的内存池又是怎么实现的?有没有坑?对象池又是什么?想看重点的同学,可以直接看第 2 节 GroupCache 总结。
0. 前言: tcmalloc 与 Go
以前 C++服务上线,遇到性能优化一定会涉及 Google 大名鼎鼎的 tcmalloc。
相比 glibc,tcmalloc 在多线程下有巨大的优势:
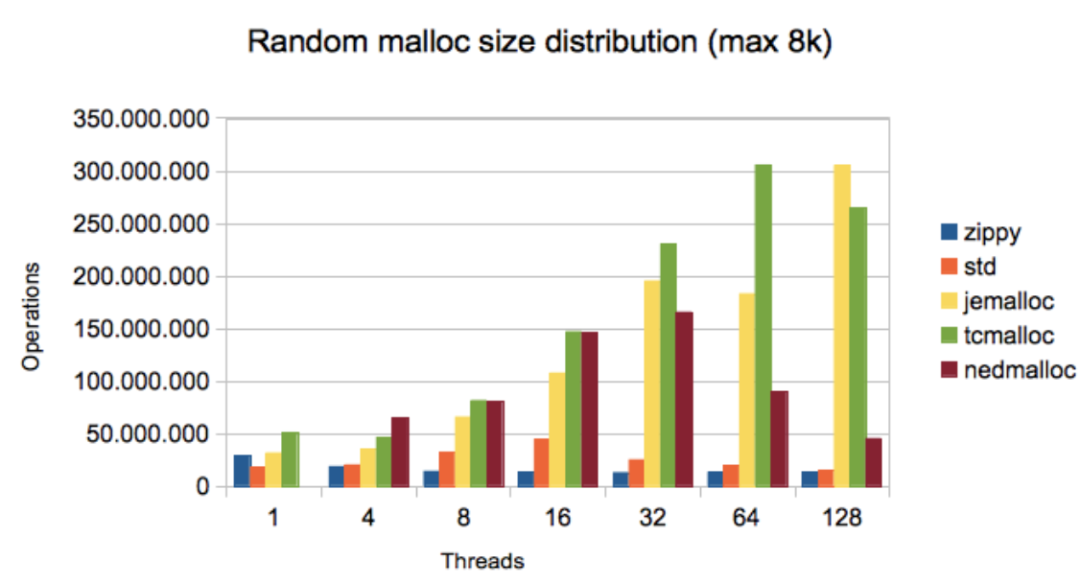
vs tcmalloc
其中使用的就是内存池技术。如果想了解 tcmalloc 的细节,盗一张图解 TCMalloc中比较经典的结构图:
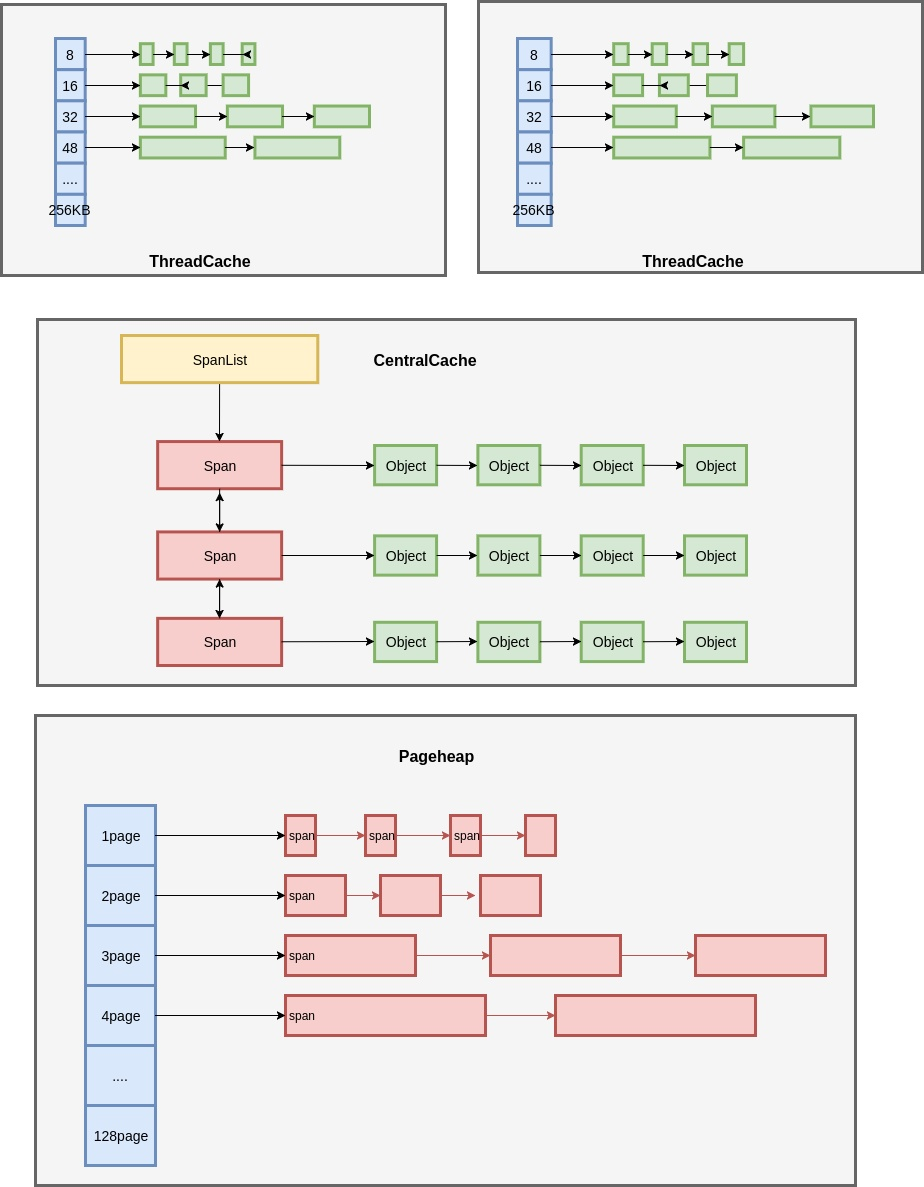
图解 TCMalloc
作为 Google 的得意之作,Golang自然也用上了 tcmalloc 的内存池03 技术。因此我们普通使用 Golang 时,无需关注内存分配的性能问题。
1. 关于 map 你需要了解的
既然 Go 本身内存已经做了 tcmalloc 的管理,那实现缓存我们能想到的就是 map 了,是吧?(但仔细想想,map 不需要加锁吗?不加锁用 sync.Map 更好吗)
坑 1: 为什么不用 sync.Map
2020-05-09 补充:多位同学也提到了,bigcache 这个测试并不公平。查了下 issues,map+lock 和 sync.Map 的有人做过测试,性能确实低一些(单锁的情况)https://github.com/golang/go/issues/28938#issuecomment-441737879但如果是 shards map+lock 和 sync.Map,在不同的读写比(比如读多写少,当超时才更新)时,这块就不好判断哪种实现更优了,有兴趣的同学可以尝试深挖下(而且 doyenli 也提到,sync.Map 内部是 append only 的)
用过 map 的同学应该会知道,map 并不是线程安全的。多个协程同步更新 map 时,会有概率导致程序 core 掉。
那我们为什么不用sync.Map?当然不是因为 go 版本太老不支持这种肤浅原因。
https://github.com/allegro/bigcache-bench 里有张对比数据,纯写 map 是比 sync.Map 要快很多,读也有一定优势。考虑到多数场景下读多写少,我们只需对 map 加个读写锁,异步写的问题就搞定了(还不损失太多性能)。
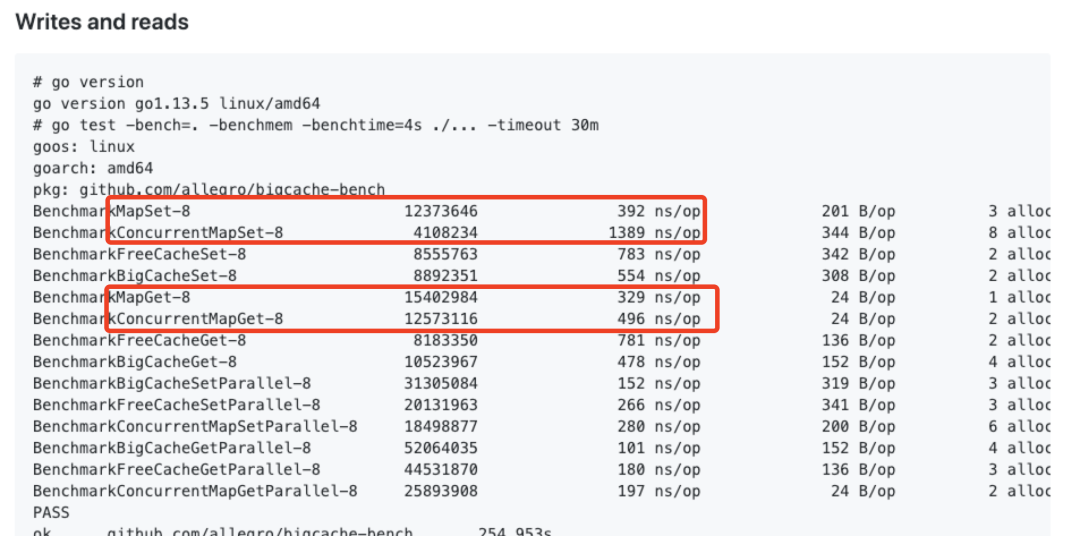
map vs sync.Map
除了读写锁,我们还可以使用 shard map 的分布式锁来继续提高并发(后面 bigcache 部分会介绍),所以你看最终的 cache 库里,大家都没用 sync.Map,而是用map+读写锁来实现存储。
坑 2: 用 map 做内存池就可以了?
并不能。map 存储 keys 也是有限制的,当 map 中 keys 数量超过千万级,有可能造成性能瓶颈。
这个是我在之前业务中实际遇到的情况,当时服务里用了 GroupCache 做缓存,导致部分线上请求会超时(0.08%左右的超时率)。我们先暂时放下这个问题,弄清原因再来介绍这里的差异。
找了下资料,发现 2014 年 Go 有个 issue 提到 Large maps cause significant GC pauses 的问题。简单来说就是当 map 中存在大量 keys 时,GC 扫描 map 产生的停顿将不能忽略。
好消息是 2015 年 Go 开发者已经对 map 中无指针的情况进行了优化:
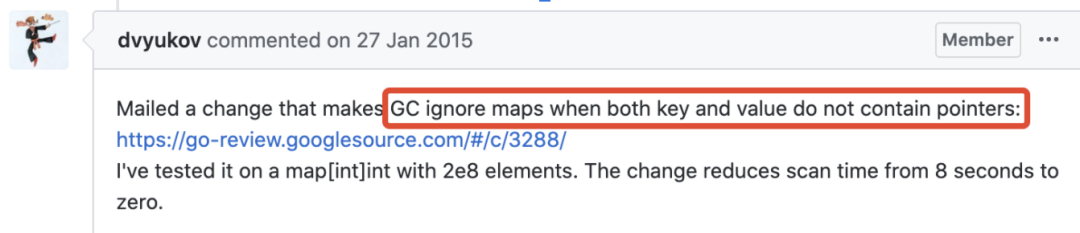
GC ignore maps with no pointers
我们参考其中的代码,写个GC 测试程序验证下:
- package main
- import (
- "fmt"
- "os"
- "runtime"
- "time"
- )
- // Results of this program on my machine:
- //
- // for t in 1 2 3 4 5; do go run maps.go $t; done
- //
- // Higher parallelism does help, to some extent:
- //
- // for t in 1 2 3 4 5; do GOMAXProcS=8 go run maps.go $t; done
- //
- // Output(go 1.14):
- // With map[int32]*int32, GC took 456.159324ms
- // With map[int32]int32, GC took 10.644116ms
- // With map shards ([]map[int32]*int32), GC took 383.296446ms
- // With map shards ([]map[int32]int32), GC took 1.023655ms
- // With a plain slice ([]main.t), GC took 172.776µs
- func main() {
- const N = 5e7 // 5000w
- if len(os.Args) != 2 {
- fmt.Printf("usage: %s [1 2 3 4]\n(number selects the test)\n", os.Args[0])
- return
- }
- switch os.Args[1] {
- case "1":
- // Big map with a pointer in the value
- m := make(map[int32]*int32)
- for i := 0; i < N; i++ {
- n := int32(i)
- m[n] = &n
- }
- runtime.GC()
- fmt.Printf("With %T, GC took %s\n", m, timeGC())
- _ = m[0] // Preserve m until here, hopefully
- case "2":
- // Big map, no pointer in the value
- m := make(map[int32]int32)
- for i := 0; i < N; i++ {
- n := int32(i)
- m[n] = n
- }
- runtime.GC()
- fmt.Printf("With %T, GC took %s\n", m, timeGC())
- _ = m[0]
- case "3":
- // Split the map into 100 shards
- shards := make([]map[int32]*int32, 100)
- for i := range shards {
- shards[i] = make(map[int32]*int32)
- }
- for i := 0; i < N; i++ {
- n := int32(i)
- shards[i%100][n] = &n
- }
- runtime.GC()
- fmt.Printf("With map shards (%T), GC took %s\n", shards, timeGC())
- _ = shards[0][0]
- case "4":
- // Split the map into 100 shards
- shards := make([]map[int32]int32, 100)
- for i := range shards {
- shards[i] = make(map[int32]int32)
- }
- for i := 0; i < N; i++ {
- n := int32(i)
- shards[i%100][n] = n
- }
- runtime.GC()
- fmt.Printf("With map shards (%T), GC took %s\n", shards, timeGC())
- _ = shards[0][0]
- case "5":
- // A slice, just for comparison to show that
- // merely holding onto millions of int32s is fine
- // if they're in a slice.
- type t struct {
- p, q int32
- }
- var s []t
- for i := 0; i < N; i++ {
- n := int32(i)
- s = append(s, t{n, n})
- }
- runtime.GC()
- fmt.Printf("With a plain slice (%T), GC took %s\n", s, timeGC())
- _ = s[0]
- }
- }
- func timeGC() time.Duration {
- start := time.Now()
- runtime.GC()
- return time.Since(start)
- }
代码中一共测试了 5 种情况,写入5000w的 keys 后,主动触发 2 次 GC 来测量耗时:
- [1] With map[int32]*int32, GC took 456.159324ms
- [2] With map[int32]int32, GC took 10.644116ms
- [3] With map shards ([]map[int32]*int32), GC took 383.296446ms
- [4] With map shards ([]map[int32]int32), GC took 1.023655ms
- [5] With a plain slice ([]main.t), GC took 172.776µs
可以看到,当 map 中没有指针时,扫描停顿时间大约在 10ms 左右,而包含指针int32时则会扩大 45 倍。
先看 5 的数据,单纯的 slice 速度飞快,基本没有 GC 消耗。而 map shards 就有点耐人寻味了,为什么我们没有对 map 加锁,分 shard 后 GC 时间还是缩短了呢?说好的将锁分布式化,才能提高性能呢?
坑 3: shards map 能提高性能的元凶(原因)
要了解 shards map 性能变化的原因,需要先弄清楚 Golang GC 的机制。我们先加上GODEBUG=gctrace=1观察下 map 里包含指针与没有指针的 gc 差异:
map[]*int: gc 11 @11.688s 2%: 0.004+436+0.004 ms clock, 0.055+0/1306/3899+0.049 ms cpu, 1762->1762->1220 MB, 3195 MB goal, 12 P (forced)map[]int: gc 10 @9.357s 0%: 0.003+14+0.004 ms clock, 0.046+0/14/13+0.054 ms cpu, 1183->1183->746 MB, 2147 MB goal, 12 P (forced)
输出各字段含义可以看GODEBUG 之 gctrace 干货解析,这里我们只关注 cpu 里0.055+0/1306/3899+0.049 ms cpu 这段的解释:
- Mark Prepare (STW) - 0.055 表示整个进程在 mark 阶段 STW 停顿时间
- Marking - 0/1306/3899 三段信息,其中 0 是 mutator assist 占用时间,1306 是 dedicated mark workers+fractional mark worker 占用的时间,3899 是 idle mark workers 占用的时间(虽然被拆分为 3 种不同的 gc worker,过程中被扫描的 P 还是会暂停的,另外注意这里时间是所有 P 消耗时间的总和)
- Mark Termination (STW) - 0.049 表示整个进程在 markTermination 阶段 STW 停顿时间
只有 Mark 的前后两个阶段会导致 Stop-The-World(STW),中间 Marking 过程是并行的。这里 1306ms 是因为我们启动了 12 个 P,1306ms 和 3899ms 是所有 P 消耗时间的综合。虽然说是 Marking 是并行,但被扫描到的 P 还是会被暂停的。因此这个时间最终反映到业务程序上,就是某个 P 处理的请求,在 GC 时耗时突增(不稳定),不能被简单的忽略
那回到上面的问题了,shards map 的性能又是如何得到提升(近 10 倍)的?
- // With map[int32]int32, GC took 11.285541ms
- gc 1 @0.001s 7%: 0.010+2.1+0.012 ms clock, 0.12+0.99/2.1/1.2+0.15 ms cpu, 4->6->6 MB, 5 MB goal, 12 P
- ...
- gc 8 @2.374s 0%: 0.003+3.9+0.018 ms clock, 0.042+0.31/6.7/3.1+0.21 ms cpu, 649->649->537 MB, 650 MB goal, 12 P
- gc 9 @4.834s 0%: 0.003+7.5+0.021 ms clock, 0.040+0/14/5.1+0.25 ms cpu, 1298->1298->1073 MB, 1299 MB goal, 12 P
- gc 10 @9.188s 0%: 0.003+26+0.004 ms clock, 0.045+0/26/0.35+0.053 ms cpu, 1183->1183->746 MB, 2147 MB goal, 12 P (forced)
- gc 11 @9.221s 0%: 0.018+9.4+0.003 ms clock, 0.22+0/17/5.0+0.043 ms cpu, 746->746->746 MB, 1492 MB goal, 12 P (forced)
- // With map shards ([]map[int32]int32), GC took 1.017494ms
- gc 1 @0.001s 7%: 0.010+2.9+0.048 ms clock, 0.12+0.26/3.6/4.1+0.57 ms cpu, 4->7->6 MB, 5 MB goal, 12 P
- ...
- gc 12 @3.924s 0%: 0.003+3.2+0.004 ms clock, 0.040+1.2/7.5/14+0.048 ms cpu, 822->827->658 MB, 840 MB goal, 12 P
- gc 13 @8.096s 0%: 0.003+6.1+0.004 ms clock, 0.044+6.0/14/32+0.053 ms cpu, 1290->1290->945 MB, 1317 MB goal, 12 P
- gc 14 @11.619s 0%: 0.003+1.2+0.004 ms clock, 0.045+0/2.5/3.7+0.056 ms cpu, 1684->1684->1064 MB, 1891 MB goal, 12 P (forced)
- gc 15 @11.628s 0%: 0.003+0.91+0.004 ms clock, 0.038+0/2.3/3.6+0.057 ms cpu, 1064->1064->1064 MB, 21
从倒数第三轮内存最大的时候看,GC worker 的耗时都是接近的;唯一差异较大的,是 markTermination 阶段的 STW 时间,shard 方式下少了 1/10,因此推测和该阶段得到优化有关。
至于这个时间为什么能减少,我也不清楚为什么(这个坑挖得太深,只能以后找到资料再来填...)
2. GroupCache
言归正传(众人:什么?!前面写这么多你还没进入正文。我:咳..咳..),我们总结下用 map 实现内存池的要点:
- 内存池用 map 不用 sync.Map;map 要加读写锁
- map 尽量存非指针(key 和 value 都不包含指针)
- map 里存放指针,需要注意 keys 过多会带来的 GC 停顿问题
- 使用 shards map
然后我们看看GroupCache 的实现方法,这个定义在 lru/lru.go 里:
- // Cache is an LRU cache. It is not safe for concurrent access.
- type Cache struct {
- cache map[interface{}]*list.Element
- }
从 cache 的定义可以看出,这是我们说的 map 里包含指针的情况,而且还是不分 shards 的。所以如果你单机 GroupCache 里 keys 过多,还是要注意下用法的。
注:截止目前 1.14,map 里包含指针时 idle worker 耗时问题还未有结论,有兴趣可以参考10ms-26ms latency from GC in go1.14rc1, possibly due to 'GC (idle)' work 里面的例子和现象。
3. BigCache
相比分布式场景的 GroupCache,如果你本地依然有千万级的 keys,那推荐你用 bigcache。无数经验证明,超大 map 的内存池导致的 GC 延迟,是可以通过切 bigcache 解决的。那 bigcache 到底怎么做到的?
简单来说:shards map + map[uint]uint + []byte + free link = BigCache
- 定义 shards cache,避免锁粒度过大
- map 里只存放 uint 避免指针
- 实现一个 queue 结构(实际是[]byte,通过 uint 下标追加分配)
- 采用 free 链机制,删除保留空洞最后一起回收(这块逻辑还蛮复杂的,先留个不大不小的坑吧...)
其内存池定义如下:
- type cacheShard struct {
- hashmap map[uint64]uint32 // key在entries中的位置
- entries queue.BytesQueue // 实际是[]byte,新数据来了后copy到尾部
- }
这样 GC 就变成了map 无指针+[]byte 结构的扫描问题了,因此性能会高出很多。
坑 4: 两种方式(GroupCache 和 BigCache)对具体业务到底有多大影响?
上面只是 map 实现内存池的模拟分析,以及两种典型 Cache 库的对比。如果你也和我一样,问自己“具体两种 Cache 对业务有多大影响呢”?那只能很高兴的对你说:欢迎来到坑底 -_-
我们线上大概需要单机缓存 1000 万左右的 keys。首先我尝试模拟业务,向两种 Cache 中插入 1000w 数据来测试 GC 停顿。然而因为实验代码或其他未知的坑,最后认为这个方法不太可侧
最后讨论,觉得还是用老办法,用 Prometheus 的 histogram 统计耗时分布。我们先统计底层存储(Redis)的耗时分布,然后再分别统计 BigCache 和 GroupCache 在写入 500w 数据后的实际情况。分析结论可知:
40ms 以上请求
从 redis 数据看,40ms 以上请求占比0.08%;BigCache 的 40ms 以上请求占0.04%(即相反有一半以上超时请求被 Cache 挡住了) GroupCache 则是0.2%,将这种长时间请求放大了1倍多(推测和 map 的锁机制有关)
10ms-40ms 请求
redis 本身这个区间段请求占比24.11%;BigCache 则只有15.51%,相当于挡掉了33%左右的高延迟请求(证明加热点 Cache 还是有作用的) GroupCache 这个区间段请求占比21.55%,也比直接用 redis 来得好
详细数据分布:
- redis [ 0.1] 0.00%
- redis [ 0.5] 0.38%
- redis [ 1] 3.48%
- redis [ 5] 71.94%
- redis [ 10] 22.90%
- redis [ 20] 1.21%
- redis [ 40] 0.07%
- redis [ +Inf] 0.01%
- bigcache [ 0.1] 0.40%
- bigcache [ 0.5] 16.16%
- bigcache [ 1] 14.82%
- bigcache [ 5] 53.07%
- bigcache [ 10] 14.85%
- bigcache [ 20] 0.66%
- bigcache [ 40] 0.03%
- bigcache [ +Inf] 0.01%
- groupcache[ 0.1] 0.24%
- groupcache[ 0.5] 9.59%
- groupcache[ 1] 9.69%
- groupcache[ 5] 58.74%
- groupcache[ 10] 19.10%
- groupcache[ 20] 2.45%
- groupcache[ 40] 0.17%
- groupcache[ +Inf] 0.03%
然而我们测完只能大致知道:本地使用 GroupCache 在 500w 量级的 keys 下,还是不如 BigCache 稳定的(哪怕 GroupCache 实现了 LRU 淘汰,但实际上因为有 Hot/Main Cache 的存在,内存利用效率上不如 BigCache)
分布式情况下,GroupCache 和 BigCache 相比又有多少差距,这个就只能挖坑等大家一起跳了。
4. 对象池与零拷贝
在实际业务中,往往 map 中并不会存储 5000w 级的 keys。如果我们只有 50w 的 keys,GC 停顿就会骤减到 4ms 左右(其间 gc worker 还会并行工作,避免 STW)。
例如无极(腾讯内部的一个配置服务)这类配置服务(或其他高频数据查询场景),往往需要 Get(key) 获取对应的结构化数据。而从 BigCache,CPU 消耗发现(如图),相比网络 IO 和 Protobuf 解析,Get 占用0.78%、Set 占用0.9%,基本可以忽略:
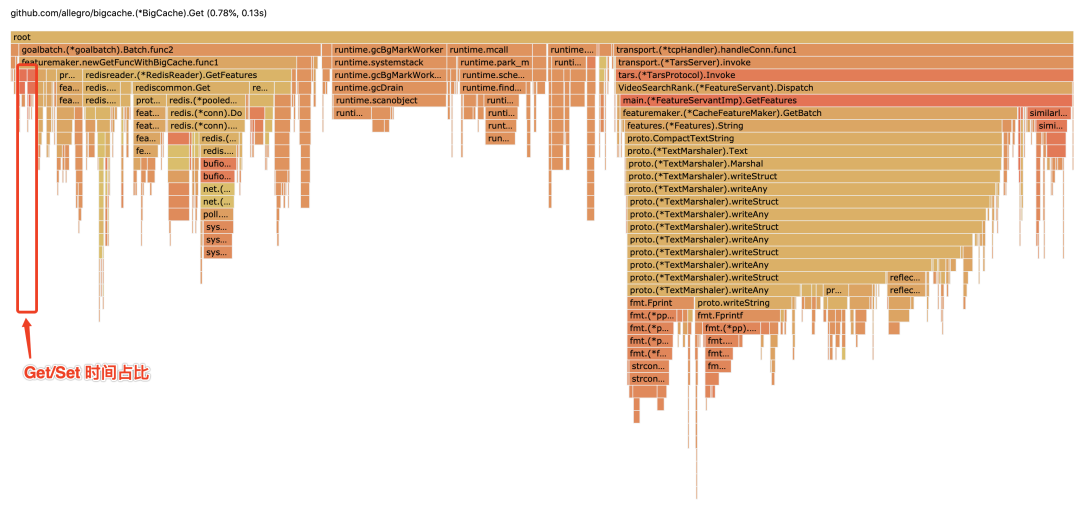
CPU profile
因此优化的思路也很明确,我们参考 GroupCache 的 lru 实现,将 JSON 提前解析好,在业务侧 Get 时直接返回 struct 的指针即可。具体流程不复杂,直接 ppt 截图:
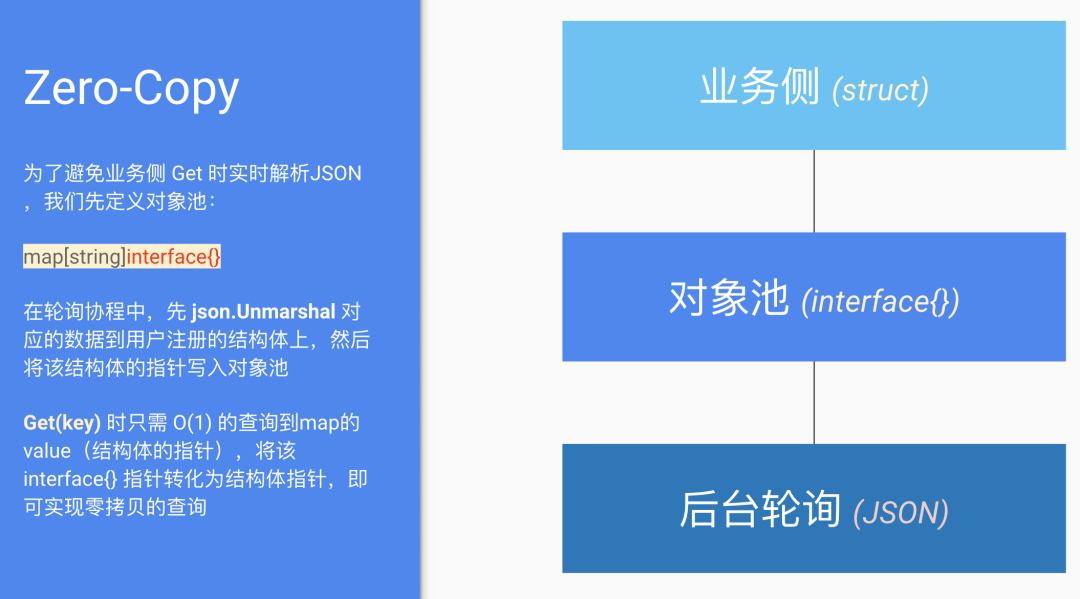
zero-copy
我们把接口设计成注册的方式(注册需要解析 JSON 数据的结构),然后再 Get 时返回该结构的指针实现零拷贝。下面 benchmark 可以反映性能差异和内存分配情况(Client_Get 是实时 JSON 解析,Filter_Get 是优化的对象池 API),可以切实看到0 allocs/op:
- goos: linux
- goarch: amd64
- pkg: open-wuji/go-sdk/wujiclient
- BenchmarkClient_Get-8 1000000 1154 ns/op 1.00 hits 87 B/op 3 allocs/op
- BenchmarkFilter_Get-8 4899364 302 ns/op 1.00 hits 7 B/op 1 allocs/op
- BenchmarkClient_GetParallel-8 8383149 162 ns/op 1.00 hits 80 B/op 2 allocs/op
- BenchmarkFilter_GetParallel-8 13053680 91.4 ns/op 1.00 hits 0 B/op 0 allocs/op
- PASS
- ok open-wuji/go-sdk/wujiclient 93.494s
- Success: Benchmarks passed.
目前无极尚未对外开源。对具体实现感兴趣的同学,可以看 gist 中filter API 的实现代码